Announcing the Release of Apache Flink 1.16
October 28, 2022 - Godfrey He (@godfreyhe)Apache Flink continues to grow at a rapid pace and is one of the most active communities in Apache. Flink 1.16 had over 240 contributors enthusiastically participating, with 19 FLIPs and 1100+ issues completed, bringing a lot of exciting features to the community.
Flink has become the leading role and factual standard of stream processing, and the concept of the unification of stream and batch data processing is gradually gaining recognition and is being successfully implemented in more and more companies. Previously, the integrated stream and batch concept placed more emphasis on a unified API and a unified computing framework. This year, based on this, Flink proposed the next development direction of Flink-Streaming Warehouse (Streamhouse), which further upgraded the scope of stream-batch integration: it truly completes not only the unified computation but also unified storage, thus realizing unified real-time analysis.
In 1.16, the Flink community has completed many improvements for both batch and stream processing:
- For batch processing, all-round improvements in ease of use, stability and performance
have been completed. 1.16 is a milestone version of Flink batch processing and an important
step towards maturity.
- Ease of use: with the introduction of SQL Gateway and full compatibility with Hive Server2, users can submit Flink SQL jobs and Hive SQL jobs very easily, and it is also easy to connect to the original Hive ecosystem.
- Functionality: Join hints let Flink SQL users manually specify join strategies to avoid unreasonable execution plans. The compatibility of Hive SQL has reached 94%, and users can migrate from Hive to Flink at a very low cost.
- Stability: Propose a speculative execution mechanism to reduce the long tail sub-tasks of a job and improve the stability. Improve HashJoin and introduce failure rollback mechanism to avoid join failure.
- Performance: Introduce dynamic partition pruning to reduce the Scan I/O and improve join processing for the star-schema queries. There is 30% improvement in the TPC-DS benchmark. We can use hybrid shuffle mode to improve resource usage and processing performance.
- For stream processing, there are a number of significant improvements:
- Changelog State Backend provides users with second or even millisecond checkpoints to dramatically improve the fault tolerance experience, while providing a smaller end-to-end latency experience for transactional Sink jobs.
- Lookup join is widely used in stream processing. Slow lookup speed, low throughput and delay update are resolved through common cache mechanism, asynchronous io and retriable lookup. These features are very useful, solving the pain points that users often complain about, and supporting richer scenarios.
- From the first day of the birth of Flink SQL, there were some non-deterministic operations that could cause incorrect results or exceptions, which caused great distress to users. In 1.16, we spent a lot of effort to solve most of the problems, and we will continue to improve in the future.
With the further refinement of the integration of stream and batch, and the continuous iteration of the Flink Table Store (0.2 has been released), the Flink community is pushing the Streaming warehouse from concept to reality and maturity step by step.
Understanding Streaming Warehouses #
To be precise, a streaming warehouse is to make data warehouse streaming, which allows the data for each layer in the whole warehouse to flow in real-time. The goal is to realize a Streaming Service with end-to-end real-time performance through a unified API and computing framework. Please refer to the article for more details.
Batch processing #
Flink is a unified stream batch processing engine, stream processing has become the leading role thanks to our long-term investment. We’re also putting more effort to improve batch processing to make it an excellent computing engine. This makes the overall experience of stream batch unification smoother.
SQL Gateway #
The feedback from various channels indicates that SQL Gateway is a highly anticipated feature for users, especially for batch users. This function finally completed (see FLIP-91 for design) in 1.16. SQL Gateway is an extension and enhancement to SQL Client, supporting multi-tenancy and pluggable API protocols (Endpoints), solving the problem that SQL Client can only serve a single user and cannot be integrated with external services or components. Currently SQL Gateway has support for REST API and HiveServer2 Protocol and users can link to SQL Gateway via cURL, Postman, HTTP clients in various programming languages to submit stream jobs, batch jobs and even OLAP jobs. For HiveServer2 Endpoint, please refer to the Hive Compatibility for more details.
Hive Compatibility #
To reduce the cost of migrating Hive to Flink, we introduce HiveServer2 Endpoint and Hive Syntax Improvements in this version:
The HiveServer2 Endpoint allows users to interact with SQL Gateway with Hive JDBC/Beeline and migrate with Flink into the Hive ecosystem (DBeaver, Apache Superset, Apache DolphinScheduler, and Apache Zeppelin). When users connect to the HiveServer2 endpoint, the SQL Gateway registers the Hive Catalog, switches to Hive Dialect, and uses batch execution mode to execute jobs. With these steps, users can have the same experience as HiveServer2.
