Adaptive Batch Scheduler: Automatically Decide Parallelism of Flink Batch Jobs
June 17, 2022 - Lijie Wang Zhu ZhuIntroduction #
Deciding proper parallelisms of operators is not an easy work for many users. For batch jobs, a small parallelism may result in long execution time and big failover regression. While an unnecessary large parallelism may result in resource waste and more overhead cost in task deployment and network shuffling.
To decide a proper parallelism, one needs to know how much data each operator needs to process. However, It can be hard to predict data volume to be processed by a job because it can be different everyday. And it can be harder or even impossible (due to complex operators or UDFs) to predict data volume to be processed by each operator.
To solve this problem, we introduced the adaptive batch scheduler in Flink 1.15. The adaptive batch scheduler can automatically decide parallelism of an operator according to the size of its consumed datasets. Here are the benefits the adaptive batch scheduler can bring:
- Batch job users can be relieved from parallelism tuning.
- Parallelism tuning is fine grained considering different operators. This is particularly beneficial for SQL jobs which can only be set with a global parallelism previously.
- Parallelism tuning can better fit consumed datasets which have a varying volume size every day.
Get Started #
To automatically decide parallelism of operators, you need to:
- Configure to use adaptive batch scheduler.
- Set the parallelism of operators to -1.
Configure to use adaptive batch scheduler #
To use adaptive batch scheduler, you need to set configurations as below:
- Set
jobmanager.scheduler: AdaptiveBatch. - Leave the execution.batch-shuffle-mode unset or explicitly set it to
ALL-EXCHANGES-BLOCKING(default value). Currently, the adaptive batch scheduler only supports batch jobs whose shuffle mode isALL-EXCHANGES-BLOCKING.
In addition, there are several related configuration options to control the upper bounds and lower bounds of tuned parallelisms, to specify expected data volume to process by each operator, and to specify the default parallelism of sources. More details can be found in the feature documentation page.
Set the parallelism of operators to -1 #
The adaptive batch scheduler only automatically decides parallelism of operators whose parallelism is not set (which means the parallelism is -1). To leave parallelism unset, you should configure as follows:
- Set
parallelism.default: -1for all jobs. - Set
table.exec.resource.default-parallelism: -1for SQL jobs. - Don’t call
setParallelism()for operators in DataStream/DataSet jobs. - Don’t call
setParallelism()onStreamExecutionEnvironment/ExecutionEnvironmentin DataStream/DataSet jobs.
Implementation Details #
In this section, we will elaborate the details of the implementation. Before that, we need to briefly introduce some concepts involved:
- JobVertex and JobGraph: A job vertex is an operator chain formed by chaining several operators together for better performance. The job graph is a data flow consisting of job vertices.
- ExecutionVertex and ExecutionGraph: An execution vertex represents a parallel subtask of a job vertex, which will eventually be instantiated as a physical task. For example, a job vertex with a parallelism of 100 will generate 100 execution vertices. The execution graph is the physical execution topology consisting of all execution vertices.
More details about the above concepts can be found in the Flink documentation. Note that the adaptive batch scheduler decides the parallelism of operators by deciding the parallelism of the job vertices which consist of these operators. To automatically decide parallelism of job vertices, we introduced the following changes:
- Enabled the scheduler to collect sizes of finished datasets.
- Introduced a new component VertexParallelismDecider to compute proper parallelisms of job vertices according to the sizes of their consumed results.
- Enabled to dynamically build up execution graph to allow the parallelisms of job vertices to be decided lazily. The execution graph starts with an empty execution topology and then gradually attaches the vertices during job execution.
- Introduced the adaptive batch scheduler to update and schedule the dynamic execution graph.
The details will be introduced in the following sections.
