Stream Processing for Everyone with SQL and Apache Flink
May 24, 2016 -The capabilities of open source systems for distributed stream processing have evolved significantly over the last years. Initially, the first systems in the field (notably Apache Storm) provided low latency processing, but were limited to at-least-once guarantees, processing-time semantics, and rather low-level APIs. Since then, several new systems emerged and pushed the state of the art of open source stream processing in several dimensions. Today, users of Apache Flink or Apache Beam can use fluent Scala and Java APIs to implement stream processing jobs that operate in event-time with exactly-once semantics at high throughput and low latency.
In the meantime, stream processing has taken off in the industry. We are witnessing a rapidly growing interest in stream processing which is reflected by prevalent deployments of streaming processing infrastructure such as Apache Kafka and Apache Flink. The increasing number of available data streams results in a demand for people that can analyze streaming data and turn it into real-time insights. However, stream data analysis requires a special skill set including knowledge of streaming concepts such as the characteristics of unbounded streams, windows, time, and state as well as the skills to implement stream analysis jobs usually against Java or Scala APIs. People with this skill set are rare and hard to find.
About six months ago, the Apache Flink community started an effort to add a SQL interface for stream data analysis. SQL is the standard language to access and process data. Everybody who occasionally analyzes data is familiar with SQL. Consequently, a SQL interface for stream data processing will make this technology accessible to a much wider audience. Moreover, SQL support for streaming data will also enable new use cases such as interactive and ad-hoc stream analysis and significantly simplify many applications including stream ingestion and simple transformations. In this blog post, we report on the current status, architectural design, and future plans of the Apache Flink community to implement support for SQL as a language for analyzing data streams.
Where did we come from? #
With the 0.9.0-milestone1 release, Apache Flink added an API to process relational data with SQL-like expressions called the Table API. The central concept of this API is a Table, a structured data set or stream on which relational operations can be applied. The Table API is tightly integrated with the DataSet and DataStream API. A Table can be easily created from a DataSet or DataStream and can also be converted back into a DataSet or DataStream as the following example shows
val execEnv = ExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(execEnv)
// obtain a DataSet from somewhere
val tempData: DataSet[(String, Long, Double)] =
// convert the DataSet to a Table
val tempTable: Table = tempData.toTable(tableEnv, 'location, 'time, 'tempF)
// compute your result
val avgTempCTable: Table = tempTable
.where('location.like("room%"))
.select(
('time / (3600 * 24)) as 'day,
'Location as 'room,
(('tempF - 32) * 0.556) as 'tempC
)
.groupBy('day, 'room)
.select('day, 'room, 'tempC.avg as 'avgTempC)
// convert result Table back into a DataSet and print it
avgTempCTable.toDataSet[Row].print()
Although the example shows Scala code, there is also an equivalent Java version of the Table API. The following picture depicts the original architecture of the Table API.
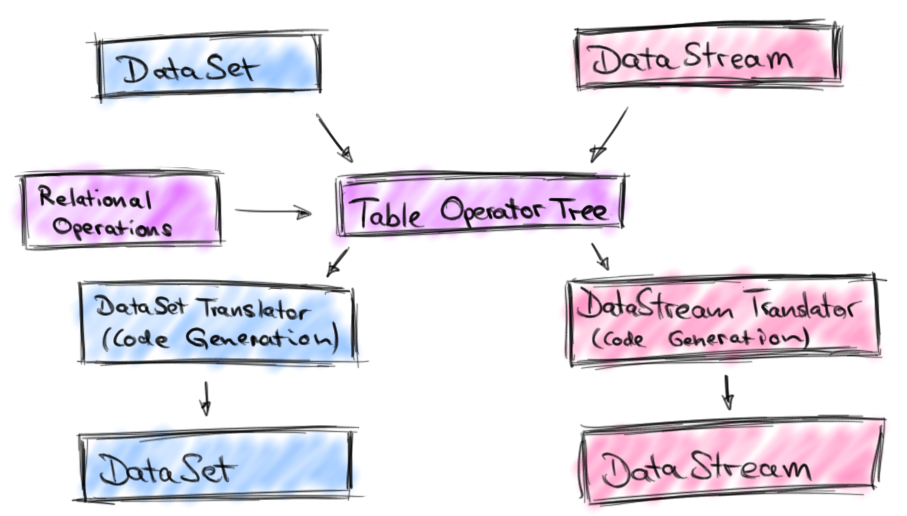
A Table is created from a DataSet or DataStream and transformed into a new Table by applying relational transformations such as filter, join, or select on them. Internally, a logical table operator tree is constructed from the applied Table transformations. When a Table is translated back into a DataSet or DataStream, the respective translator translates the logical operator tree into DataSet or DataStream operators. Expressions like 'location.like("room%") are compiled into Flink functions via code generation.