Hive syntax is already the factual standard for big data processing. Flink has improved compatibility with Hive syntax and added support for several Hive syntaxes commonly used in production. Hive syntax compatibility can help users migrate existing Hive SQL tasks to Flink, and it is convenient for users who are familiar with Hive syntax to use Hive syntax to write SQL to query tables registered in Flink. The compatibility is measured using the Hive qtest suite which contains more than 12K SQL cases. Until now, for Hive 2.3, the compatibility has reached 94.1% for whole hive queries, and has reached 97.3% if ACID queries are excluded.
Join Hints for Flink SQL #
The join hint is a common solution in the industry to improve the shortcomings of the optimizer by manually modifying the execution plans. Join is the most widely used operator in batch jobs, and Flink supports a variety of join strategies. Missing statistics or a poor cost model of the optimizer can lead to the wrong choice of a join strategy, which will cause slow execution or even job failure. By specifying a Join Hint, the optimizer will choose the join strategy specified by the user whenever possible. It could avoid various shortcomings of the optimizer and ensure the production availability of the batch job.
Adaptive Hash Join #
For batch jobs, the hash join operators may fail if the input data is severely skewed, it’s a very bad experience for users. To solve this, we introduce adaptive Hash-Join which can automatically fall back to Sort-Merge-Join once the Hash-Join fails in runtime. This mechanism ensures that the Hash-Join is always successful and improves the stability by gracefully degrading from a Hash-Join to a more robust Sort-Merge-Join.
Speculative Execution for Batch Job #
Speculative execution is introduced in Flink 1.16 to mitigate batch job slowness which is caused by problematic nodes. A problematic node may have hardware problems, accident I/O busy, or high CPU load. These problems may make the hosted tasks run much slower than tasks on other nodes, and affect the overall execution time of a batch job.
When speculative execution is enabled, Flink will keep detecting slow tasks. Once slow tasks are detected, the nodes that the slow tasks locate in will be identified as problematic nodes and get blocked via the blocklist mechanism (FLIP-224). The scheduler will create new attempts for the slow tasks and deploy them to nodes that are not blocked, while the existing attempts will keep running. The new attempts process the same input data and produce the same data as the original attempt. Once any attempt finishes first, it will be admitted as the only finished attempt of the task, and the remaining attempts of the task will be canceled.
Most existing sources can work with speculative execution (FLIP-245).
Only if a source uses SourceEvent, it must implement SupportsHandleExecutionAttemptSourceEvent interface to support
speculative execution. Sinks do not support speculative execution yet so that
speculative execution will not happen on sinks at the moment.
The Web UI & REST API are also improved (FLIP-249) to display multiple concurrent attempts of tasks and blocked task managers.
Hybrid Shuffle Mode #
We have introduced a new Hybrid Shuffle Mode for batch executions. It combines the advantages of blocking shuffle and pipelined shuffle (in streaming mode).
- Like blocking shuffle, it does not require upstream and downstream tasks to run simultaneously, which allows executing a job with little resources.
- Like pipelined shuffle, it does not require downstream tasks to be executed after upstream tasks finish, which reduces the overall execution time of the job when given sufficient resources.
- It adapts to custom preferences between persisting less data and restarting less tasks on failures, by providing different spilling strategies.
Note: This feature is experimental and by default not activated.
Further improvements of blocking shuffle #
We further improved the blocking shuffle usability and performance in this version, including adaptive network buffer allocation, sequential IO optimization and result partition reuse which allows multiple consumer vertices reusing the same physical result partition to reduce disk IO and storage space. These optimizations can achieve an overall 7% performance gain for the TPC-DS test with a scale of 10 TB. In addition, two more compression algorithms (LZO and ZSTD) with higher compression ratio were introduced which can further reduce the storage space with some CPU cost compared to the default LZ4 compression algorithm.
Dynamic Partition Pruning #
For batch jobs, partitioned tables are more widely used than non-partitioned tables in production environments. Currently Flink has support for static partition pruning, where the optimizer pushes down the partition field related filter conditions in the WHERE clause into the Source Connector during the optimization phase, thus reducing unnecessary partition scan IO. The star-schema is the simplest of the most commonly used data mart patterns. We have found that many user jobs cannot use static partition pruning because partition pruning information can only be determined in execution, which requires dynamic partition pruning techniques, where partition pruning information is collected at runtime based on data from other related tables, thus reducing unnecessary partition scan IO for partitioned tables. The use of dynamic partition pruning has been validated with the 10 TB dataset TPC-DS to improve performance by up to 30%.