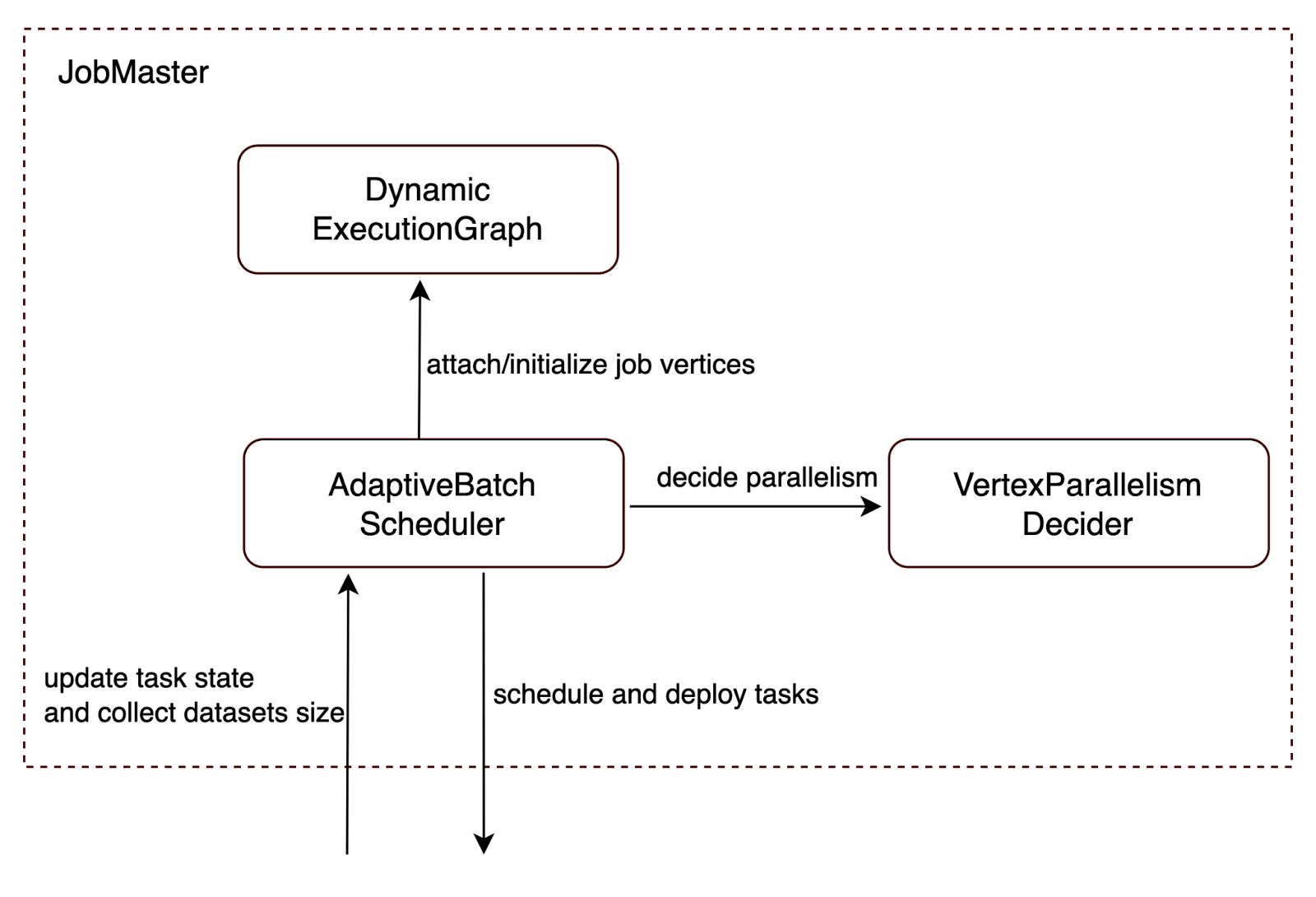
Fig. 1 - The overall structure of automatically deciding parallelism
Collect sizes of consumed datasets #
The adaptive batch scheduler decides the parallelism of vertices by the size of input results, so the scheduler needs to know the sizes of result partitions produced by tasks. We introduced a numBytesProduced counter to record the size of each produced result partition, the accumulated result of the counter will be sent to the scheduler when tasks finish.
Decide proper parallelisms of job vertices #
We introduced a new component VertexParallelismDecider to compute proper parallelisms of job vertices according to the sizes of their consumed results. The computation algorithm is as follows:
Suppose
- V is the bytes of data the user expects to be processed by each task.
- totalBytesnon-broadcast is the sum of the non-broadcast result sizes consumed by this job vertex.
- totalBytesbroadcast is the sum of the broadcast result sizes consumed by this job vertex.
- maxBroadcastRatio is the maximum ratio of broadcast bytes that affects the parallelism calculation.