However, the original Table API had a few limitations. First of all, it could not stand alone. Table API queries had to be always embedded into a DataSet or DataStream program. Queries against batch Tables did not support outer joins, sorting, and many scalar functions which are commonly used in SQL queries. Queries against streaming tables only supported filters, union, and projections and no aggregations or joins. Also, the translation process did not leverage query optimization techniques except for the physical optimization that is applied to all DataSet programs.
Table API joining forces with SQL #
The discussion about adding support for SQL came up a few times in the Flink community. With Flink 0.9 and the availability of the Table API, code generation for relational expressions, and runtime operators, the foundation for such an extension seemed to be there and SQL support the next logical step. On the other hand, the community was also well aware of the multitude of dedicated “SQL-on-Hadoop” solutions in the open source landscape (Apache Hive, Apache Drill, Apache Impala, Apache Tajo, just to name a few). Given these alternatives, we figured that time would be better spent improving Flink in other ways than implementing yet another SQL-on-Hadoop solution.
However, with the growing popularity of stream processing and the increasing adoption of Flink in this area, the Flink community saw the need for a simpler API to enable more users to analyze streaming data. About half a year ago, we decided to take the Table API to the next level, extend the stream processing capabilities of the Table API, and add support for SQL on streaming data. What we came up with was a revised architecture for a Table API that supports SQL (and Table API) queries on streaming and static data sources. We did not want to reinvent the wheel and decided to build the new Table API on top of Apache Calcite, a popular SQL parser and optimizer framework. Apache Calcite is used by many projects including Apache Hive, Apache Drill, Cascading, and many more. Moreover, the Calcite community put SQL on streams on their roadmap which makes it a perfect fit for Flink’s SQL interface.
Calcite is central in the new design as the following architecture sketch shows:
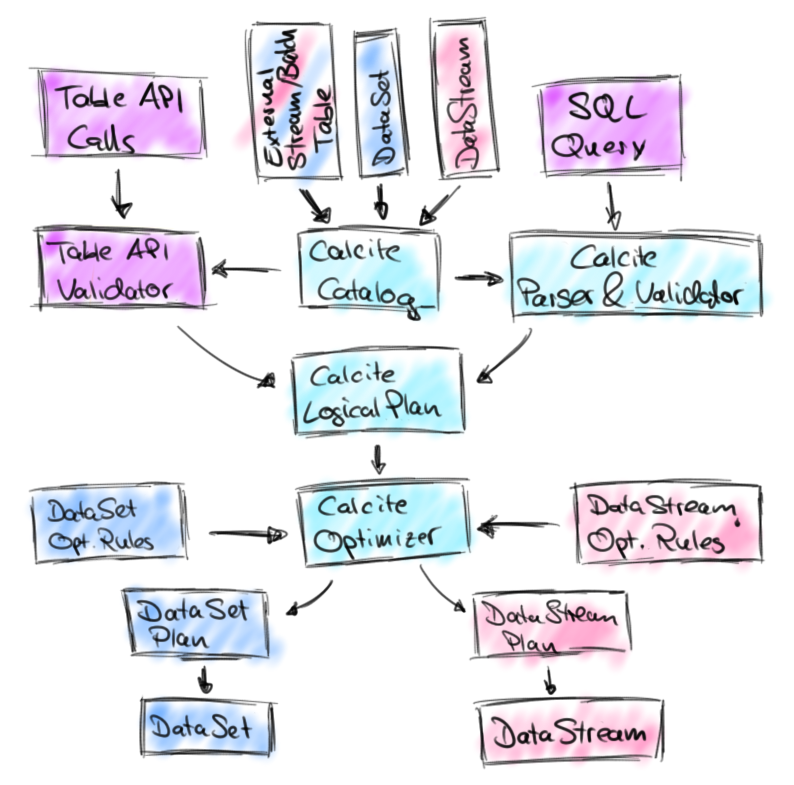
The new architecture features two integrated APIs to specify relational queries, the Table API and SQL. Queries of both APIs are validated against a catalog of registered tables and converted into Calcite’s representation for logical plans. In this representation, stream and batch queries look exactly the same. Next, Calcite’s cost-based optimizer applies transformation rules and optimizes the logical plans. Depending on the nature of the sources (streaming or static) we use different rule sets. Finally, the optimized plan is translated into a regular Flink DataStream or DataSet program. This step involves again code generation to compile relational expressions into Flink functions.
The new architecture of the Table API maintains the basic principles of the original Table API and improves it. It keeps a uniform interface for relational queries on streaming and static data. In addition, we take advantage of Calcite’s query optimization framework and SQL parser. The design builds upon Flink’s established APIs, i.e., the DataStream API that offers low-latency, high-throughput stream processing with exactly-once semantics and consistent results due to event-time processing, and the DataSet API with robust and efficient in-memory operators and pipelined data exchange. Any improvements to Flink’s core APIs and engine will automatically improve the execution of Table API and SQL queries.
