A Deep-Dive into Flink's Network Stack
June 5, 2019 - Nico Kruber
Flink’s network stack is one of the core components that make up the flink-runtime module and sit at the heart of every Flink job. It connects individual work units (subtasks) from all TaskManagers. This is where your streamed-in data flows through and it is therefore crucial to the performance of your Flink job for both the throughput as well as latency you observe. In contrast to the coordination channels between TaskManagers and JobManagers which are using RPCs via Akka, the network stack between TaskManagers relies on a much lower-level API using Netty.
This blog post is the first in a series of posts about the network stack. In the sections below, we will first have a high-level look at what abstractions are exposed to the stream operators and then go into detail on the physical implementation and various optimisations Flink did. We will briefly present the result of these optimisations and Flink’s trade-off between throughput and latency. Future blog posts in this series will elaborate more on monitoring and metrics, tuning parameters, and common anti-patterns.
Logical View #
Flink’s network stack provides the following logical view to the subtasks when communicating with each other, for example during a network shuffle as required by a keyBy().
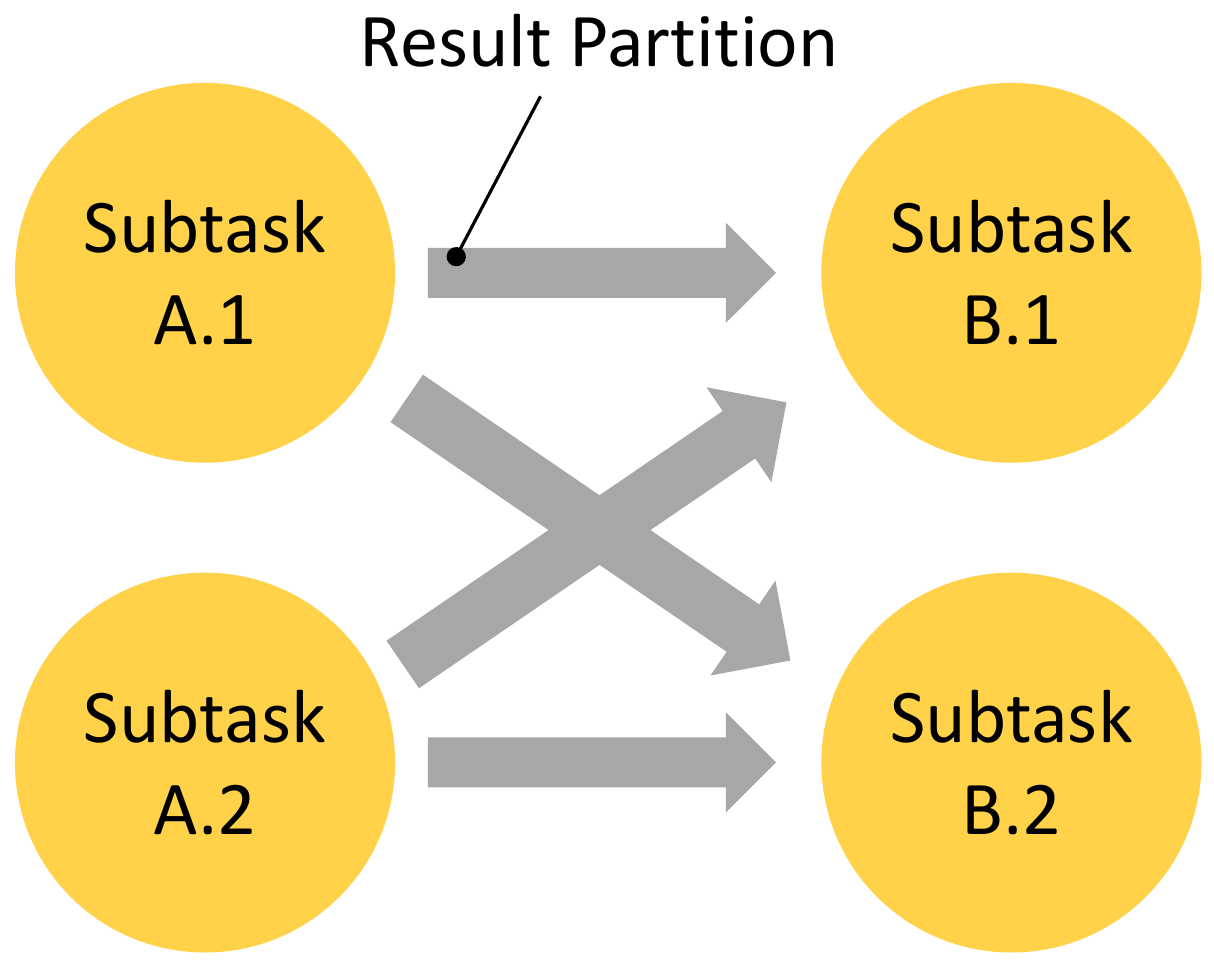
It abstracts over the different settings of the following three concepts:
-
Subtask output type (
ResultPartitionType):- pipelined (bounded or unbounded): Sending data downstream as soon as it is produced, potentially one-by-one, either as a bounded or unbounded stream of records.
- blocking: Sending data downstream only when the full result was produced.
-
Scheduling type:
- all at once (eager): Deploy all subtasks of the job at the same time (for streaming applications).
- next stage on first output (lazy): Deploy downstream tasks as soon as any of their producers generated output.
- next stage on complete output: Deploy downstream tasks when any or all of their producers have generated their full output set.
-
Transport:
- high throughput: Instead of sending each record one-by-one, Flink buffers a bunch of records into its network buffers and sends them altogether. This reduces the costs per record and leads to higher throughput.
- low latency via buffer timeout: By reducing the timeout of sending an incompletely filled buffer, you may sacrifice throughput for latency.
We will have a look at the throughput and low latency optimisations in the sections below which look at the physical layers of the network stack. For this part, let us elaborate a bit more on the output and scheduling types. First of all, it is important to know that the subtask output type and the scheduling type are closely intertwined making only specific combinations of the two valid.
Pipelined result partitions are streaming-style outputs which need a live target subtask to send data to. The target can be scheduled before results are produced or at first output. Batch jobs produce bounded result partitions while streaming jobs produce unbounded results.
