Batch as a Special Case of Streaming and Alibaba's contribution of Blink
February 13, 2019 - Stephan Ewen (@stephanewen) Fabian Hueske (@fhueske) Xiaowei Jiang (@XiaoweiJ)Last week, we broke the news that Alibaba decided to contribute its Flink-fork, called Blink, back to the Apache Flink project. Why is that a big thing for Flink, what will it mean for users and the community, and how does it fit into Flink’s overall vision? Let’s take a step back to understand this better…
A Unified Approach to Batch and Streaming #
Since its early days, Apache Flink has followed the philosophy of taking a unified approach to batch and streaming data processing. The core building block is “continuous processing of unbounded data streams”: if you can do that, you can also do offline processing of bounded data sets (batch processing use cases), because these are just streams that happen to end at some point.
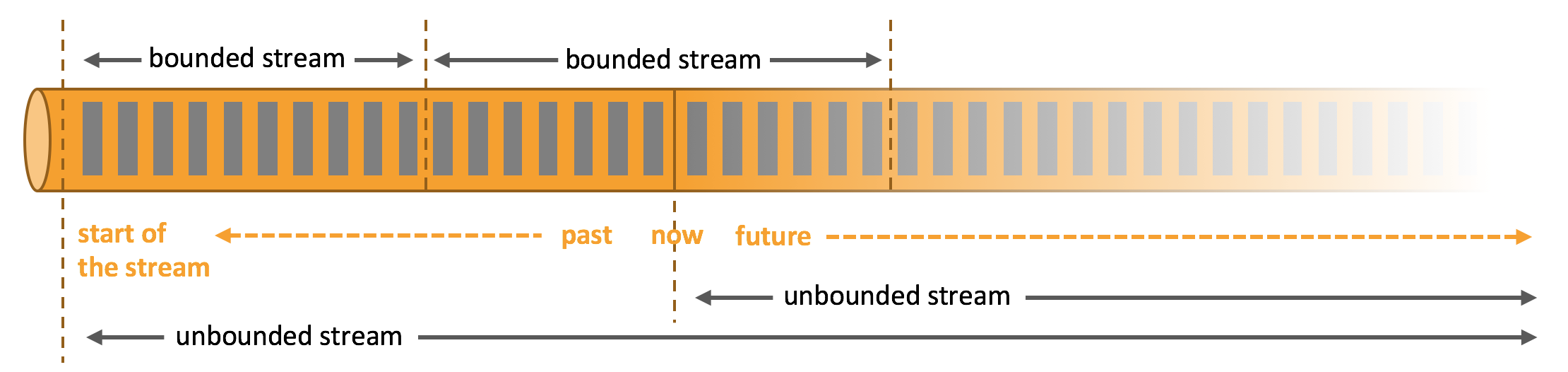
The “streaming first, with batch as a special case of streaming” philosophy is supported by various projects (for example Flink, Beam, etc.) and often been cited as a powerful way to build data applications that generalize across real-time and offline processing and to help greatly reduce the complexity of data infrastructures.
Why are there still batch processors? #
However, “batch is just a special case of streaming” does not mean that any stream processor is now the right tool for your batch processing use cases - the introduction of stream processors did not render batch processors obsolete:
-
Pure stream processing systems are very slow at batch processing workloads. No one would consider it a good idea to use a stream processor that shuffles through message queues to analyze large amounts of available data.
-
Unified APIs like Apache Beam often delegate to different runtimes depending on whether the data is continuous/unbounded of fix/bounded. For example, the implementations of the batch and streaming runtime of Google Cloud Dataflow are different, to get the desired performance and resilience in each case.
-
Apache Flink has a streaming API that can do bounded/unbounded use cases, but still offers a separate DataSet API and runtime stack that is faster for batch use cases.
What is the reason for the above? Where did “batch is just a special case of streaming” go wrong?