With this effort, we are adding SQL support for both streaming and static data to Flink. However, we do not want to see this as a competing solution to dedicated, high-performance SQL-on-Hadoop solutions, such as Impala, Drill, and Hive. Instead, we see the sweet spot of Flink’s SQL integration primarily in providing access to streaming analytics to a wider audience. In addition, it will facilitate integrated applications that use Flink’s API’s as well as SQL while being executed on a single runtime engine.
How will Flink’s SQL on streams look like? #
So far we discussed the motivation for and architecture of Flink’s stream SQL interface, but how will it actually look like? The new SQL interface is integrated into the Table API. DataStreams, DataSets, and external data sources can be registered as tables at the TableEnvironment in order to make them queryable with SQL. The TableEnvironment.sql() method states a SQL query and returns its result as a Table. The following example shows a complete program that reads a streaming table from a JSON encoded Kafka topic, processes it with a SQL query and writes the resulting stream into another Kafka topic. Please note that the KafkaJsonSource and KafkaJsonSink are under development and not available yet. In the future, TableSources and TableSinks can be persisted to and loaded from files to ease reuse of source and sink definitions and to reduce boilerplate code.
// get environments
val execEnv = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(execEnv)
// configure Kafka connection
val kafkaProps = ...
// define a JSON encoded Kafka topic as external table
val sensorSource = new KafkaJsonSource[(String, Long, Double)](
"sensorTopic",
kafkaProps,
("location", "time", "tempF"))
// register external table
tableEnv.registerTableSource("sensorData", sensorSource)
// define query in external table
val roomSensors: Table = tableEnv.sql(
"SELECT STREAM time, location AS room, (tempF - 32) * 0.556 AS tempC " +
"FROM sensorData " +
"WHERE location LIKE 'room%'"
)
// define a JSON encoded Kafka topic as external sink
val roomSensorSink = new KafkaJsonSink(...)
// define sink for room sensor data and execute query
roomSensors.toSink(roomSensorSink)
execEnv.execute()
You might have noticed that this example left out the most interesting aspects of stream data processing: window aggregates and joins. How will these operations be expressed in SQL? Well, that is a very good question. The Apache Calcite community put out an excellent proposal that discusses the syntax and semantics of SQL on streams. It describes Calcite’s stream SQL as “an extension to standard SQL, not another ‘SQL-like’ language”. This has several benefits. First, people who are familiar with standard SQL will be able to analyze data streams without learning a new syntax. Queries on static tables and streams are (almost) identical and can be easily ported. Moreover it is possible to specify queries that reference static and streaming tables at the same time which goes well together with Flink’s vision to handle batch processing as a special case of stream processing, i.e., as processing finite streams. Finally, using standard SQL for stream data analysis means following a well established standard that is supported by many tools.
Although we haven’t completely fleshed out the details of how windows will be defined in Flink’s SQL syntax and Table API, the following examples show how a tumbling window query could look like in SQL and the Table API.
SQL (following the syntax proposal of Calcite’s streaming SQL document) #
SELECT STREAM
TUMBLE_END(time, INTERVAL '1' DAY) AS day,
location AS room,
AVG((tempF - 32) * 0.556) AS avgTempC
FROM sensorData
WHERE location LIKE 'room%'
GROUP BY TUMBLE(time, INTERVAL '1' DAY), location
Table API #
val avgRoomTemp: Table = tableEnv.ingest("sensorData")
.where('location.like("room%"))
.partitionBy('location)
.window(Tumbling every Days(1) on 'time as 'w)
.select('w.end, 'location, , (('tempF - 32) * 0.556).avg as 'avgTempCs)
What’s up next? #
The Flink community is actively working on SQL support for the next minor version Flink 1.1.0. In the first version, SQL (and Table API) queries on streams will be limited to selection, filter, and union operators. Compared to Flink 1.0.0, the revised Table API will support many more scalar functions and be able to read tables from external sources and write them back to external sinks. A lot of work went into reworking the architecture of the Table API and integrating Apache Calcite.
In Flink 1.2.0, the feature set of SQL on streams will be significantly extended. Among other things, we plan to support different types of window aggregates and maybe also streaming joins. For this effort, we want to closely collaborate with the Apache Calcite community and help extending Calcite’s support for relational operations on streaming data when necessary.
If this post made you curious and you want to try out Flink’s SQL interface and the new Table API, we encourage you to do so! Simply clone the SNAPSHOT master branch and check out the Table API documentation for the SNAPSHOT version. Please note that the branch is under heavy development, and hence some code examples in this blog post might not work. We are looking forward to your feedback and welcome contributions.