Batch jobs may also produce results in a blocking fashion, depending on the operator and connection pattern that is used. In that case, the complete result must be produced first before the receiving task can be scheduled. This allows batch jobs to work more efficiently and with lower resource usage.
The following table summarises the valid combinations:
| Output Type | Scheduling Type | Applies to… |
|---|---|---|
| pipelined, unbounded | all at once | Streaming jobs |
| next stage on first output | n/a¹ | |
| pipelined, bounded | all at once | n/a² |
| next stage on first output | Batch jobs | |
| blocking | next stage on complete output | Batch jobs |
1 Currently not used by Flink.
2 This may become applicable to streaming jobs once the Batch/Streaming unification is done.
Additionally, for subtasks with more than one input, scheduling start in two ways: after *all* or after *any* input producers to have produced a record/their complete dataset. For tuning the output types and scheduling decisions in batch jobs, please have a look at [ExecutionConfig#setExecutionMode()](//nightlies.apache.org/flink/flink-docs-release-1.8/api/java/org/apache/flink/api/common/ExecutionConfig.html#setExecutionMode-org.apache.flink.api.common.ExecutionMode-) - and [ExecutionMode](//nightlies.apache.org/flink/flink-docs-release-1.8/api/java/org/apache/flink/api/common/ExecutionMode.html#enum.constant.detail) in particular - as well as [ExecutionConfig#setDefaultInputDependencyConstraint()](//nightlies.apache.org/flink/flink-docs-release-1.8/api/java/org/apache/flink/api/common/ExecutionConfig.html#setDefaultInputDependencyConstraint-org.apache.flink.api.common.InputDependencyConstraint-).
Physical Transport #
In order to understand the physical data connections, please recall that, in Flink, different tasks may share the same slot via slot sharing groups. TaskManagers may also provide more than one slot to allow multiple subtasks of the same task to be scheduled onto the same TaskManager.
For the example pictured below, we will assume a parallelism of 4 and a deployment with two task managers offering 2 slots each. TaskManager 1 executes subtasks A.1, A.2, B.1, and B.2 and TaskManager 2 executes subtasks A.3, A.4, B.3, and B.4. In a shuffle-type connection between task A and task B, for example from a keyBy(), there are 2x4 logical connections to handle on each TaskManager, some of which are local, some remote:
| B.1 | B.2 | B.3 | B.4 | |
|---|---|---|---|---|
| A.1 | local | remote | ||
| A.2 | ||||
| A.3 | remote | local | ||
| A.4 | ||||
Each (remote) network connection between different tasks will get its own TCP channel in Flink’s network stack. However, if different subtasks of the same task are scheduled onto the same TaskManager, their network connections towards the same TaskManagers will be multiplexed and share a single TCP channel for reduced resource usage. In our example, this would apply to A.1 → B.3, A.1 → B.4, as well as A.2 → B.3, and A.2 → B.4 as pictured below:
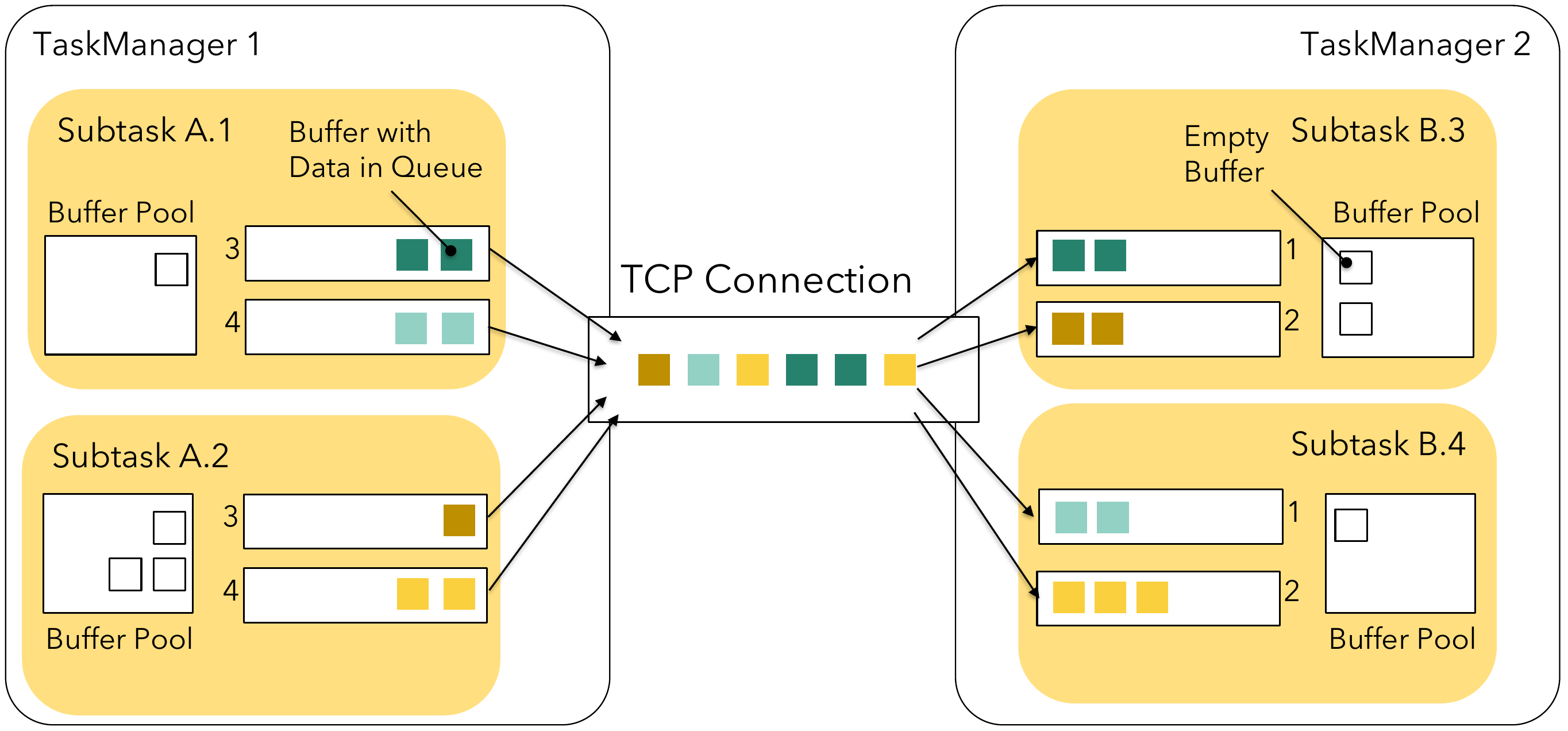
The results of each subtask are called ResultPartition, each split into separate ResultSubpartitions — one for each logical channel. At this point in the stack, Flink is not dealing with individual records anymore but instead with a group of serialised records assembled together into network buffers. The number of buffers available to each subtask in its own local buffer pool (one per sending and receiving side each) is limited to at most
#channels * buffers-per-channel + floating-buffers-per-gate
The total number of buffers on a single TaskManager usually does not need configuration. See the Configuring the Network Buffers documentation for details on how to do so if needed.