- normalize(x) is a function that round x to the closest power of 2.
then the parallelism of this job vertex P will be:
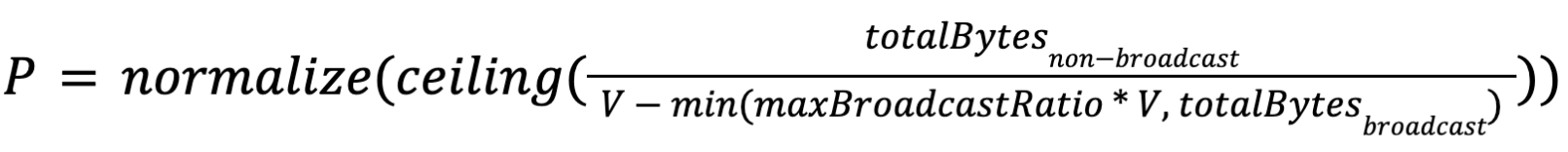
Note that we introduced two special treatment in the above formula :
However, the above formula cannot be used to decide the parallelism of the source vertices, because the source vertices have no input. To solve it, we introduced the configuration option jobmanager.adaptive-batch-scheduler.default-source-parallelism to allow users to manually configure the parallelism of source vertices. Note that not all data sources need this option, because some data sources can automatically infer parallelism (For example, HiveTableSource, see HiveParallelismInference for more detail). For these sources, it is recommended to decide parallelism by themselves.
Limit the maximum ratio of broadcast bytes #
As you can see, we limit the maximum ratio of broadcast bytes that affects the parallelism calculation to maxBroadcastRatio. That is, the non-broadcast bytes processed by each task is at least (1-maxBroadcastRatio) * V. If not so,when the total broadcast bytes is close to V, even if the total non-broadcast bytes is very small, it may cause a large parallelism, which is unnecessary and may lead to resource waste and large task deployment overhead.
Generally, the broadcast dataset is usually relatively small against the other co-processed datasets, so we set the maximum ratio to 0.5 by default. The value is hard coded in the first version, and we may make it configurable later.
Normalize the parallelism to the closest power of 2 #
The normalize is to avoid introducing data skew. To better understand this section, we suggest you read the Flexible subpartition mapping section first.
Taking Fig. 4 (b) as example, A1/A2 produces 4 subpartitions, and the decided parallelism of B is 3. In this case, B1 will consume 1 subpartition, B2 will consume 1 subpartition, and B3 will consume 2 subpartitions. We assume that subpartitions have the same amount of data, which means B3 will consume twice the data of other tasks, data skew is introduced due to the subpartition mapping.
To solve this problem, we need to make the subpartitions evenly consumed by downstream tasks, which means the number of subpartitions should be a multiple of the number of downstream tasks. For simplicity, we require the user-specified max parallelism to be 2N, and then adjust the calculated parallelism to a closest 2M (M <= N), so that we can guarantee that subpartitions will be evenly consumed by downstream tasks.
Note that this is a temporary solution, the ultimate solution would be the Auto-rebalancing of workloads, which may come soon.
Build up execution graph dynamically #
Before the adaptive batch scheduler was introduced to Flink, the execution graph was fully built in a static way before starting scheduling. To allow parallelisms of job vertices to be decided lazily, the execution graph must be able to be built up dynamically.
Create execution vertices and execution edges lazily #
A dynamic execution graph means that a Flink job starts with an empty execution topology, and then gradually attaches vertices during job execution, as shown in Fig. 2.
The execution topology consists of execution vertices and execution edges. The execution vertices will be created and attached to the execution topology only when:
- The parallelism of the corresponding job vertex is decided.
- All upstream execution vertices are already attached.
The parallelism of the job vertex needs to be decided first so that Flink knows how many execution vertices should be created. Upstream execution vertices need to be attached first so that Flink can connect the newly created execution vertices to the upstream vertices with execution edges.