The answer is simple, nothing is wrong with that paradigm. Unifying batch and streaming in the API is one aspect. One needs to also exploit certain characteristics of the special case “bounded data” in the runtime to competitively handle batch processing use cases. After all, batch processors have been built specifically for that special case.
Batch on top of a Streaming Runtime #
We always believed that it is possible to have a runtime that is state-of-the-art for both stream processing and batch processing use cases at the same time. A runtime that is streaming-first, but can exploit just the right amount of special properties of bounded streams to be as fast for batch use cases as dedicated batch processors. This is the unique approach that Flink takes.
Apache Flink has a network stack that supports both low-latency/high-throughput streaming data exchanges, as well as high-throughput batch shuffles. Flink has streaming runtime operators for many operations, but also specialized operators for bounded inputs, which get used when you choose the DataSet API or select the batch environment in the Table API.
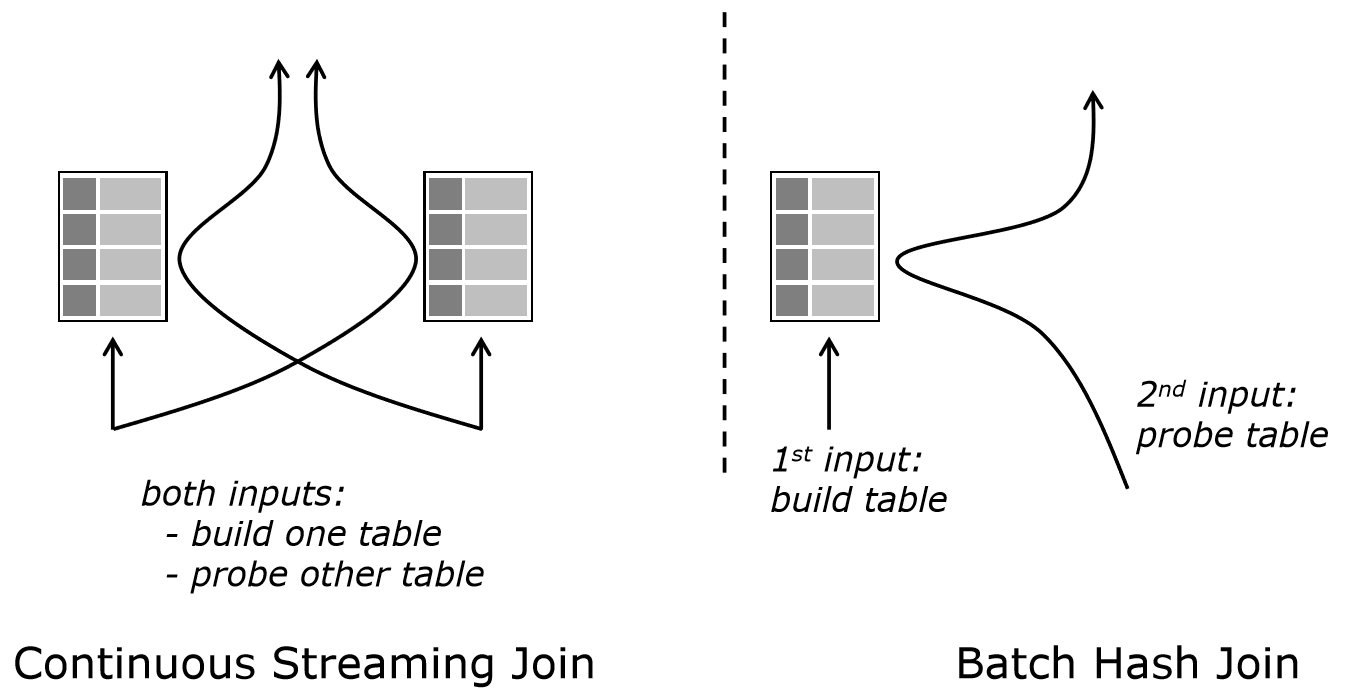
The figure illustrates a streaming join and a batch join. The batch join can read one input fully into a hash table and then probe with the other input. The stream join needs to build tables for both sides, because it needs to continuously process both inputs. For data larger than memory, the batch join can partition both data sets into subsets that fit in memory (data hits disk once) whereas the continuous nature of the stream join requires it to always keep all data in the table and repeatedly hit disk on cache misses.
