Hadoop Compatibility in Flink
November 18, 2014 -Apache Hadoop is an industry standard for scalable analytical data processing. Many data analysis applications have been implemented as Hadoop MapReduce jobs and run in clusters around the world. Apache Flink can be an alternative to MapReduce and improves it in many dimensions. Among other features, Flink provides much better performance and offers APIs in Java and Scala, which are very easy to use. Similar to Hadoop, Flink’s APIs provide interfaces for Mapper and Reducer functions, as well as Input- and OutputFormats along with many more operators. While being conceptually equivalent, Hadoop’s MapReduce and Flink’s interfaces for these functions are unfortunately not source compatible.
Flink’s Hadoop Compatibility Package #

To close this gap, Flink provides a Hadoop Compatibility package to wrap functions implemented against Hadoop’s MapReduce interfaces and embed them in Flink programs. This package was developed as part of a Google Summer of Code 2014 project.
With the Hadoop Compatibility package, you can reuse all your Hadoop
InputFormats(mapred and mapreduce APIs)OutputFormats(mapred and mapreduce APIs)Mappers(mapred API)Reducers(mapred API)
in Flink programs without changing a line of code. Moreover, Flink also natively supports all Hadoop data types (Writables and WritableComparable).
The following code snippet shows a simple Flink WordCount program that solely uses Hadoop data types, InputFormat, OutputFormat, Mapper, and Reducer functions.
// Definition of Hadoop Mapper function
public class Tokenizer implements Mapper<LongWritable, Text, Text, LongWritable> { ... }
// Definition of Hadoop Reducer function
public class Counter implements Reducer<Text, LongWritable, Text, LongWritable> { ... }
public static void main(String[] args) {
final String inputPath = args[0];
final String outputPath = args[1];
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Setup Hadoop’s TextInputFormat
HadoopInputFormat<LongWritable, Text> hadoopInputFormat =
new HadoopInputFormat<LongWritable, Text>(
new TextInputFormat(), LongWritable.class, Text.class, new JobConf());
TextInputFormat.addInputPath(hadoopInputFormat.getJobConf(), new Path(inputPath));
// Read a DataSet with the Hadoop InputFormat
DataSet<Tuple2<LongWritable, Text>> text = env.createInput(hadoopInputFormat);
DataSet<Tuple2<Text, LongWritable>> words = text
// Wrap Tokenizer Mapper function
.flatMap(new HadoopMapFunction<LongWritable, Text, Text, LongWritable>(new Tokenizer()))
.groupBy(0)
// Wrap Counter Reducer function (used as Reducer and Combiner)
.reduceGroup(new HadoopReduceCombineFunction<Text, LongWritable, Text, LongWritable>(
new Counter(), new Counter()));
// Setup Hadoop’s TextOutputFormat
HadoopOutputFormat<Text, LongWritable> hadoopOutputFormat =
new HadoopOutputFormat<Text, LongWritable>(
new TextOutputFormat<Text, LongWritable>(), new JobConf());
hadoopOutputFormat.getJobConf().set("mapred.textoutputformat.separator", " ");
TextOutputFormat.setOutputPath(hadoopOutputFormat.getJobConf(), new Path(outputPath));
// Output & Execute
words.output(hadoopOutputFormat);
env.execute("Hadoop Compat WordCount");
}
As you can see, Flink represents Hadoop key-value pairs as Tuple2<key, value> tuples. Note, that the program uses Flink’s groupBy() transformation to group data on the key field (field 0 of the Tuple2<key, value>) before it is given to the Reducer function. At the moment, the compatibility package does not evaluate custom Hadoop partitioners, sorting comparators, or grouping comparators.
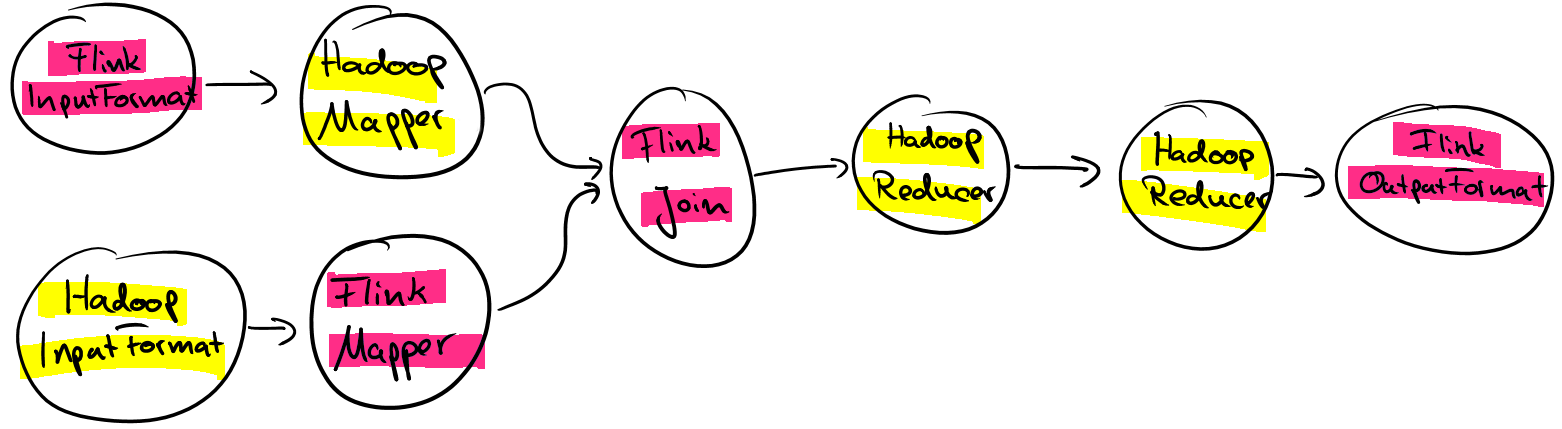
Hadoop functions can be used at any position within a Flink program and of course also be mixed with native Flink functions. This means that instead of assembling a workflow of Hadoop jobs in an external driver method or using a workflow scheduler such as Apache Oozie, you can implement an arbitrary complex Flink program consisting of multiple Hadoop Input- and OutputFormats, Mapper and Reducer functions. When executing such a Flink program, data will be pipelined between your Hadoop functions and will not be written to HDFS just for the purpose of data exchange.
What comes next? #
While the Hadoop compatibility package is already very useful, we are currently working on a dedicated Hadoop Job operation to embed and execute Hadoop jobs as a whole in Flink programs, including their custom partitioning, sorting, and grouping code. With this feature, you will be able to chain multiple Hadoop jobs, mix them with Flink functions, and other operations such as Spargel operations (Pregel/Giraph-style jobs).
Summary #
Flink lets you reuse a lot of the code you wrote for Hadoop MapReduce, including all data types, all Input- and OutputFormats, and Mapper and Reducers of the mapred-API. Hadoop functions can be used within Flink programs and mixed with all other Flink functions. Due to Flink’s pipelined execution, Hadoop functions can arbitrarily be assembled without data exchange via HDFS. Moreover, the Flink community is currently working on a dedicated Hadoop Job operation to supporting the execution of Hadoop jobs as a whole.
If you want to use Flink’s Hadoop compatibility package checkout our documentation.