Flink 2015: A year in review, and a lookout to 2016
December 18, 2015 -With 2015 ending, we thought that this would be good time to reflect on the amazing work done by the Flink community over this past year, and how much this community has grown.
Overall, we have seen Flink grow in terms of functionality from an engine to one of the most complete open-source stream processing frameworks available. The community grew from a relatively small and geographically focused team, to a truly global, and one of the largest big data communities in the the Apache Software Foundation.
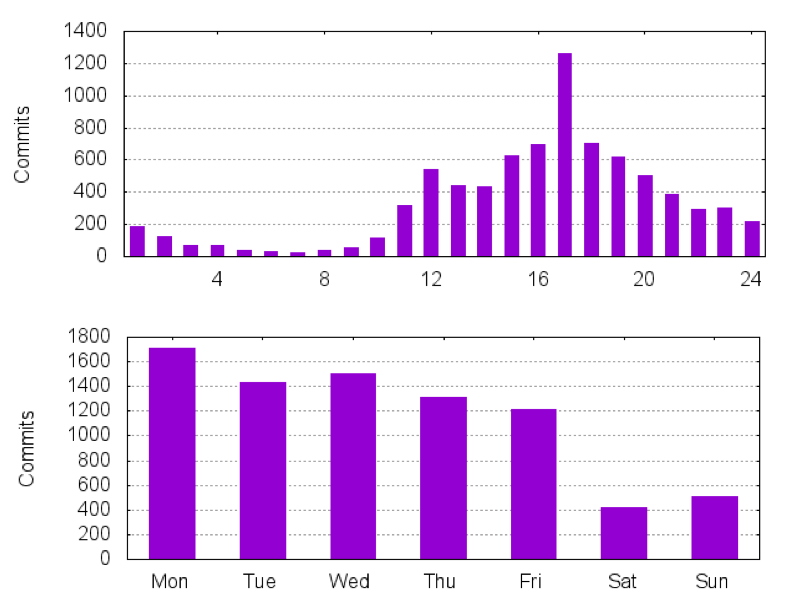
We will also look at some interesting stats, including that the busiest days for Flink are Mondays (who would have thought :-).
Community growth #
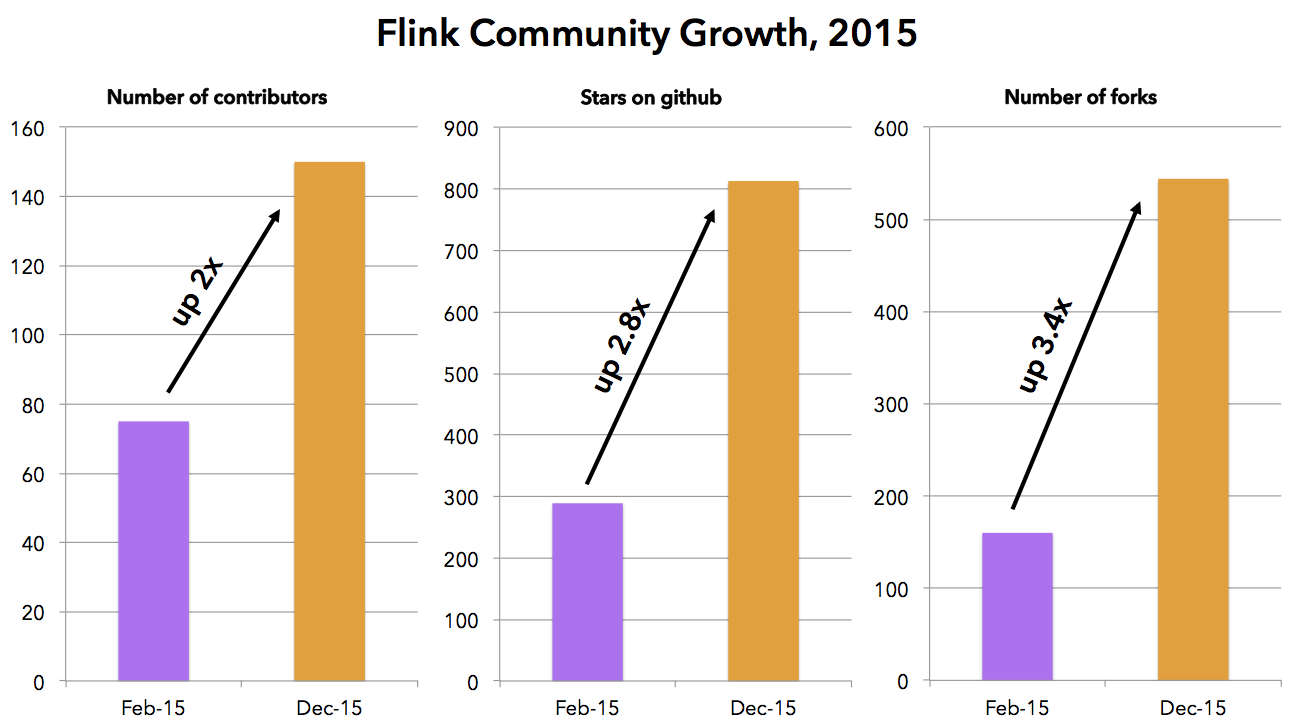
Let us start with some simple statistics from Flink’s github repository. During 2015, the Flink community doubled in size, from about 75 contributors to over 150. Forks of the repository more than tripled from 160 in February 2015 to 544 in December 2015, and the number of stars of the repository almost tripled from 289 to 813.
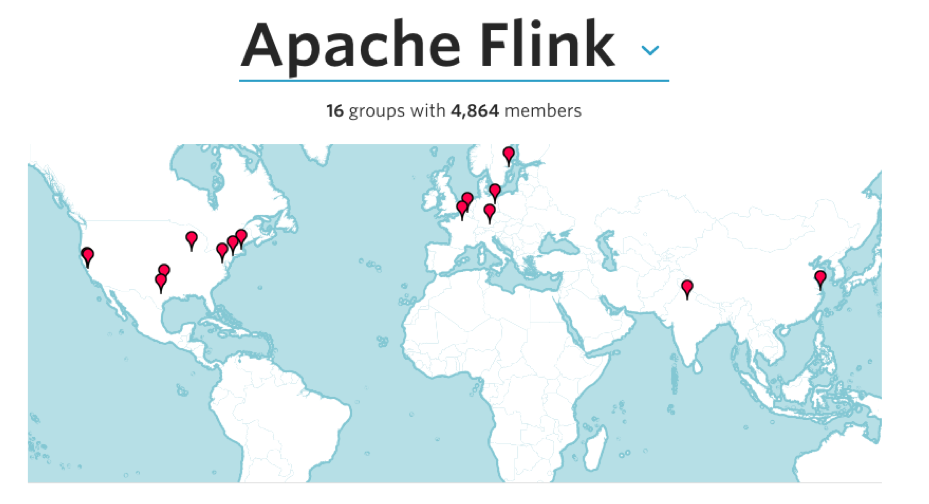
Although Flink started out geographically in Berlin, Germany, the community is by now spread all around the globe, with many contributors from North America, Europe, and Asia. A simple search at meetup.com for groups that mention Flink as a focus area reveals 16 meetups around the globe:
Flink Forward 2015 #
One of the highlights of the year for Flink was undoubtedly the Flink Forward conference, the first conference on Apache Flink that was held in October in Berlin. More than 250 participants (roughly half based outside Germany where the conference was held) attended more than 33 technical talks from organizations including Google, MongoDB, Bouygues Telecom, NFLabs, Euranova, RedHat, IBM, Huawei, Intel, Ericsson, Capital One, Zalando, Amadeus, the Otto Group, and ResearchGate. If you have not yet watched their talks, check out the slides and videos from Flink Forward.

Media coverage #
And of course, interest in Flink was picked up by the tech media. During 2015, articles about Flink appeared in InfoQ, ZDNet, Datanami, Infoworld (including being one of the best open source big data tools of 2015), the Gartner blog, Dataconomy, SDTimes, the MapR blog, KDnuggets, and HadoopSphere.