Inflicting Backpressure (1) #
Whenever a subtask’s sending buffer pool is exhausted — buffers reside in either a result subpartition’s buffer queue or inside the lower, Netty-backed network stack — the producer is blocked, cannot continue, and experiences backpressure. The receiver works in a similar fashion: any incoming Netty buffer in the lower network stack needs to be made available to Flink via a network buffer. If there is no network buffer available in the appropriate subtask’s buffer pool, Flink will stop reading from this channel until a buffer becomes available. This would effectively backpressure all sending subtasks on this multiplex and therefore also throttle other receiving subtasks. The following picture illustrates this for an overloaded subtask B.4 which would cause backpressure on the multiplex and also stop subtask B.3 from receiving and processing further buffers, even though it still has capacity.
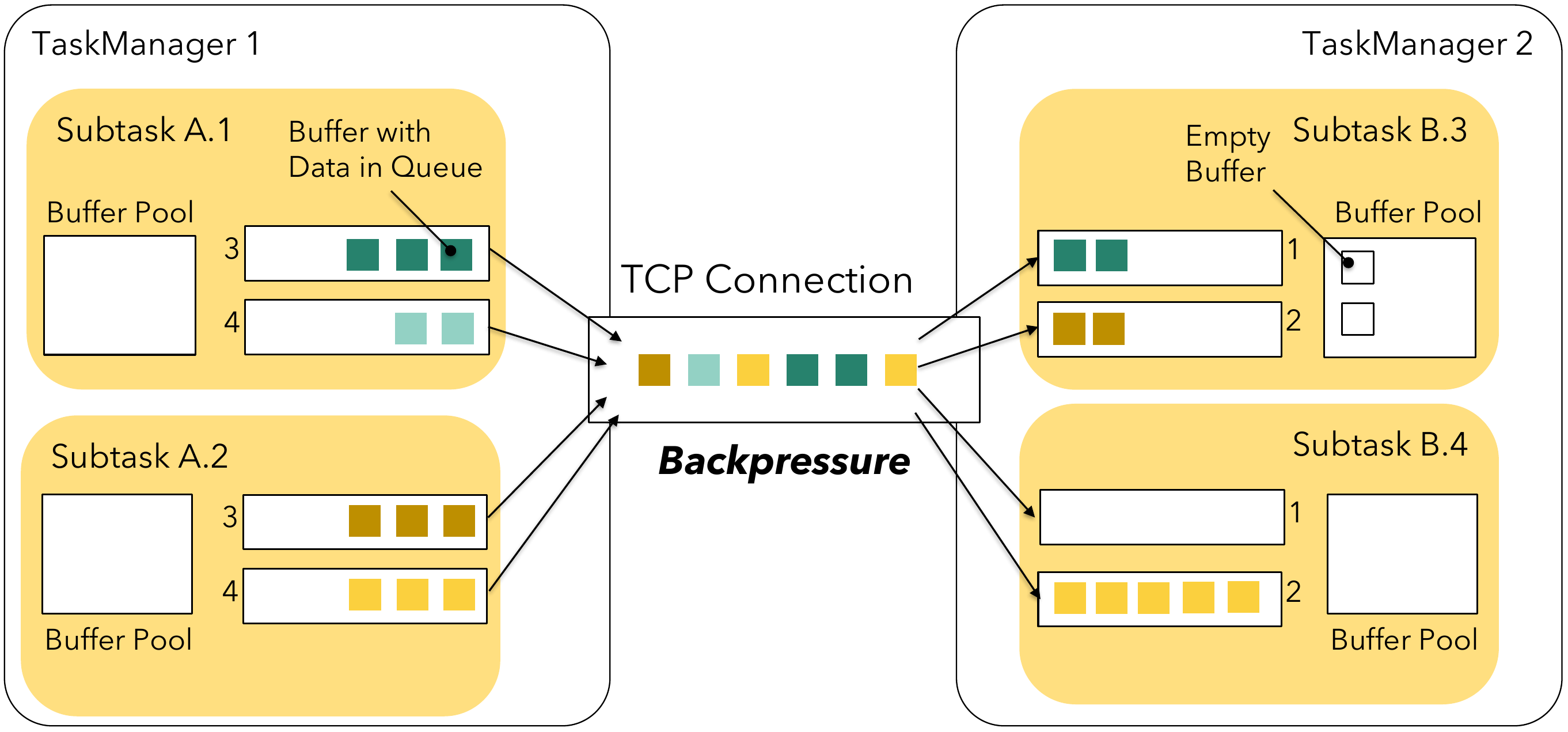
To prevent this situation from even happening, Flink 1.5 introduced its own flow control mechanism.
Credit-based Flow Control #
Credit-based flow control makes sure that whatever is “on the wire” will have capacity at the receiver to handle. It is based on the availability of network buffers as a natural extension of the mechanisms Flink had before. Instead of only having a shared local buffer pool, each remote input channel now has its own set of exclusive buffers. Conversely, buffers in the local buffer pool are called floating buffers as they will float around and are available to every input channel.
Receivers will announce the availability of buffers as credits to the sender (1 buffer = 1 credit). Each result subpartition will keep track of its channel credits. Buffers are only forwarded to the lower network stack if credit is available and each sent buffer reduces the credit score by one. In addition to the buffers, we also send information about the current backlog size which specifies how many buffers are waiting in this subpartition’s queue. The receiver will use this to ask for an appropriate number of floating buffers for faster backlog processing. It will try to acquire as many floating buffers as the backlog size but this may not always be possible and we may get some or no buffers at all. The receiver will make use of the retrieved buffers and will listen for further buffers becoming available to continue.