Because of that, Apache Flink has been actually demonstrating some pretty impressive batch processing performance since its early days. The below benchmark is a bit older, but validated our architectural approach early on.
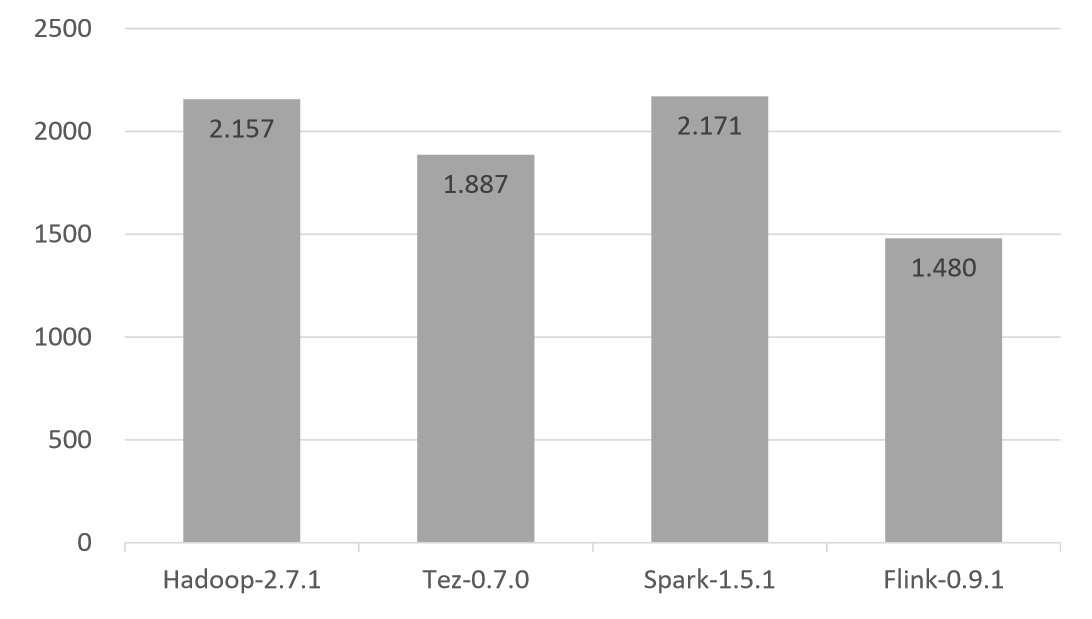
Time to sort 3.2 TB (80 GB/node), in seconds
(Presentation by Dongwon Kim, Flink Forward Berlin 2015.)
What is still missing? #
To conclude the approach and make Flink’s experience on bounded data (batch) state-of-the-art, we need to add a few more enhancements. We believe that these features are key to realizing our vision:
(1) A truly unified runtime operator stack: Currently the bounded and unbounded operators have a different network and threading model and don’t mix and match. The original reason was that batch operators followed a “pull model” (easier for batch algorithms), while streaming operators followed a “push model” (better latency/throughput characteristics). In a unified stack, continuous streaming operators are the foundation. When operating on bounded data without latency constraints, the API or the query optimizer can select from a larger set of operators. The optimizer can pick, for example, a specialized join operator that first consumes one input stream entirely before reading the second input stream.
(2) Exploiting bounded streams to reduce the scope of fault tolerance: When input data is bounded, it is possible to completely buffer data during shuffles (memory or disk) and replay that data after a failure. This makes recovery more fine grained and thus much more efficient.