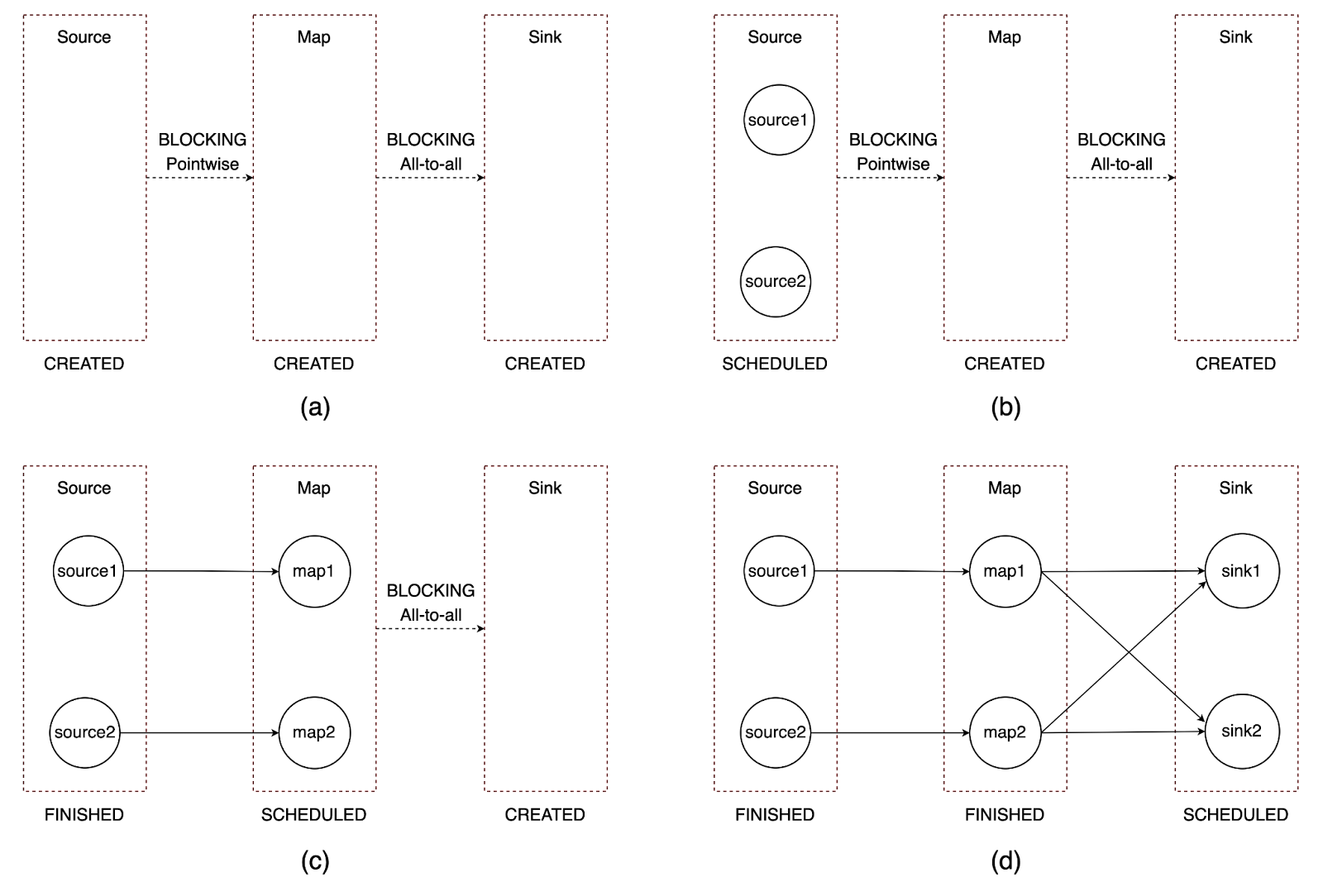
Fig. 2 - Build up execution graph dynamically
Flexible subpartition mapping #
Before the adaptive batch scheduler was introduced to Flink, when deploying a task, Flink needed to know the parallelism of its consumer job vertex. This is because consumer vertex parallelism is used to decide the number of subpartitions produced by each upstream task. The reason behind that is, for one result partition, different subpartitions serve different consumer execution vertices. More specifically, one consumer execution vertex only consumes data from subpartition with the same index.
Taking Fig. 3 as example, parallelism of the consumer B is 2, so the result partition produced by A1/A2 should contain 2 subpartitions, the subpartition with index 0 serves B1, and the subpartition with index 1 serves B2.