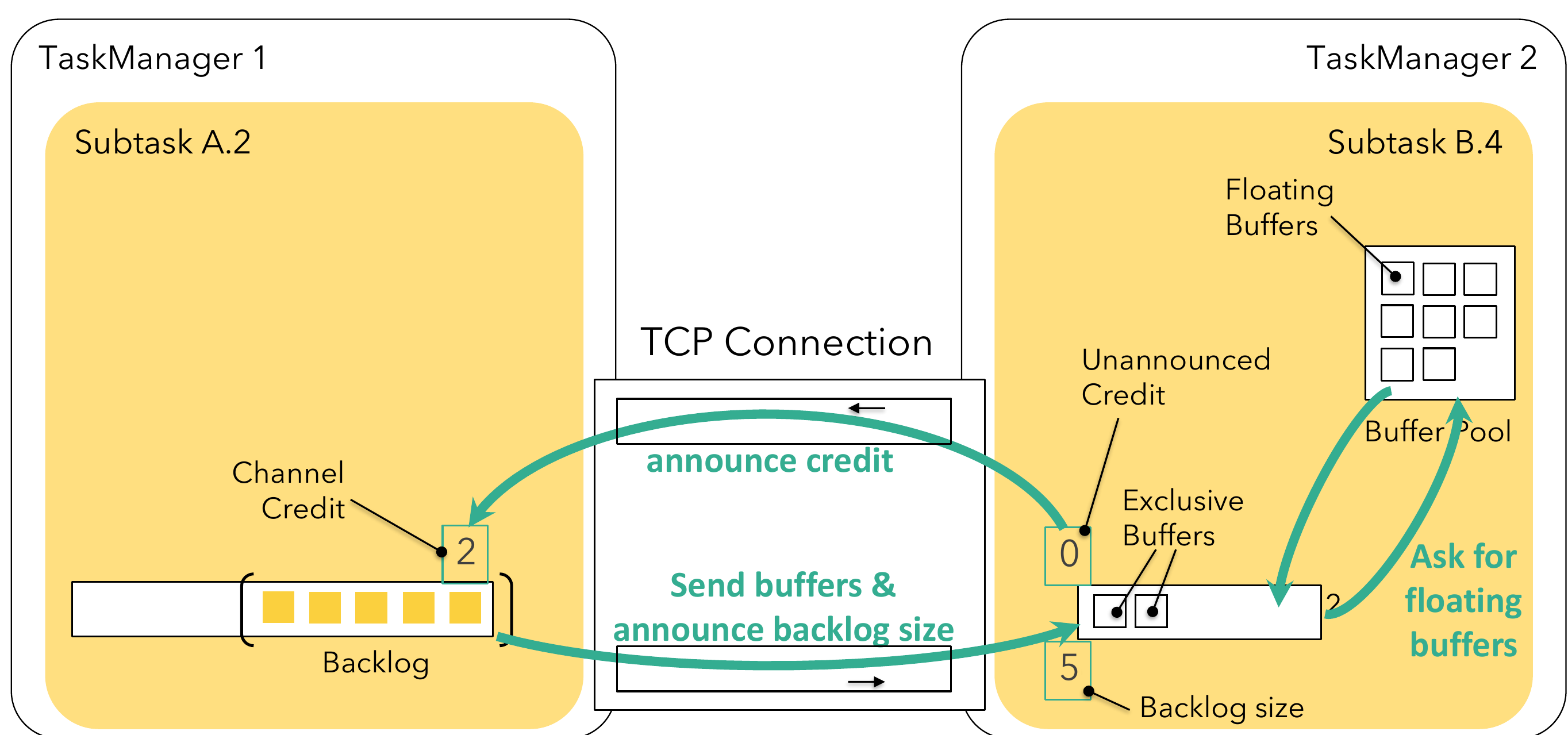
Credit-based flow control will use buffers-per-channel to specify how many buffers are exclusive (mandatory) and floating-buffers-per-gate for the local buffer pool (optional3) thus achieving the same buffer limit as without flow control. The default values for these two parameters have been chosen so that the maximum (theoretical) throughput with flow control is at least as good as without flow control, given a healthy network with usual latencies. You may need to adjust these depending on your actual round-trip-time and bandwidth.
3If there are not enough buffers available, each buffer pool will get the same share of the globally available ones (± 1).
Inflicting Backpressure (2) #
As opposed to the receiver’s backpressure mechanisms without flow control, credits provide a more direct control: If a receiver cannot keep up, its available credits will eventually hit 0 and stop the sender from forwarding buffers to the lower network stack. There is backpressure on this logical channel only and there is no need to block reading from a multiplexed TCP channel. Other receivers are therefore not affected in processing available buffers.
