How to natively deploy Flink on Kubernetes with High-Availability (HA)
February 10, 2021 - Yang WangFlink has supported resource management systems like YARN and Mesos since the early days; however, these were not designed for the fast-moving cloud-native architectures that are increasingly gaining popularity these days, or the growing need to support complex, mixed workloads (e.g. batch, streaming, deep learning, web services). For these reasons, more and more users are using Kubernetes to automate the deployment, scaling and management of their Flink applications.
From release to release, the Flink community has made significant progress in integrating natively with Kubernetes, from active resource management to “Zookeeperless” High Availability (HA). In this blogpost, we’ll recap the technical details of deploying Flink applications natively on Kubernetes, diving deeper into Flink’s Kubernetes HA architecture. We’ll then walk you through a hands-on example of running a Flink application cluster on Kubernetes with HA enabled. We’ll end with a conclusion covering the advantages of running Flink natively on Kubernetes, and an outlook into future work.
Native Flink on Kubernetes Integration #
Before we dive into the technical details of how the Kubernetes-based HA service works, let us briefly explain what native means in the context of Flink deployments on Kubernetes:
-
Flink is self-contained. There will be an embedded Kubernetes client in the Flink client, and so you will not need other external tools (e.g. kubectl, Kubernetes dashboard) to create a Flink cluster on Kubernetes.