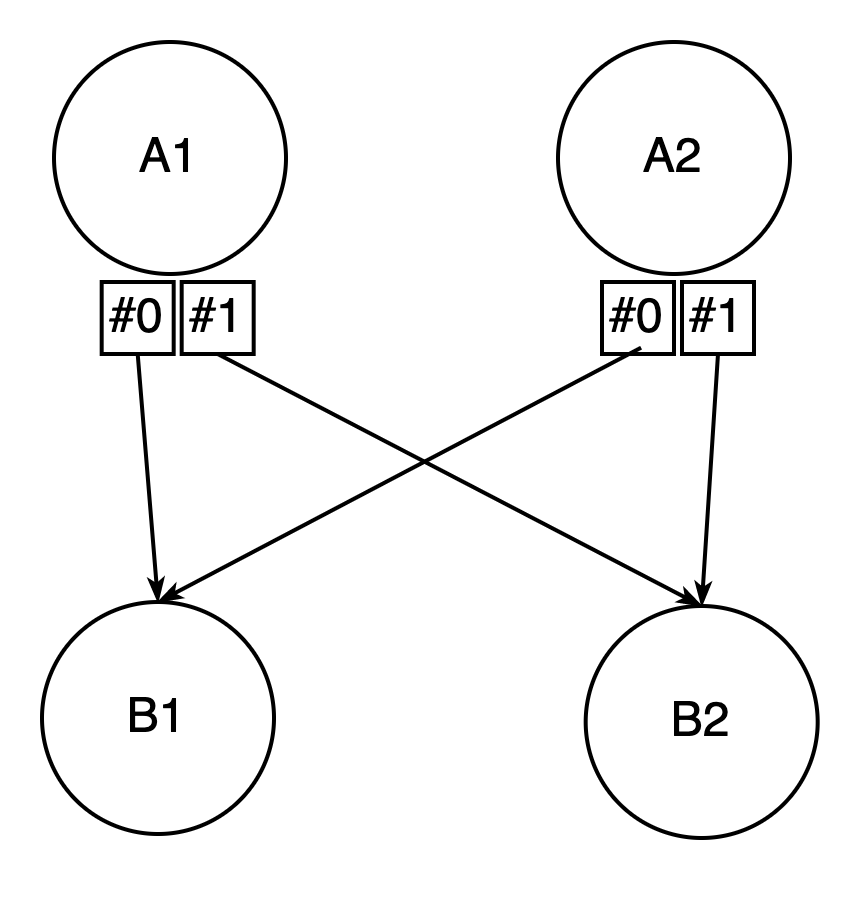
Fig. 3 - How subpartitions serve consumer execution vertices with static execution graph
But obviously, this doesn’t work for dynamic graphs, because when a job vertex is deployed, the parallelism of its consumer job vertices may not have been decided yet. To enable Flink to work in this case, we need a way to allow a job vertex to run without knowing the parallelism of its consumer job vertices.
To achieve this goal, we can set the number of subpartitions to be the max parallelism of the consumer job vertex. Then when the consumer execution vertices are deployed, they should be assigned with a subpartition range to consume. Suppose N is the number of consumer execution vertices and P is the number of subpartitions. For the kth consumer execution vertex, the consumed subpartition range should be:
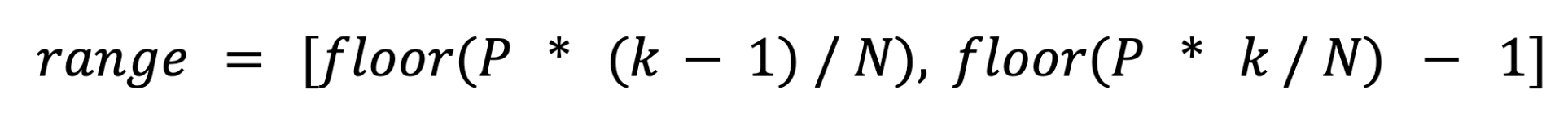
Taking Fig. 4 as example, the max parallelism of B is 4, so A1/A2 have 4 subpartitions. And then if the decided parallelism of B is 2, then the subpartitions mapping will be Fig. 4 (a), if the decided parallelism of B is 3, then the subpartitions mapping will be Fig. 4 (b).