It is interesting to see that Hadoop Summit EMEA 2016 had a whopping number of 17 (!) talks submitted that are mentioning Flink in their title and abstract:

Fun with stats: when do committers commit? #
To get some deeper insight on what is happening in the Flink community, let us do some analytics on the git log of the project :-) The easiest thing we can do is count the number of commits at the repository in 2015. Running
git log --pretty=oneline --after=1/1/2015 | wc -l
on the Flink repository yields a total of 2203 commits in 2015.
To dig deeper, we will use an open source tool called gitstats that will give us some interesting statistics on the committer behavior. You can create these also yourself and see many more by following four easy steps:
- Download gitstats from the project homepage.. E.g., on OS X with homebrew, type
brew install --HEAD homebrew/head-only/gitstats
- Clone the Apache Flink git repository:
git clone git@github.com:apache/flink.git
- Generate the statistics
gitstats flink/ flink-stats/
- View all the statistics as an html page using your favorite browser (e.g., chrome):
chrome flink-stats/index.html
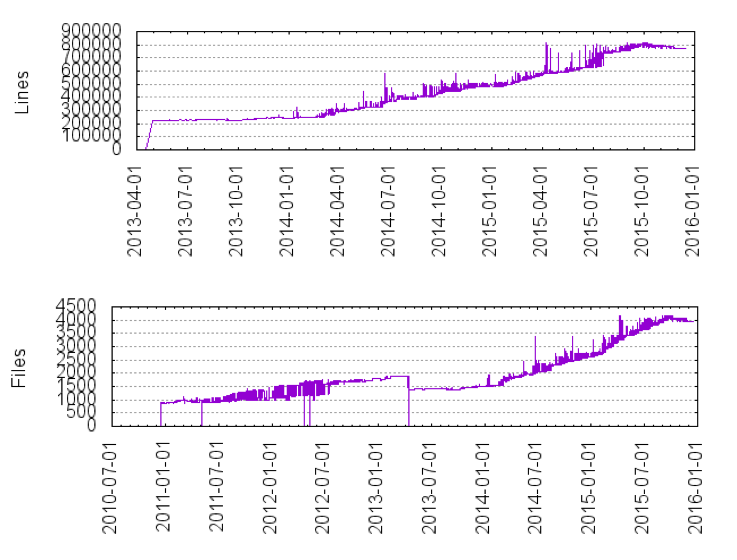
First, we can see a steady growth of lines of code in Flink since the initial Apache incubator project. During 2015, the codebase almost doubled from 500,000 LOC to 900,000 LOC.
It is interesting to see when committers commit. For Flink, Monday afternoons are by far the most popular times to commit to the repository:
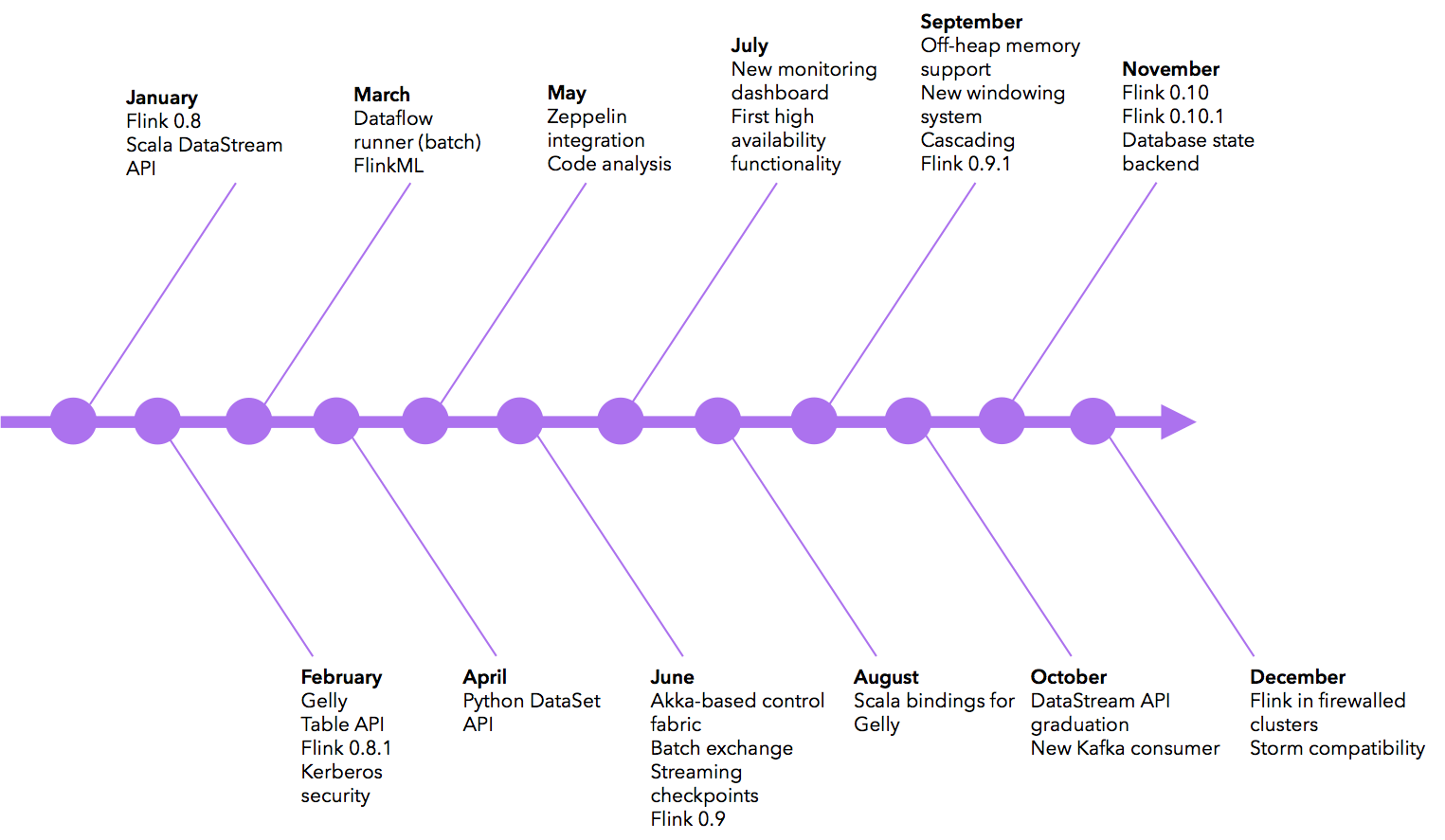
Feature timeline #
So, what were the major features added to Flink and the Flink ecosystem during 2015? Here is a (non-exhaustive) chronological list:
Roadmap for 2016 #
With 2015 coming to a close, the Flink community has already started discussing Flink’s roadmap for the future. Some highlights are:
-
Runtime scaling of streaming jobs: streaming jobs are running forever, and need to react to a changing environment. Runtime scaling means dynamically increasing and decreasing the parallelism of a job to sustain certain SLAs, or react to changing input throughput.
-
SQL queries for static data sets and streams: building on top of Flink’s Table API, users should be able to write SQL queries for static data sets, as well as SQL queries on data streams that continuously produce new results.
-
Streaming operators backed by managed memory: currently, streaming operators like user-defined state and windows are backed by JVM heap objects. Moving those to Flink managed memory will add the ability to spill to disk, GC efficiency, as well as better control over memory utilization.
-
Library for detecting temporal event patterns: a common use case for stream processing is detecting patterns in an event stream with timestamps. Flink makes this possible with its support for event time, so many of these operators can be surfaced in the form of a library.
-
Support for Apache Mesos, and resource-dynamic YARN support: support for both Mesos and YARN, including dynamic allocation and release of resource for more resource elasticity (for both batch and stream processing).
-
Security: encrypt both the messages exchanged between TaskManagers and JobManager, as well as the connections for data exchange between workers.
-
More streaming connectors, more runtime metrics, and continuous DataStream API enhancements: add support for more sources and sinks (e.g., Amazon Kinesis, Cassandra, Flume, etc), expose more metrics to the user, and provide continuous improvements to the DataStream API.
If you are interested in these features, we highly encourage you to take a look at the current draft, and join the discussion on the Flink mailing lists.