What do we Gain? Where is the Catch? #
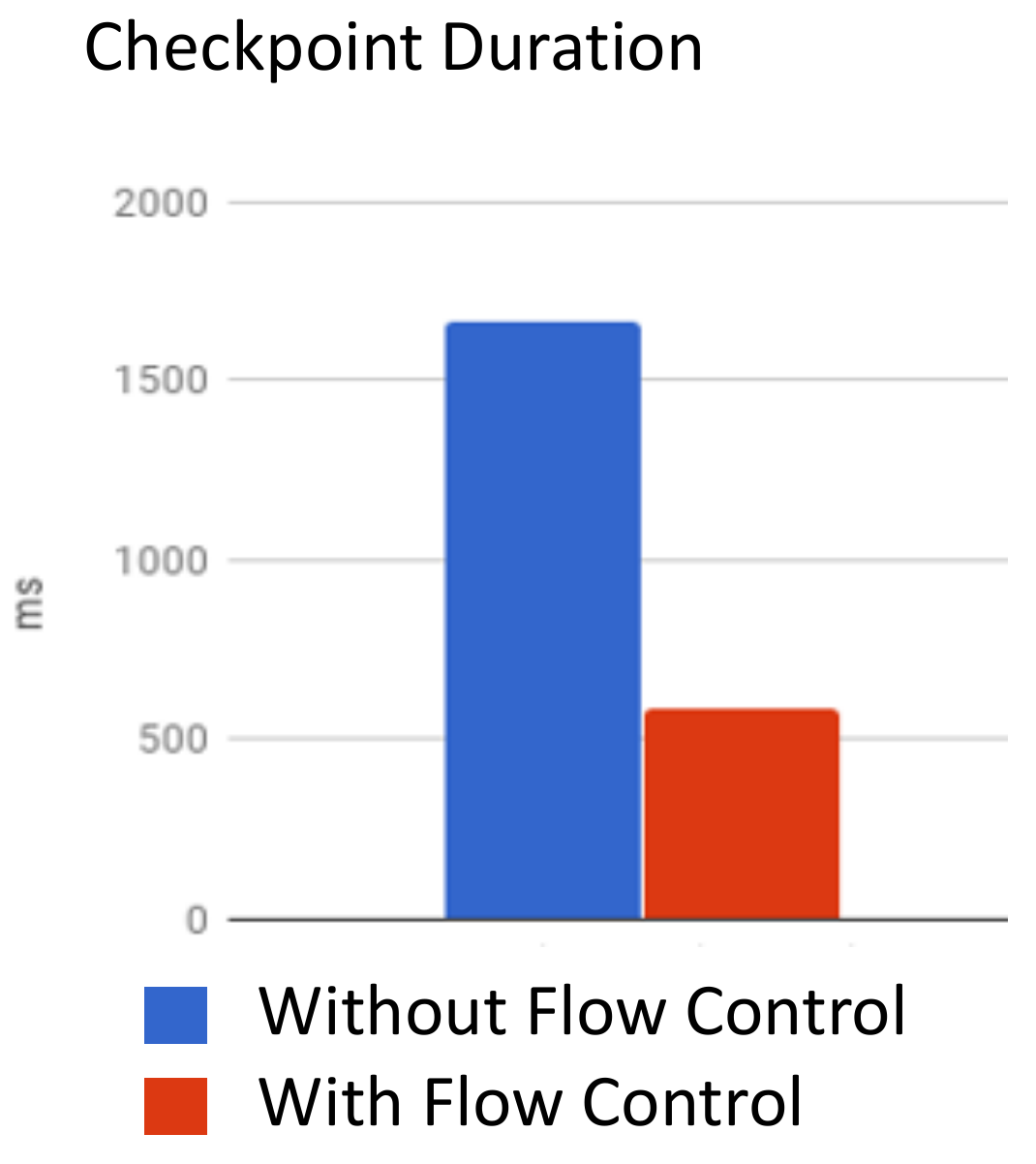
Since, with flow control, a channel in a multiplex cannot block another of its logical channels, the overall resource utilisation should increase. In addition, by having full control over how much data is “on the wire”, we are also able to improve checkpoint alignments: without flow control, it would take a while for the channel to fill the network stack’s internal buffers and propagate that the receiver is not reading anymore. During that time, a lot of buffers could be sitting around. Any checkpoint barrier would have to queue up behind these buffers and would thus have to wait until all of those have been processed before it can start (“Barriers never overtake records!”).
However, the additional announce messages from the receiver may come at some additional costs, especially in setup using SSL-encrypted channels. Also, a single input channel cannot make use of all buffers in the buffer pool because exclusive buffers are not shared. It can also not start right away with sending as much data as is available so that during ramp-up (if you are producing data faster than announcing credits in return) it may take longer to send data through. While this may affect your job’s performance, it is usually better to have flow control because of all its advantages. You may want to increase the number of exclusive buffers via buffers-per-channel at the cost of using more memory. The overall memory use compared to the previous implementation, however, may still be lower because lower network stacks do not need to buffer much data any more since we can always transfer that to Flink immediately.
There is one more thing you may notice when using credit-based flow control: since we buffer less data between the sender and receiver, you may experience backpressure earlier. This is, however, desired and you do not really get any advantage by buffering more data. If you want to buffer more but keep flow control, you could consider increasing the number of floating buffers via floating-buffers-per-gate.
| Advantages | Disadvantages |
|---|---|
|
• better resource utilisation with data skew in multiplexed connections • improved checkpoint alignment • reduced memory use (less data in lower network layers) |
• additional credit-announce messages • additional backlog-announce messages (piggy-backed with buffer messages, almost no overhead) • potential round-trip latency |
| • backpressure appears earlier | |
taskmanager.network.credit-model: false
This parameter, however, is deprecated and will eventually be removed along with the non-credit-based flow control code.
