The State Processor API: How to Read, write and modify the state of Flink applications
September 13, 2019 - Seth Wiesman (@sjwiesman) Fabian Hueske (@fhueske)Whether you are running Apache FlinkⓇ in production or evaluated Flink as a computation framework in the past, you’ve probably found yourself asking the question: How can I access, write or update state in a Flink savepoint? Ask no more! Apache Flink 1.9.0 introduces the State Processor API, a powerful extension of the DataSet API that allows reading, writing and modifying state in Flink’s savepoints and checkpoints.
In this post, we explain why this feature is a big step for Flink, what you can use it for, and how to use it. Finally, we will discuss the future of the State Processor API and how it aligns with our plans to evolve Flink into a system for unified batch and stream processing.
Stateful Stream Processing with Apache Flink until Flink 1.9 #
All non-trivial stream processing applications are stateful and most of them are designed to run for months or years. Over time, many of them accumulate a lot of valuable state that can be very expensive or even impossible to rebuild if it gets lost due to a failure. In order to guarantee the consistency and durability of application state, Flink featured a sophisticated checkpointing and recovery mechanism from very early on. With every release, the Flink community has added more and more state-related features to improve checkpointing and recovery speed, the maintenance of applications, and practices to manage applications.
However, a feature that was commonly requested by Flink users was the ability to access the state of an application “from the outside”. This request was motivated by the need to validate or debug the state of an application, to migrate the state of an application to another application, to evolve an application from the Heap State Backend to the RocksDB State Backend, or to import the initial state of an application from an external system like a relational database.
Despite all those convincing reasons to expose application state externally, your access options have been fairly limited until now. Flink’s Queryable State feature only supports key-lookups (point queries) and does not guarantee the consistency of returned values (the value of a key might be different before and after an application recovered from a failure). Moreover, queryable state cannot be used to add or modify the state of an application. Also, savepoints, which are consistent snapshots of an application’s state, were not accessible because the application state is encoded with a custom binary format.
Reading and Writing Application State with the State Processor API #
The State Processor API that comes with Flink 1.9 is a true game-changer in how you can work with application state! In a nutshell, it extends the DataSet API with Input and OutputFormats to read and write savepoint or checkpoint data. Due to the interoperability of DataSet and Table API, you can even use relational Table API or SQL queries to analyze and process state data.
For example, you can take a savepoint of a running stream processing application and analyze it with a DataSet batch program to verify that the application behaves correctly. Or you can read a batch of data from any store, preprocess it, and write the result to a savepoint that you use to bootstrap the state of a streaming application. It’s also possible to fix inconsistent state entries now. Finally, the State Processor API opens up many ways to evolve a stateful application that were previously blocked by parameter and design choices that could not be changed without losing all the state of the application after it was started. For example, you can now arbitrarily modify the data types of states, adjust the maximum parallelism of operators, split or merge operator state, re-assign operator UIDs, and so on.
Mapping Application State to DataSets #
The State Processor API maps the state of a streaming application to one or more data sets that can be separately processed. In order to be able to use the API, you need to understand how this mapping works.
But let’s first have a look at what a stateful Flink job looks like. A Flink job is composed of operators, typically one or more source operators, a few operators for the actual processing, and one or more sink operators. Each operator runs in parallel in one or more tasks and can work with different types of state. An operator can have zero, one, or more “operator states” which are organized as lists that are scoped to the operator’s tasks. If the operator is applied on a keyed stream, it can also have zero, one, or more “keyed states” which are scoped to a key that is extracted from each processed record. You can think of keyed state as a distributed key-value map.
The following figure shows the application “MyApp” which consists of three operators called “Src”, “Proc”, and “Snk”. Src has one operator state (os1), Proc has one operator state (os2) and two keyed states (ks1, ks2) and Snk is stateless.