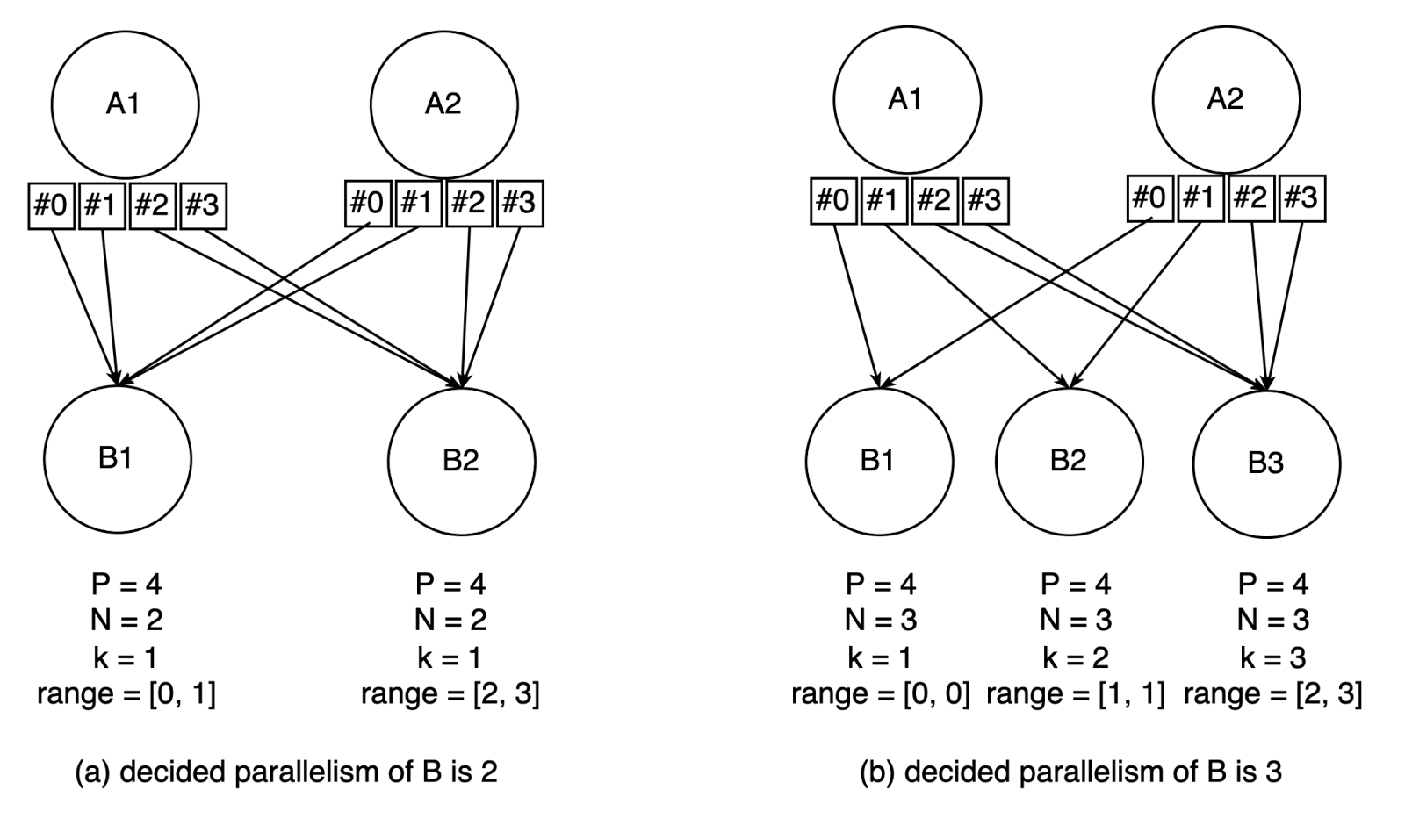
Fig. 4 - How subpartitions serve consumer execution vertices with dynamic graph
Update and schedule the dynamic execution graph #
The adaptive batch scheduler scheduling is similar to the default scheduler, the only difference is that an empty dynamic execution graph will be generated initially and vertices will be attached later. Before handling any scheduling event, the scheduler will try deciding the parallelisms of job vertices, and then initialize them to generate execution vertices, connecting execution edges, and update the execution graph.
The scheduler will try to decide the parallelism of all job vertices before handling each scheduling event, and the parallelism decision will be made for each job vertex in topological order:
- For source vertices, the parallelism should have been decided before starting scheduling.
- For non-source vertices, the parallelism can be decided only when all its consumed results are fully produced.
After deciding the parallelism, the scheduler will try to initialize the job vertices in topological order. A job vertex that can be initialized should meet the following conditions:
- The parallelism of the job vertex has been decided and the job vertex has not been initialized yet.
- All upstream job vertices have been initialized.