-
The Flink client will contact the Kubernetes API server directly to create the JobManager deployment. The configuration located on the client side will be shipped to the JobManager pod, as well as the log4j and Hadoop configurations.
-
Flink’s ResourceManager will talk to the Kubernetes API server to allocate and release the TaskManager pods dynamically on-demand.
All in all, this is similar to how Flink integrates with other resource management systems (e.g. YARN, Mesos), so it should be somewhat straightforward to integrate with Kubernetes if you’ve managed such deployments before — and especially if you already had some internal deployer for the lifecycle management of multiple Flink jobs.
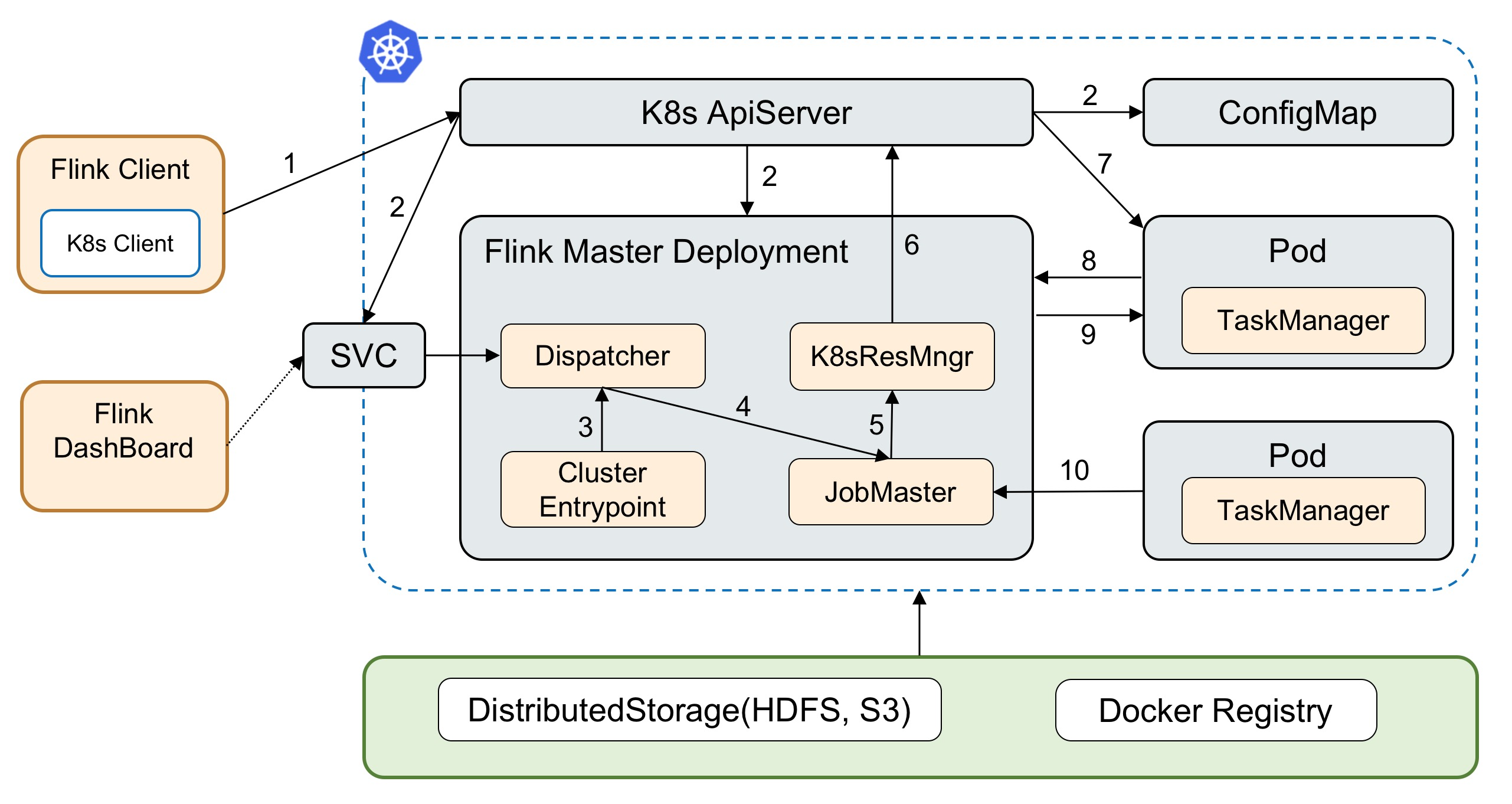
Fig. 1: Architecture of Flink's native Kubernetes integration.
Kubernetes High Availability Service #
High Availability (HA) is a common requirement when bringing Flink to production: it helps prevent a single point of failure for Flink clusters. Previous to the 1.12 release, Flink has provided a Zookeeper HA service that has been widely used in production setups and that can be integrated in standalone cluster, YARN, or Kubernetes deployments. However, managing a Zookeeper cluster on Kubernetes for HA would require an additional operational cost that could be avoided because, in the end, Kubernetes also provides some public APIs for leader election and configuration storage (i.e. ConfigMap). From Flink 1.12, we leverage these features to make running a HA-configured Flink cluster on Kubernetes more convenient to users.