Writing Records into Network Buffers and Reading them again #
The following picture extends the slightly more high-level view from above with further details of the network stack and its surrounding components, from the collection of a record in your sending operator to the receiving operator getting it:
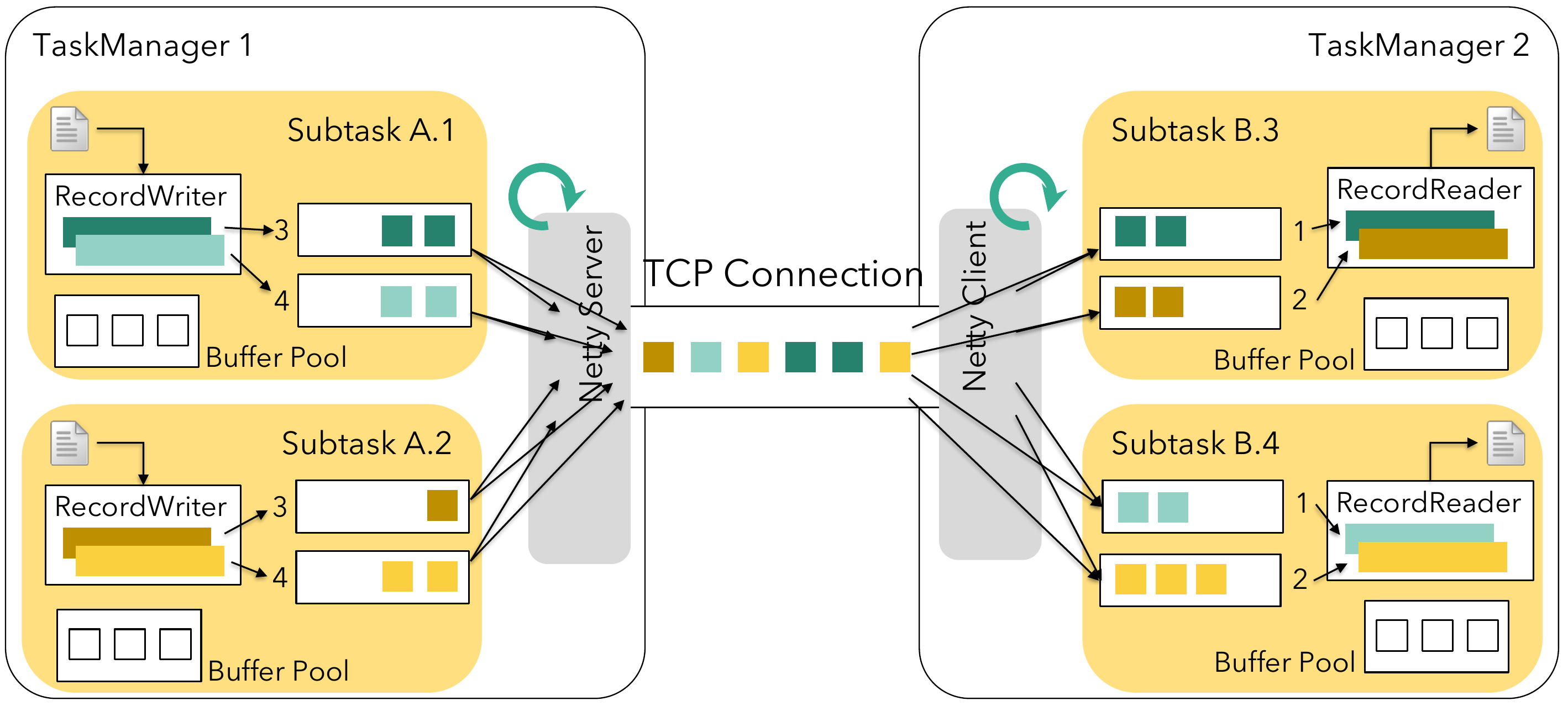
After creating a record and passing it along, for example via Collector#collect(), it is given to the RecordWriter which serialises the record from a Java object into a sequence of bytes which eventually ends up in a network buffer that is handed along as described above. The RecordWriter first serialises the record to a flexible on-heap byte array using the SpanningRecordSerializer. Afterwards, it tries to write these bytes into the associated network buffer of the target network channel. We will come back to this last part in the section below.
On the receiver’s side, the lower network stack (netty) is writing received buffers into the appropriate input channels. The (stream) tasks’s thread eventually reads from these queues and tries to deserialise the accumulated bytes into Java objects with the help of the RecordReader and going through the SpillingAdaptiveSpanningRecordDeserializer. Similar to the serialiser, this deserialiser must also deal with special cases like records spanning multiple network buffers, either because the record is just bigger than a network buffer (32KiB by default, set via taskmanager.memory.segment-size) or because the serialised record was added to a network buffer which did not have enough remaining bytes. Flink will nevertheless use these bytes and continue writing the rest to a new network buffer.
Flushing Buffers to Netty #
In the picture above, the credit-based flow control mechanics actually sit inside the “Netty Server” (and “Netty Client”) components and the buffer the RecordWriter is writing to is always added to the result subpartition in an empty state and then gradually filled with (serialised) records. But when does Netty actually get the buffer? Obviously, it cannot take bytes whenever they become available since that would not only add substantial costs due to cross-thread communication and synchronisation, but also make the whole buffering obsolete.
In Flink, there are three situations that make a buffer available for consumption by the Netty server:
- a buffer becomes full when writing a record to it, or
- the buffer timeout hits, or
- a special event such as a checkpoint barrier is sent.
Flush after Buffer Full #
