Apache Flink Table Store 0.3.0 Release Announcement
January 13, 2023 - Jingsong LeeThe Apache Flink community is pleased to announce the release of the Apache Flink Table Store (0.3.0).
We highly recommend all users upgrade to Flink Table Store 0.3.0. 0.3.0 completed 150+ issues, which were completed by nearly 30 contributors.
Please check out the full documentation for detailed information and user guides.
Flink Table Store 0.3 completes many exciting features, enhances its ability as a data lake storage and greatly improves the availability of its stream pipeline. Some important features are described below.
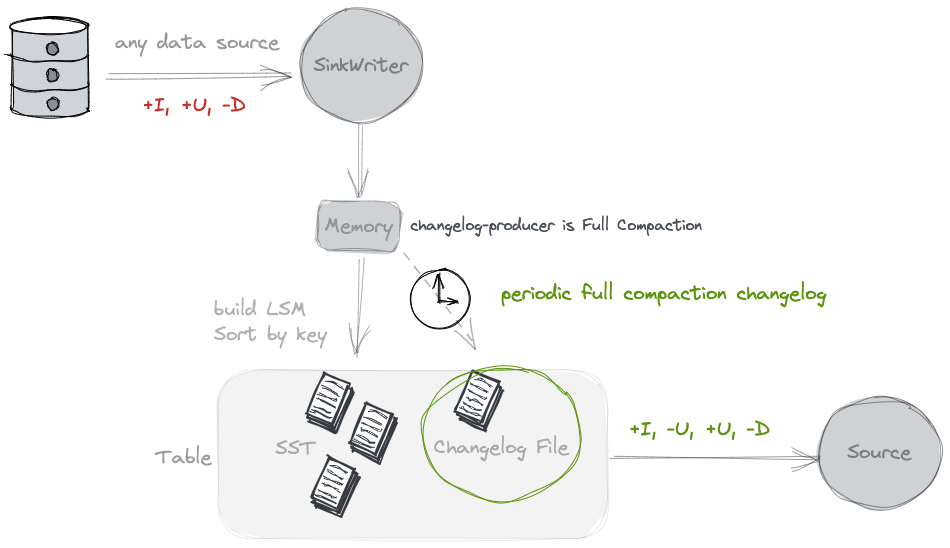
Changelog Producer: Full-Compaction #
If:
- You are using
partial-updateoraggregationtable, at the time of writing, table store can’t know what the result is after merging, so table store can’t generate the corresponding changelog. - Your input can’t produce a complete changelog but you still want to get rid of the costly normalized operator,
You may consider using the Full compaction changelog producer.
By specifying 'changelog-producer' = 'full-compaction', Table Store will compare the results between full compactions
and produce the differences as changelog. The latency of changelog is affected by the frequency of full compactions.
By specifying changelog-producer.compaction-interval table property (default value 30min), users can define the
maximum interval between two full compactions to ensure latency.
Dedicated Compaction Job && Multiple Writers #
By default, Table Store writers will perform compaction as needed when writing records. This is sufficient for most use cases, but there are two downsides:
- This may result in unstable write throughput because throughput might temporarily drop when performing a compaction.
- Compaction will mark some data files as “deleted”. If multiple writers mark the same file a conflict will occur when committing the changes. Table Store will automatically resolve the conflict, but this may result in job restarts.
To avoid these downsides, users can also choose to skip compactions in writers, and run a dedicated job only for compaction. As compactions are performed only by the dedicated job, writers can continuously write records without pausing and no conflicts will ever occur.
To skip compactions in writers, set write-only to true.
To run a dedicated job for compaction, follow these instructions.
Flink SQL currently does not support statements related to compactions, so we have to submit the compaction job through flink run.
Run the following command to submit a compaction job for the table.
<FLINK_HOME>/bin/flink run \
-c org.apache.flink.table.store.connector.action.FlinkActions \
/path/to/flink-table-store-dist-<version>.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name>
Aggregation Table #
Sometimes users only care about aggregated results. The aggregation merge engine aggregates each value field with the latest data one by one under the same primary key according to the aggregate function.
Each field that is not part of the primary keys must be given an aggregate function, specified by the
fields.<field-name>.aggregate-function table property.