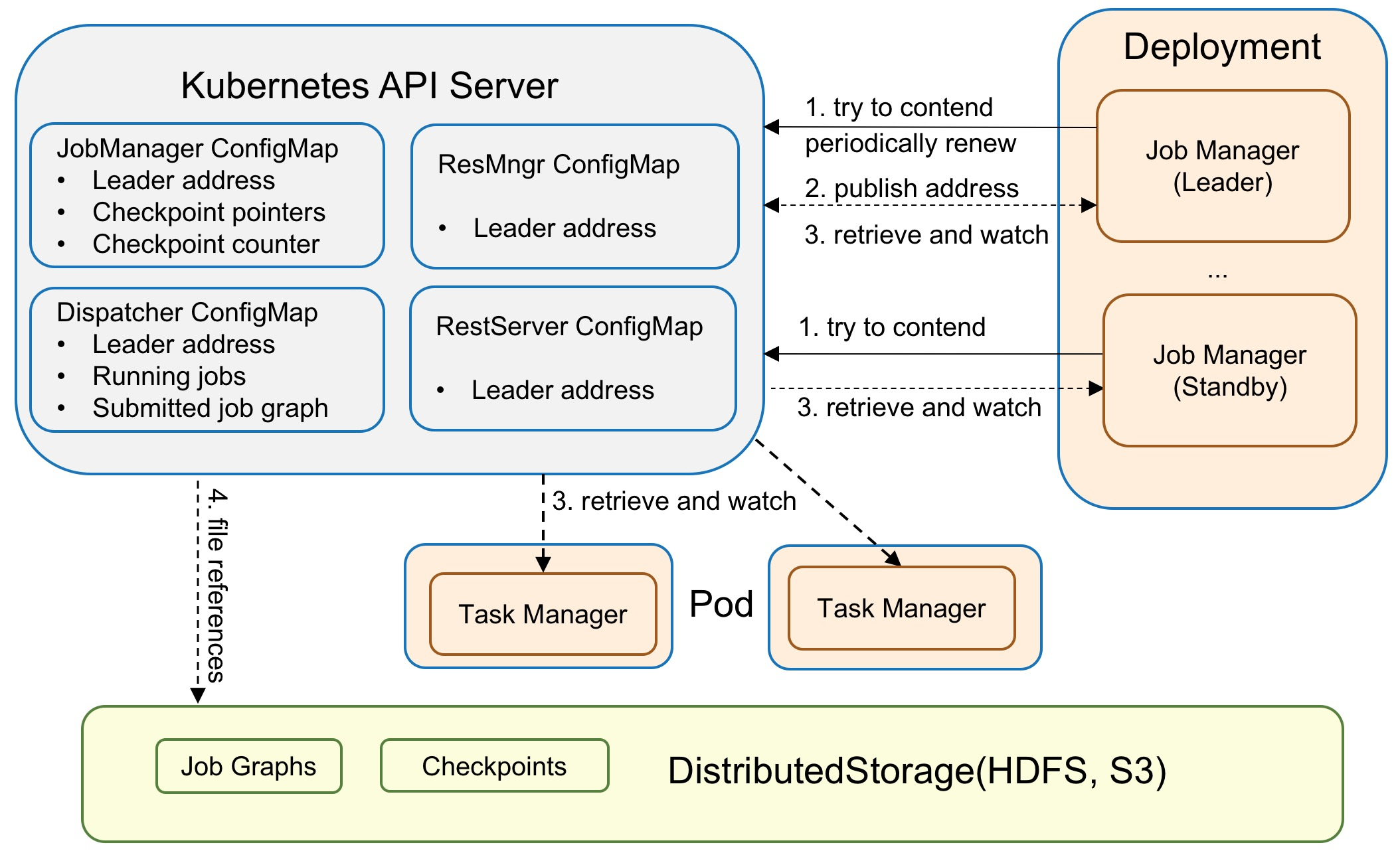
Fig. 2: Architecture of Flink's Kubernetes High Availability (HA) service.
The above diagram shows the architecture of Flink’s Kubernetes HA service, which works as follows:
-
For the leader election, a set of eligible JobManagers is identified. They all race to declare themselves as the leader, with one eventually becoming the active leader. The active JobManager then continually “heartbeats” to renew its position as the leader. In the meantime, all other standby JobManagers periodically make new attempts to become the leader — this ensures that the JobManager could failover quickly. Different components (e.g. ResourceManager, JobManager, Dispatcher, RestEndpoint) have separate leader election services and ConfigMaps.
-
The active leader publishes its address to the ConfigMap. It’s important to note that Flink will use the same ConfigMap for contending lock and storing the leader address. This ensures that there is no unexpected change snuck in during a periodic update.
-
The leader retrieval service is used to find the active leader’s address and allow the components to then register themselves. For example, TaskManagers retrieve the address of ResourceManager and JobManager for registration and to offer slots. Flink uses a Kubernetes watch in the leader retrieval service — once the content of ConfigMap changes, it usually means that the leader has changed, and so the listener can get the latest leader address immediately.