(3) Exploiting bounded stream operator properties for scheduling: A continuous unbounded streaming application needs (by definition) all operators running at the same time. An application on bounded data can schedule operations after another, depending on how the operators consume data (e.g., first build hash table, then probe hash table). This increases resource efficiency.
(4) Enabling these special case optimizations for the DataStream API: Currently, only the Table API (which is unified across bounded/unbounded streams) activates these optimizations when working on bounded data.
(5) Performance and coverage for SQL: SQL is the de-facto standard data language, and while it is also being rapidly adopted for continuous streaming use cases, there is absolutely no way past it for bounded/batch use cases. To be competitive with the best batch engines, Flink needs more coverage and performance for the SQL query execution. While the core data-plane in Flink is high performance, the speed of SQL execution ultimately depends a lot also on optimizer rules, a rich set of operators, and features like code generation.
Enter Blink #
Blink is a fork of Apache Flink, originally created inside Alibaba to improve Flink’s behavior for internal use cases. Blink adds a series of improvements and integrations (see the Readme for details), many of which fall into the category of improved bounded-data/batch processing and SQL. In fact, of the above list of features for a unified batch/streaming system, Blink implements significant steps forward in all except (4):
Unified Stream Operators: Blink extends the Flink streaming runtime operator model to support selectively reading from different inputs, while keeping the push model for very low latency. This control over the inputs helps to now support algorithms like hybrid hash-joins on the same operator and threading model as continuous symmetric joins through RocksDB. These operators also form the basis for future features like “Side Inputs”.
Table API & SQL Query Processor: The SQL query processor is the component that evolved the changed most compared to the latest Flink master branch:
-
While Flink currently translates queries either into DataSet or DataStream programs (depending on the characteristics of their inputs), Blink translates queries to a data flow of the aforementioned stream operators.