Stream Processing #
In 1.16, we have made improvements in Checkpoints, SQL, Connector and other fields, so that stream computing can continue to lead.
Generalized incremental checkpoint #
Changelog state backend aims at making checkpoint intervals shorter and more predictable, this release is prod-ready and is dedicated to adapting changelog state backend to the existing state backends and improving the usability of changelog state backend:
- Support state migration
- Support local recovery
- Introduce file cache to optimize restoring
- Support switch based on checkpoint
- Improve the monitoring experience of changelog state backend
- expose changelog’s metrics
- expose changelog’s configuration to webUI
Table 1: The comparison between Changelog Enabled / Changelog Disabled on value state (see this blog for more details)
{:class=“table table-bordered”}
| Percentile | End to End Duration | Checkpointed Data Size* | Full Checkpoint Data Size* |
|---|---|---|---|
| 50% | 311ms / 5s | 14.8MB / 3.05GB | 24.2GB / 18.5GB |
| 90% | 664ms / 6s | 23.5MB / 4.52GB | 25.2GB / 19.3GB |
| 99% | 1s / 7s | 36.6MB / 5.19GB | 25.6GB / 19.6GB |
| 99.9% | 1s / 10s | 52.8MB / 6.49GB | 25.7GB / 19.8GB |
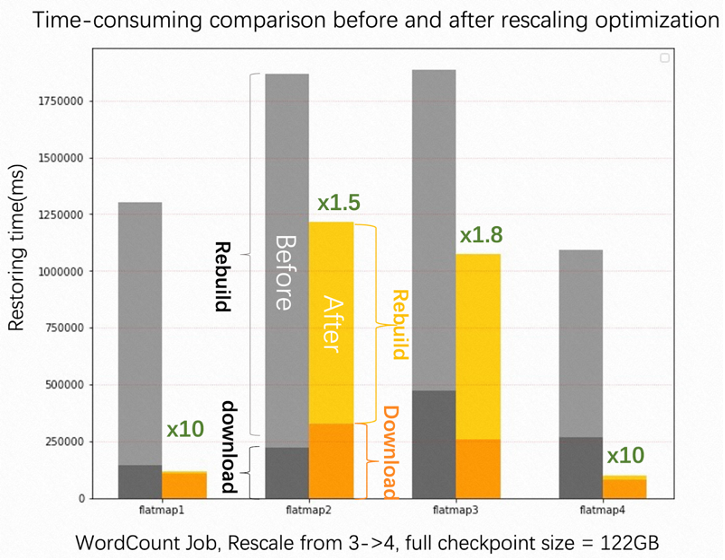
RocksDB rescaling improvement & rescaling benchmark #
Rescaling is a frequent operation for cloud services built on Apache Flink, this release leverages deleteRange to optimize the rescaling of Incremental RocksDB state backend. deleteRange is used to avoid massive scan-and-delete operations, for upscaling with a large number of states that need to be deleted, the speed of restoring can be almost increased by 2~10 times.
Improve monitoring experience and usability of state backend #
This release also improves the monitoring experience and usability of state backend. Previously, RocksDB’s log was located in its own DB folder, which made debugging RocksDB not so easy. This release lets RocksDB’s log stay in Flink’s log directory by default. RocksDB statistics-based metrics are introduced to help debug the performance at the database level, e.g. total block cache hit/miss count within the DB.
Support overdraft buffer #
A new concept of overdraft network buffer
is introduced to mitigate the effects of uninterruptible blocking a subtask thread during back pressure,
which can be turned on through the taskmanager.network.memory.max-overdraft-buffers-per-gate
configuration parameter.
Starting from 1.16.0, Flink subtask can request by default up to 5 extra (overdraft) buffers over
the regular configured amount. This change can slightly increase memory consumption of
the Flink Job but vastly reduce the checkpoint duration of the unaligned checkpoint.
If the subtask is back pressured by downstream subtasks and the subtask requires more than
a single network buffer to finish what it’s currently doing, overdraft buffer comes into play.
Read more about this in the documentation.
Timeout aligned to unaligned checkpoint barrier in the output buffers of an upstream subtask #
This release updates the timing of switching from Aligned Checkpoint (AC) to Unaligned Checkpoint (UC). With UC enabled, if execution.checkpointing.aligned-checkpoint-timeout is configured, each checkpoint will still begin as an AC, but when the global checkpoint duration exceeds the aligned-checkpoint-timeout, if the AC has not been completed, then the checkpoint will be switched to unaligned.