The RecordWriter works with a local serialisation buffer for the current record and will gradually write these bytes to one or more network buffers sitting at the appropriate result subpartition queue. Although a RecordWriter can work on multiple subpartitions, each subpartition has only one RecordWriter writing data to it. The Netty server, on the other hand, is reading from multiple result subpartitions and multiplexing the appropriate ones into a single channel as described above. This is a classical producer-consumer pattern with the network buffers in the middle and as shown by the next picture. After (1) serialising and (2) writing data to the buffer, the RecordWriter updates the buffer’s writer index accordingly. Once the buffer is completely filled, the record writer will (3) acquire a new buffer from its local buffer pool for any remaining bytes of the current record - or for the next one - and add the new one to the subpartition queue. This will (4) notify the Netty server of data being available if it is not aware yet4. Whenever Netty has capacity to handle this notification, it will (5) take the buffer and send it along the appropriate TCP channel.
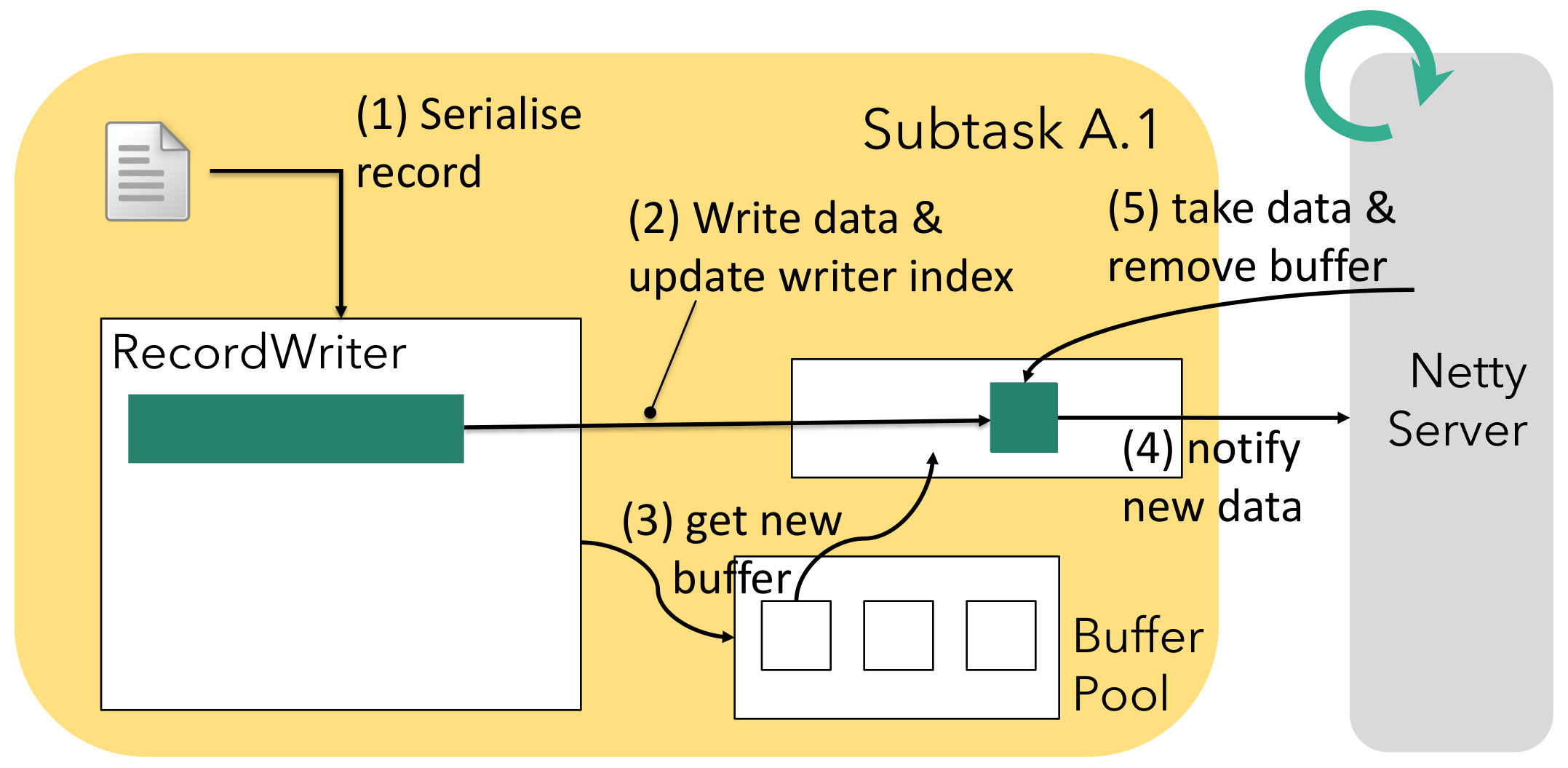
4We can assume it already got the notification if there are more finished buffers in the queue.
Flush after Buffer Timeout #
In order to support low-latency use cases, we cannot only rely on buffers being full in order to send data downstream. There may be cases where a certain communication channel does not have too many records flowing through and unnecessarily increase the latency of the few records you actually have. Therefore, a periodic process will flush whatever data is available down the stack: the output flusher. The periodic interval can be configured via StreamExecutionEnvironment#setBufferTimeout and acts as an upper bound on the latency5 (for low-throughput channels). The following picture shows how it interacts with the other components: the RecordWriter serialises and writes into network buffers as before but concurrently, the output flusher may (3,4) notify the Netty server of data being available if Netty is not already aware (similar to the “buffer full” scenario above). When Netty handles this notification (5) it will consume the available data from the buffer and update the buffer’s reader index. The buffer stays in the queue - any further operation on this buffer from the Netty server side will continue reading from the reader index next time.
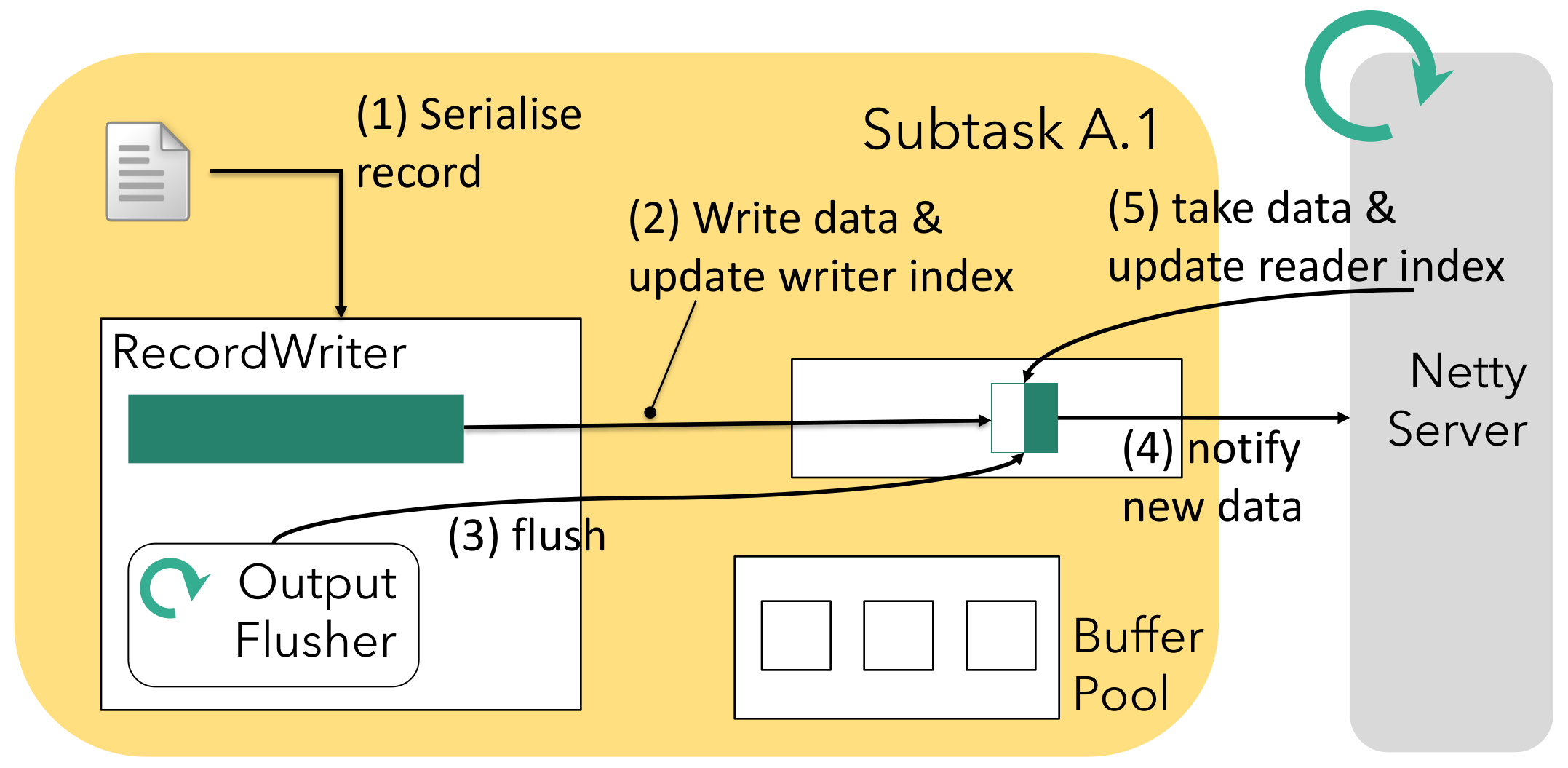
5Strictly speaking, the output flusher does not give any guarantees - it only sends a notification to Netty which can pick it up at will / capacity. This also means that the output flusher has no effect if the channel is backpressured.