For example:
CREATE TABLE MyTable (
product_id BIGINT,
price DOUBLE,
sales BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
'fields.price.aggregate-function' = 'max',
'fields.sales.aggregate-function' = 'sum'
);
Schema Evolution #
In version 0.2, the research and development of Schema Evolution has begun. In version 0.3, some of the capabilities of Schema Evolution have been completed. You can use below operations in Spark-SQL (Flink SQL completes the following syntax in 1.17):
- Adding New Columns
- Renaming Column Name
- Dropping Columns
Flink Table Store ensures that the above operations are safe, and the old data will automatically adapt to the new schema when it is read.
For example:
CREATE TABLE T (i INT, j INT);
INSERT INTO T (1, 1);
ALTER TABLE T ADD COLUMN k INT;
ALTER TABLE T RENAME COLUMN i to a;
INSERT INTO T (2, 2, 2);
SELECT * FROM T;
-- outputs (1, 1, NULL) and (2, 2, 2)
Flink Lookup Join #
Lookup Joins are a type of join in streaming queries. It is used to enrich a table with data that is queried from Table Store. The join requires one table to have a processing time attribute and the other table to be backed by a lookup source connector.
Table Store supports lookup joins on unpartitioned tables with primary keys in Flink.
The lookup join operator will maintain a RocksDB cache locally and pull the latest updates of the table in real time. Lookup join operator will only pull the necessary data, so your filter conditions are very important for performance.
This feature is only suitable for tables containing at most tens of millions of records to avoid excessive use of local disks.
Time Traveling #
You can use Snapshots Table and Scan Mode to time traveling.
- You can view all current snapshots by reading snapshots table.
- You can travel time through
from-timestampandfrom-snapshot.
For example:
SELECT * FROM T$options;
/*
+--------------+------------+--------------+-------------------------+
| snapshot_id | schema_id | commit_kind | commit_time |
+--------------+------------+--------------+-------------------------+
| 2 | 0 | APPEND | 2022-10-26 11:44:15.600 |
| 1 | 0 | APPEND | 2022-10-26 11:44:15.148 |
+--------------+------------+--------------+-------------------------+
2 rows in set
*/
SELECT * FROM T /*+ OPTIONS('from-snapshot'='1') */;
Audit Log Table #
If you need to audit the changelog of the table, you can use the
audit_log
system table. Through audit_log table, you can get the rowkind column when you get the incremental data of the table.
You can use this column for filtering and other operations to complete the audit.
There are four values for rowkind:
- +I: Insertion operation.
- -U: Update operation with the previous content of the updated row.
- +U: Update operation with new content of the updated row.
- -D: Deletion operation.
For example:
SELECT * FROM MyTable$audit_log;
/*
+------------------+-----------------+-----------------+
| rowkind | column_0 | column_1 |
+------------------+-----------------+-----------------+
| +I | ... | ... |
+------------------+-----------------+-----------------+
| -U | ... | ... |
+------------------+-----------------+-----------------+
| +U | ... | ... |
+------------------+-----------------+-----------------+
3 rows in set
*/
Ecosystem #
Flink Table Store continues to strengthen its ecosystem and gradually gets through the reading and writing of all engines. Each engine below 0.3 has been enhanced.
- Spark write has been supported. But
INSERT OVERWRITEand stream write are still unsupported. - S3 and OSS are supported by all computing engines.
- Hive 3.1 is supported.
- Trino the latest version (JDK 1s.17) is supported.
Getting started #
Please refer to the getting started guide for more details.
What’s Next? #
In the upcoming 0.4.0 release you can expect the following additional features:
- Provides Flink decoupled independent Java APIs
- Spark: enhance batch write, provide streaming write and streaming read
- Flink: complete DDL & DML, providing more management operations
- Changelog producer: Lookup, the delay of stream reading each scenario is less than one minute
- Provide multi table consistent materialized views in real-time
- Data Integration: Schema Evolution integration, whole database integration.
Please give the release a try, share your feedback on the Flink mailing list and contribute to the project!
List of Contributors #
The Apache Flink community would like to thank every one of the contributors that have made this release possible:
Feng Wang, Hannankan, Jane Chan, Jia Liu, Jingsong Lee, Jonathan Leitschuh, JunZhang, Kirill Listopad, Liwei Li, MOBIN-F, Nicholas Jiang, Wang Luning, WencongLiu, Yubin Li, gongzhongqiang, houhang1005, liuzhuang2017, openinx, tsreaper, wuyouwuyoulian, zhuangchong, zjureel (shammon), 吴祥平