Future improvement #
Auto-rebalancing of workloads #
When running batch jobs, data skew may occur (a task needs to process much larger data than other tasks), which leads to long-tail tasks and further slows down the finish of jobs. Users usually hope that the system can automatically solve this problem. One typical data skew case is that some subpartitions have a significantly larger amount of data than others. This case can be solved by finer grained subpartitions and auto-rebalancing of workload. The work of the adaptive batch scheduler can be considered as the first step towards it, because the requirements of auto-rebalancing are similar to adaptive batch scheduler, they both need the support of dynamic graphs and the collection of result partitions size. Based on the implementation of adaptive batch scheduler, we can solve the above problem by increasing max parallelism (for finer grained subpartitions) and simply changing the subpartition range division algorithm (for auto-rebalancing). In the current design, the subpartition range is divided according to the number of subpartitions, we can change it to divide according to the amount of data in subpartitions, so that the amount of data within each subpartition range can be approximately the same. In this way, workloads of downstream tasks can be balanced.
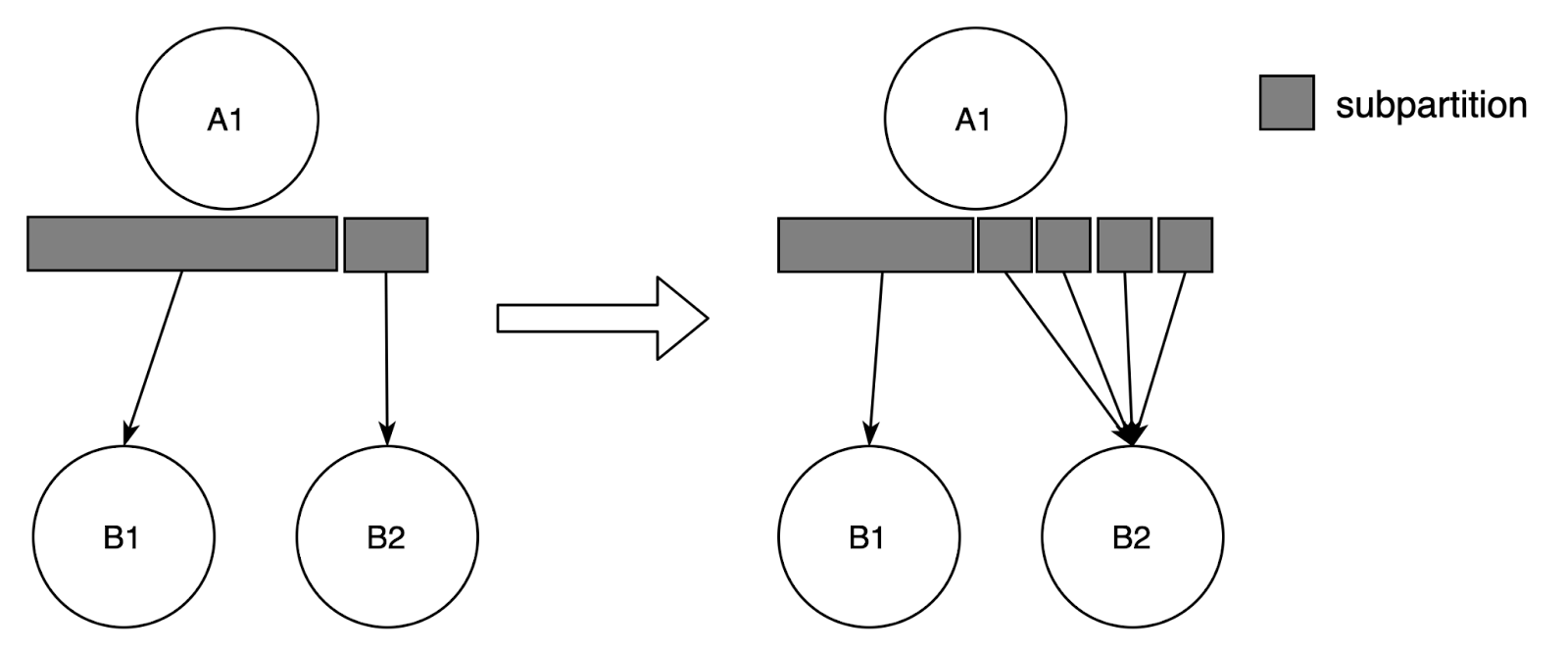
Fig. 5 - Auto-rebalance with finer grained subpartitions