-
Blink adds many more runtime operators for common SQL operations like semi-joins, anti-joins, etc.
-
The query planner (optimizer) is still based on Apache Calcite, but has many more optimization rules (incl. join reordering) and uses a proper cost model for planning.
-
Stream operators are more aggressively chained.
-
The common data structures (sorters, hash tables) and serializers are extended to go even further in operating on binary data and saving serialization overhead. Code generation is used for the row serializers.
Improved Scheduling and Failure Recovery: Finally, Blink implements several improvements for task scheduling and fault tolerance. The scheduling strategies use resources better by exploiting how the operators process their input data. The failover strategies recover more fine-grained along the boundaries of persistent shuffles. A failed JobManager can be replaced without restarting a running application.
The changes in Blink result in a big improvement in performance. The below numbers were reported by the developers of Blink to give a rough impression of the performance gains.
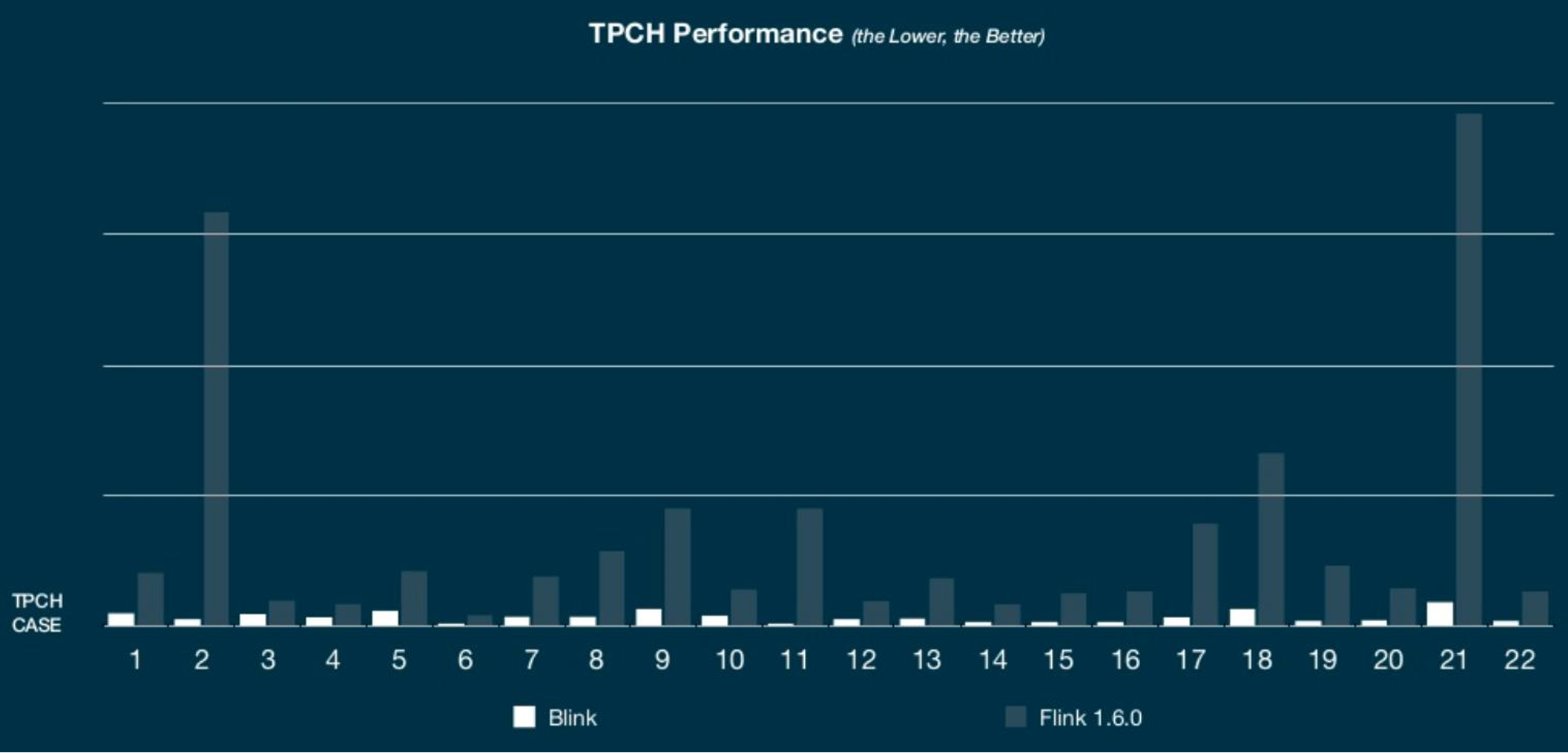
Relative performance of Blink versus Flink 1.6.0 in the TPC-H benchmark, query by query.
The performance improvement is in average 10x.
Presentation by Xiaowei Jiang at Flink Forward Berlin, 2018.)
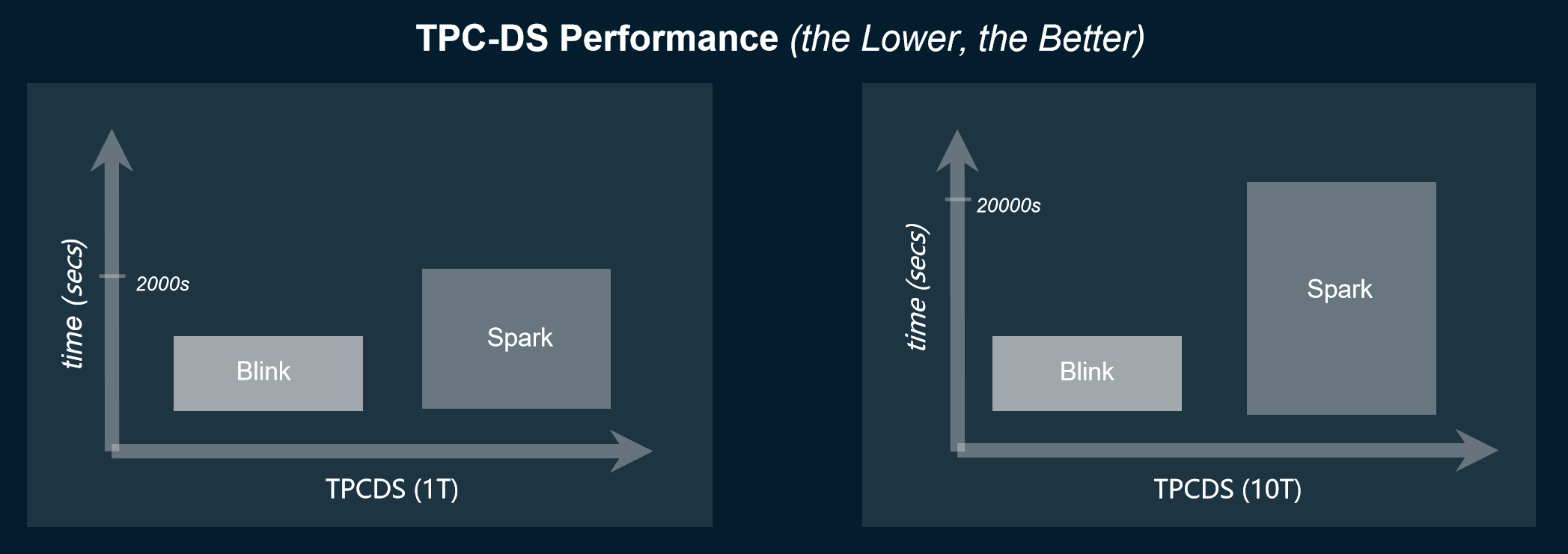
Performance of Blink versus Spark in the TPC-DS benchmark, aggregate time for all queries together.
Presentation by Xiaowei Jiang at Flink Forward Beijing, 2018.
How do we plan to merge Blink and Flink? #
Blink’s code is currently available as a branch in the Apache Flink repository. It is a challenge to merge a such big amount of changes, while making the merge process as non-disruptive as possible and keeping public APIs as stable as possible.
The community’s merge plan focuses initially on the bounded/batch processing features mentioned above and follows the following approach to ensure a smooth integration:
-