Previously, the switch of one subtask needs to wait for all barriers from upstream. If the back pressure is severe, the downstream subtask may not receive all barriers within checkpointing-timeout, causing the checkpoint to fail.
In this release, if the barrier cannot be sent from the output buffer to the downstream task
within the execution.checkpointing.aligned-checkpoint-timeout, Flink lets upstream subtasks
switch to UC first to send barriers to downstream, thereby decreasing
the probability of checkpoint timeout during back pressure.
More details can be found in this documentation.
Non-Determinism In Stream Processing #
Users often complain about the high cost of understanding stream processing. One of the pain points is the non-determinisim in stream processing (usually not intuitive) which may cause wrong results or errors. These pain points have been around since the early days of Flink SQL.
For complex streaming jobs, now it’s possible to detect and resolve potential correctness issues before running. If the problems can’t be resolved completely, a detailed message could prompt users to adjust the SQL so as to avoid introducing non-deterministic problems. More details can be found in the documentation.
Enhanced Lookup Join #
Lookup join is widely used in stream processing, and we have introduced several improvements:
- Adds a unified abstraction for lookup source cache and related metrics to speed up lookup queries
- Introduces the configurable asynchronous mode (ALLOW_UNORDERED) via job configuration or lookup hint to significantly improve query throughput without compromising correctness.
- Retryable lookup mechanism gives users more tools to solve the delayed updates issue in external systems.
Retry Support For Async I/O #
Introduces a built-in retry mechanism for asynchronous I/O that is transparent to the user’s existing code, allowing flexibility to meet the user’s retry and exception handling needs.
PyFlink #
In Flink 1.15, we have introduced a new execution mode ’thread’ mode in which the user-defined Python functions will be executed in the JVM via JNI instead of in a separate Python process. However, it’s only supported for Python scalar functions in the Table API & SQL in Flink 1.15. In this release, we have provided more comprehensive support for it. It has also been supported in the Python DataStream API and also Python table functions in the Table API & SQL.
We are also continuing to fill in the last few missing features in Python API. In this release, we have provided more comprehensive support for Python DataStream API and supported features such as side output, broadcast state, etc and have also finalized the windowing support. We have also added support for more connectors and formats in the Python DataStream API, e.g. added support for connectors elasticsearch, kinesis, pulsar, hybrid source, etc and formats orc, parquet, etc. With all these features added, the Python API should have aligned most notable features in the Java & Scala API and users should be able to develop most kinds of Flink jobs using Python language smoothly.
Others #
New SQL Syntax #
In 1.16, we extend more DDL syntaxes which could help users to better use SQL:
- USING JAR supports dynamic loading of UDF jar to help platform developers to easily manage UDF.
- CREATE TABLE AS SELECT (CTAS) supports users to create new tables based on existing tables and queries.
- ANALYZE TABLE supports users to manually generate table statistics so that the optimizer could generate better execution plans.
Cache in DataStream for Interactive Programming #
Supports caching the result of a transformation via DataStream#cache. The cached intermediate result is generated lazily at the first time the intermediate result is computed so that the result can be reused by later jobs. If the cache is lost, it will be recomputed using the original transformations. Currently only batch mode is supported. This feature is very useful for ML and interactive programming in Python.
History Server & Completed Jobs Information Enhancement #
We have enhanced the experiences of viewing completed jobs’ information in this release.
- JobManager / HistoryServer WebUI now provides detailed execution time metrics, including duration tasks spent in each execution state and the accumulated busy / idle / back-pressured time during running.
- JobManager / HistoryServer WebUI now provides aggregation of major SubTask metrics, grouped by Task or TaskManager.
- JobManager / HistoryServer WebUI now provides more environmental information, including environment variables, JVM options and classpath.
- HistoryServer now supports browsing logs from external log archiving services.
Protobuf format #
Flink now supports the Protocol Buffers (Protobuf) format. This allows you to use this format directly in your Table API or SQL applications.
Introduce configurable RateLimitingStrategy for Async Sink #
The Async Sink was implemented in 1.15 to allow users to easily implement their own custom asynchronous sinks. We have now extended it to support a configurable RateLimitingStrategy. This means sink implementers can now customize how their Async Sink behaves when requests fail, depending on the specific sink. If no RateLimitingStrategy is specified, it will default to the current default of AIMDScalingStrategy.
Upgrade Notes #
We aim to make upgrades as smooth as possible, but some of the changes require users to adjust some parts of the program when upgrading to Apache Flink 1.16. Please take a look at the release notes for a list of adjustments to make and issues to check during upgrades.