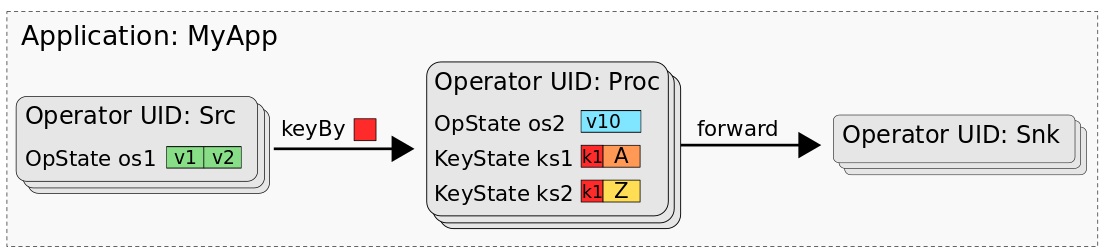
A savepoint or checkpoint of MyApp consists of the data of all states, organized in a way that the states of each task can be restored. When processing the data of a savepoint (or checkpoint) with a batch job, we need a mental model that maps the data of the individual tasks’ states into data sets or tables. In fact, we can think of a savepoint as a database. Every operator (identified by its UID) represents a namespace. Each operator state of an operator is mapped to a dedicated table in the namespace with a single column that holds the state’s data of all tasks. All keyed states of an operator are mapped to a single table consisting of a column for the key, and one column for each keyed state. The following figure shows how a savepoint of MyApp is mapped to a database.
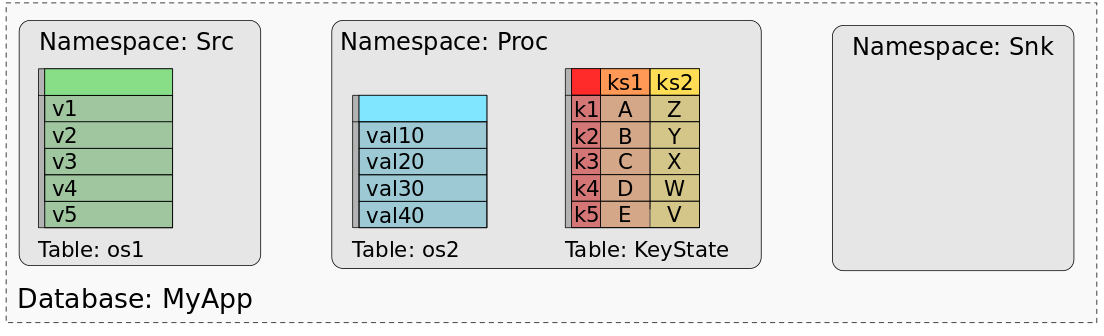
The figure shows how the values of Src’s operator state are mapped to a table with one column and five rows, one row for all list entries across all parallel tasks of Src. Operator state os2 of the operator “Proc” is similarly mapped to an individual table. The keyed states ks1 and ks2 are combined to a single table with three columns, one for the key, one for ks1 and one for ks2. The keyed table holds one row for each distinct key of both keyed states. Since the operator “Snk” does not have any state, its namespace is empty.
The State Processor API now offers methods to create, load, and write a savepoint. You can read a DataSet from a loaded savepoint or convert a DataSet into a state and add it to a savepoint. DataSets can be processed with the full feature set of the DataSet API. With these building blocks, all of the before-mentioned use cases (and more) can be addressed. Please have a look at the documentation if you’d like to learn how to use the State Processor API in detail.
Why DataSet API? #
In case you are familiar with Flink’s roadmap, you might be surprised that the State Processor API is based on the DataSet API. The Flink community plans to extend the DataStream API with the concept of BoundedStreams and deprecate the DataSet API. When designing this feature, we also evaluated the DataStream API or Table API but neither could provide the right feature set yet. Since we didn’t want to block this feature on the progress of Flink’s APIs, we decided to build it on the DataSet API, but kept its dependencies on the DataSet API to a minimum. Hence, migrating it to another API should be fairly easy.
Summary #
Flink users have requested a feature to access and modify the state of streaming applications from the outside for a long time. With the State Processor API, Flink 1.9.0 finally exposes application state as a data format that can be manipulated. This feature opens up many new possibilities for how users can maintain and manage Flink streaming applications, including arbitrary evolution of stream applications and exporting and bootstrapping of application state. To put it concisely, the State Processor API unlocks the black box that savepoints used to be.