To merge Blink’s SQL/Table API query processor enhancements, we exploit the fact that both Flink and Blink have the same APIs: SQL and the Table API. Following some restructuring of the Table/SQL module (FLIP-32) we plan to merge the Blink query planner (optimizer) and runtime (operators) as an additional query processor next to the current SQL runtime. Think of it as two different runners for the same APIs.
Initially, users will be able to select which query processor to use. After a transition period in which the new query processor will be developed to subsume the current query processor, the current processor will most likely be deprecated and eventually dropped. Given that SQL is such a well defined interface, we anticipate that this transition has little friction for users. Mostly a pleasant surprise to have broader SQL feature coverage and a boost in performance. -
To support the merge of Blink’s enhancements to scheduling and recovery for jobs on bounded data, the Flink community is already working on refactoring its current schedule and adding support for pluggable scheduling and fail-over strategies.
Once this effort is finished, we can add Blink’s scheduling and recovery strategies as a new scheduling strategy that is used by the new query processor. Eventually, we plan to use the new scheduling strategy also for bounded DataStream programs. -
The extended catalog support, DDL support, as well as support for Hive’s catalog and integrations is currently going through separate design discussions. We plan to leverage existing code here whenever it makes sense.
Summary #
We believe that the data processing stack of the future is based on stream processing: The elegance of stream processing with its ability to model offline processing (batch), real-time data processing, and event-driven applications in the same way, while offering high performance and consistency is simply too compelling.
Exploiting certain properties of bounded data is important for a stream processor to achieve the same performance as dedicated batch processors. While Flink always supported batch processing, the project is taking the next step in building a unified runtime and towards becoming a stream processor that is competitive with batch processing systems even on their home turf: OLAP SQL. The contribution of Alibaba’s Blink code helps the Flink community to pick up the speed on this development.