List of Contributors #
The Apache Flink community would like to thank each one of the contributors that have made this release possible:
1996fanrui, Ada Wang, Ada Wong, Ahmed Hamdy, Aitozi, Alexander Fedulov, Alexander Preuß, Alexander Trushev, Andriy Redko, Anton Kalashnikov, Arvid Heise, Ben Augarten, Benchao Li, BiGsuw, Biao Geng, Bobby Richard, Brayno, CPS794, Cheng Pan, Chengkai Yang, Chesnay Schepler, Danny Cranmer, David N Perkins, Dawid Wysakowicz, Dian Fu, DingGeGe, EchoLee5, Etienne Chauchot, Fabian Paul, Ferenc Csaky, Francesco Guardiani, Gabor Somogyi, Gen Luo, Gyula Fora, Haizhou Zhao, Hangxiang Yu, Hao Wang, Hong Liang Teoh, Hong Teoh, Hongbo Miao, HuangXingBo, Ingo Bürk, Jacky Lau, Jane Chan, Jark Wu, Jay Li, Jia Liu, Jie Wang, Jin, Jing Ge, Jing Zhang, Jingsong Lee, Jinhu Wu, Joe Moser, Joey Pereira, Jun He, JunRuiLee, Juntao Hu, JustDoDT, Kai Chen, Krzysztof Chmielewski, Krzysztof Dziolak, Kyle Dong, LeoZhang, Levani Kokhreidze, Lihe Ma, Lijie Wang, Liu Jiangang, Luning Wang, Marios Trivyzas, Martijn Visser, MartijnVisser, Mason Chen, Matthias Pohl, Metehan Yıldırım, Michael, Mingde Peng, Mingliang Liu, Mulavar, Márton Balassi, Nie yingping, Niklas Semmler, Paul Lam, Paul Lin, Paul Zhang, PengYuan, Piotr Nowojski, Qingsheng Ren, Qishang Zhong, Ran Tao, Robert Metzger, Roc Marshal, Roman Boyko, Roman Khachatryan, Ron, Ron Cohen, Ruanshubin, Rudi Kershaw, Rufus Refactor, Ryan Skraba, Sebastian Mattheis, Sergey, Sergey Nuyanzin, Shengkai, Shubham Bansal, SmirAlex, Smirnov Alexander, SteNicholas, Steven van Rossum, Suhan Mao, Tan Yuxin, Tartarus0zm, TennyZhuang, Terry Wang, Thesharing, Thomas Weise, Timo Walther, Tom, Tony Wei, Weijie Guo, Wencong Liu, WencongLiu, Xintong Song, Xuyang, Yangze Guo, Yi Tang, Yu Chen, Yuan Huang, Yubin Li, Yufan Sheng, Yufei Zhang, Yun Gao, Yun Tang, Yuxin Tan, Zakelly, Zhanghao Chen, Zhu Zhu, Zichen Liu, Zili Sun, acquachen, bgeng777, billyrrr, bzhao, caoyu, chenlei677, chenzihao, chenzihao5, coderap, cphe, davidliu, dependabot[bot], dkkb, dusukang, empcl, eyys, fanrui, fengjiankun, fengli, fredia, gabor.g.somogyi, godfreyhe, gongzhongqiang, harker2015, hongli, huangxingbo, huweihua, jayce, jaydonzhou, jiabao.sun, kevin.cyj, kurt, lidefu, lijiewang.wlj, liliwei, lincoln lee, lincoln.lil, littleeleventhwolf, liufangqi, liujia10, liujiangang, liujingmao, liuyongvs, liuzhuang2017, longwang, lovewin99, luoyuxia, mans2singh, maosuhan, mayue.fight, mayuehappy, nieyingping, pengmide, pengmingde, polaris6, pvary, qinjunjerry, realdengziqi, root, shammon, shihong90, shuiqiangchen, slinkydeveloper, snailHumming, snuyanzin, suxinglee, sxnan, tison, trushev, tsreaper, unknown, wangfeifan, wangyang0918, wangzhiwu, wenbingshen, xiangqiao123, xuyang, yangjf2019, yangjunhan, yangsanity, yangxin, ylchou, yuchengxin, yunfengzhou-hub, yuxia Luo, yuzelin, zhangchaoming, zhangjingcun, zhangmang, zhangzhengqi3, zhaoweinan, zhengyunhong.zyh, zhenyu xing, zhouli, zhuanshenbsj1, zhuzhu.zz, zoucao, zp, 周磊, 饶紫轩,, 鲍健昕 愚鲤, 帝国阿三