Flush after special event #
Some special events also trigger immediate flushes if being sent through the RecordWriter. The most important ones are checkpoint barriers or end-of-partition events which obviously should go quickly and not wait for the output flusher to kick in.
Further remarks #
In contrast to Flink < 1.5, please note that (a) network buffers are now placed in the subpartition queues directly and (b) we are not closing the buffer on each flush. This gives us a few advantages:
- less synchronisation overhead (output flusher and RecordWriter are independent)
- in high-load scenarios where Netty is the bottleneck (either through backpressure or directly), we can still accumulate data in incomplete buffers
- significant reduction of Netty notifications
However, you may notice an increased CPU use and TCP packet rate during low load scenarios. This is because, with the changes, Flink will use any available CPU cycles to try to maintain the desired latency. Once the load increases, this will self-adjust by buffers filling up more. High load scenarios are not affected and even get a better throughput because of the reduced synchronisation overhead.
Buffer Builder & Buffer Consumer #
If you want to dig deeper into how the producer-consumer mechanics are implemented in Flink, please take a closer look at the BufferBuilder and BufferConsumer classes which have been introduced in Flink 1.5. While reading is potentially only per buffer, writing to it is per record and thus on the hot path for all network communication in Flink. Therefore, it was very clear to us that we needed a lightweight connection between the task’s thread and the Netty thread which does not imply too much synchronisation overhead. For further details, we suggest to check out the source code.
Latency vs. Throughput #
Network buffers were introduced to get higher resource utilisation and higher throughput at the cost of having some records wait in buffers a little longer. Although an upper limit to this wait time can be given via the buffer timeout, you may be curious to find out more about the trade-off between these two dimensions: latency and throughput, as, obviously, you cannot get both. The following plot shows various values for the buffer timeout starting at 0 (flush with every record) to 100ms (the default) and shows the resulting throughput rates on a cluster with 100 nodes and 8 slots each running a job that has no business logic and thus only tests the network stack. For comparison, we also plot Flink 1.4 before the low-latency improvements (as described above) were added.
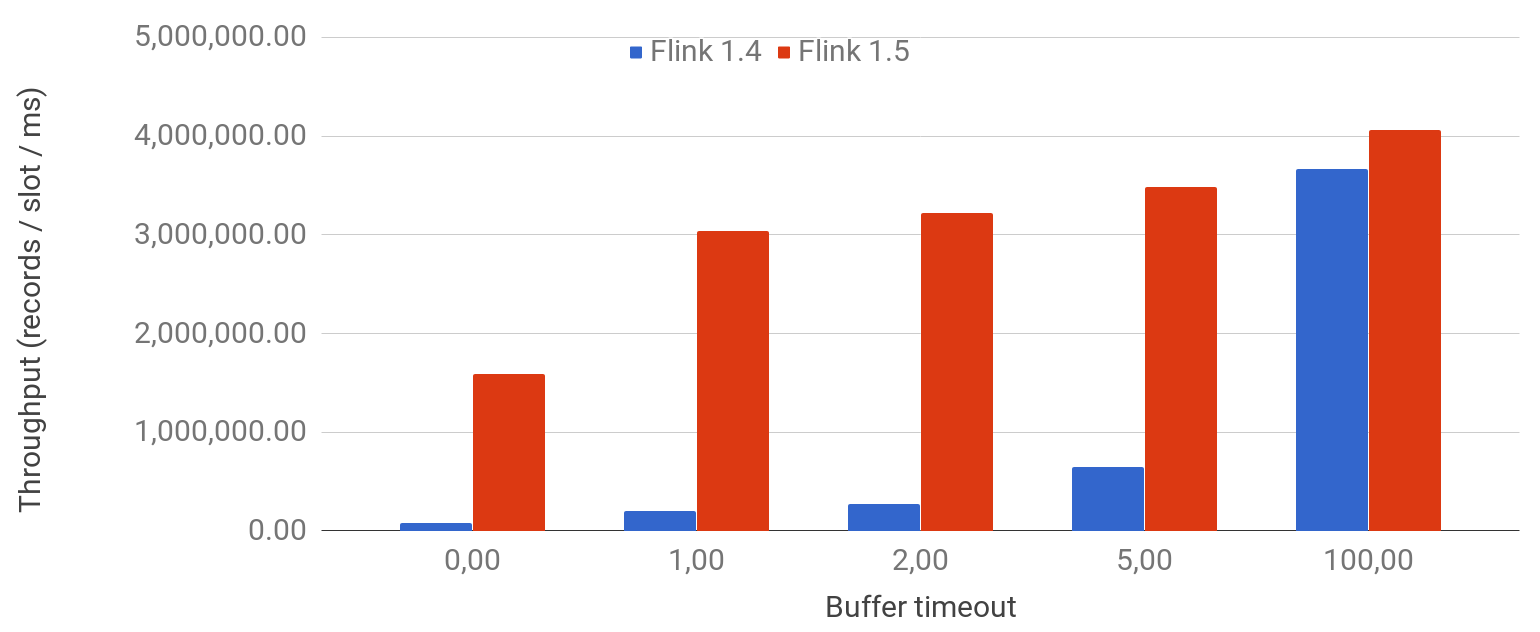
As you can see, with Flink 1.5+, even very low buffer timeouts such as 1ms (for low-latency scenarios) provide a maximum throughput as high as 75% of the default timeout where more data is buffered before being sent over the wire.
Conclusion #
Now you know about result partitions, the different network connections and scheduling types for both batch and streaming. You also know about credit-based flow control and how the network stack works internally, in order to reason about network-related tuning parameters and about certain job behaviours. Future blog posts in this series will build upon this knowledge and go into more operational details including relevant metrics to look at, further network stack tuning, and common antipatterns to avoid. Stay tuned for more.