-
All other meta information (e.g. running jobs, job graphs, completed checkpoints and checkpointer counter) will be directly stored in the corresponding ConfigMaps. Only the leader can update the ConfigMap. The HA data will only be cleaned up once the Flink cluster reaches the global terminal state. Please note that only the pointers are stored in the ConfigMap; the concrete data will be stored in the DistributedStorage. This level of indirection is necessary to keep the amount of data in ConfigMap small (ConfigMap is built for data less than 1MB whereas state can grow to multiple GBs).
Example: Application Cluster with HA #
You’ll need a running Kubernetes cluster and to get kubeconfig properly set to follow along.
You can use kubectl get nodes to verify that you’re all set!
In this blog post, we’re using minikube for local testing.
1. Build a Docker image with the Flink job (my-flink-job.jar) baked in
FROM flink:1.12.1
RUN mkdir -p $FLINK_HOME/usrlib
COPY /path/of/my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
Use the above Dockerfile to build a user image (<user-image>) and then push it to your remote image repository:
$ docker build -t <user-image> .
$ docker push <user-image>
**2. Start a Flink Application Cluster**
$ ./bin/flink run-application \
--detached \
--parallelism 4 \
--target kubernetes-application \
-Dkubernetes.cluster-id=k8s-ha-app-1 \
-Dkubernetes.container.image=<user-image> \
-Dkubernetes.jobmanager.cpu=0.5 \
-Dkubernetes.taskmanager.cpu=0.5 \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dkubernetes.rest-service.exposed.type=NodePort \
-Dhigh-availability=org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory \
-Dhigh-availability.storageDir=s3://flink-bucket/flink-ha \
-Drestart-strategy=fixed-delay \
-Drestart-strategy.fixed-delay.attempts=10 \
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.12.1.jar \
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.12.1.jar \
local:///opt/flink/usrlib/my-flink-job.jar
**3. Access the Flink Web UI** (http://minikube-ip-address:node-port) **and check that the job is running!**
2021-02-05 17:26:13,403 INFO org.apache.flink.kubernetes.KubernetesClusterDescriptor [] - Create flink application cluster k8s-ha-app-1 successfully, JobManager Web Interface: http://192.168.64.21:32388
You should be able to find a similar log in the Flink client and get the JobManager web interface URL.
**4. Kill the JobManager to simulate failure**
$ kubectl exec {jobmanager_pod_name} -- /bin/sh -c "kill 1"
**5. Verify that the job recovers from the latest successful checkpoint**
Refresh the Flink Web UI until the new JobManager is launched, and then search for the following JobManager logs to verify that the job recovers from the latest successful checkpoint:
2021-02-05 09:44:01,636 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Restoring job 00000000000000000000000000000000 from Checkpoint 101 @ 1612518074802 for 00000000000000000000000000000000 located at <checkpoint-not-externally-addressable>.
**6. Cancel the job**
The job can be cancelled through the Flink the Web UI, or using the following command:
$ ./bin/flink cancel --target kubernetes-application -Dkubernetes.cluster-id=<ClusterID> <JobID>
When the job is cancelled, all the Kubernetes resources created by Flink (e.g. JobManager deployment, TaskManager pods, service, Flink configuration ConfigMap, leader-related ConfigMaps) will be deleted automatically.
Conclusion #
The native Kubernetes integration was first introduced in Flink 1.10, abstracting a lot of the complexities of hosting, configuring, managing and operating Flink clusters in cloud-native environments. After three major releases, the community has made great progress in supporting multiple deployment modes (i.e. session and application) and an alternative HA setup that doesn’t depend on Zookeeper.
Compared with standalone Kubernetes deployments, the native integration is more user-friendly and requires less upfront knowledge about Kubernetes. Given that Flink is now aware of the underlying Kubernetes cluster, it also can benefit from dynamic resource allocation and make more efficient use of Kubernetes cluster resources. The next building block to deepen Flink’s native integration with Kubernetes is the pod template (FLINK-15656), which will greatly enhance the flexibility of using advanced Kubernetes features (e.g. volumes, init container, sidecar container). This work is already in progress and will be added in the upcoming 1.13 release!