Running Apache Flink on Kubernetes with KUDO
November 6, 2019 - Gerred DillonA common use case for Apache Flink is streaming data analytics together with Apache Kafka, which provides a pub/sub model and durability for data streams. To achieve elastic scalability, both are typically deployed in clustered environments, and increasingly on top of container orchestration platforms like Kubernetes. The Operator pattern provides an extension mechanism to Kubernetes that captures human operator knowledge about an application, like Flink, in software to automate its operation. KUDO is an open source toolkit for building Operators using declarative YAML specs, with a focus on ease of use for cluster admins and developers.
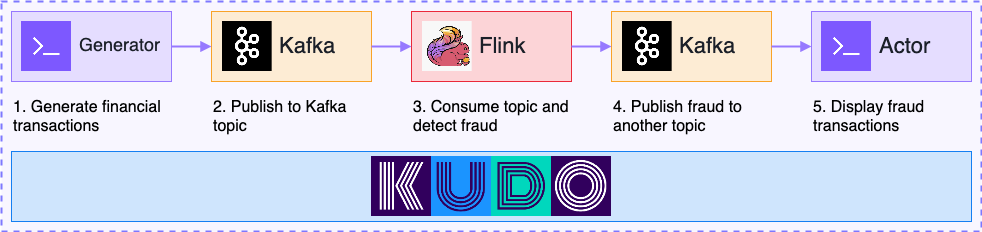
In this blog post we demonstrate how to orchestrate a streaming data analytics application based on Flink and Kafka with KUDO. It consists of a Flink job that checks financial transactions for fraud, and two microservices that generate and display the transactions. You can find more details about this demo in the KUDO Operators repository, including instructions for installing the dependencies.
Prerequisites #
You can run this demo on your local machine using minikube. The instructions below were tested with minikube v1.5.1 and Kubernetes v1.16.2 but should work on any Kubernetes version above v1.15.0. First, start a minikube cluster with enough capacity:
minikube start --cpus=6 --memory=9216 --disk-size=10g
If you’re using a different way to provision Kubernetes, make sure you have at least 6 CPU Cores, 9 GB of RAM and 10 GB of disk space available.
Install the kubectl CLI tool. The KUDO CLI is a plugin for the Kubernetes CLI. The official instructions for installing and setting up kubectl are here.
Next, let’s install the KUDO CLI. At the time of this writing, the latest KUDO version is v0.10.0. You can find the CLI binaries for download here. Download the kubectl-kudo binary for your OS and architecture.
If you’re using Homebrew on MacOS, you can install the CLI via:
$ brew tap kudobuilder/tap
$ brew install kudo-cli
Now, let’s initialize KUDO on our Kubernetes cluster:
$ kubectl kudo init
$KUDO_HOME has been configured at /Users/gerred/.kudo
This will create several resources. First, it will create the Custom Resource Definitions, service account, and role bindings necessary for KUDO to operate. It will also create an instance of the KUDO controller so that we can begin creating instances of applications.
The KUDO CLI leverages the kubectl plugin system, which gives you all its functionality under kubectl kudo. This is a convenient way to install and deal with your KUDO Operators. For our demo, we use Kafka and Flink which depend on ZooKeeper. To make the ZooKeeper Operator available on the cluster, run:
$ kubectl kudo install zookeeper --version=0.3.0 --skip-instance
The –skip-instance flag skips the creation of a ZooKeeper instance. The flink-demo Operator that we’re going to install below will create it as a dependency instead. Now let’s make the Kafka and Flink Operators available the same way:
$ kubectl kudo install kafka --version=1.2.0 --skip-instance
$ kubectl kudo install flink --version=0.2.1 --skip-instance
This installs all the Operator versions needed for our demo.
Financial Fraud Demo #
In our financial fraud demo we have two microservices, called “generator” and “actor”. The generator produces transactions with random amounts and writes them into a Kafka topic. Occasionally, the value will be over 10,000 which is considered fraud for the purpose of this demo. The Flink job subscribes to the Kafka topic and detects fraudulent transactions. When it does, it submits them to another Kafka topic which the actor consumes. The actor simply displays each fraudulent transaction.
The KUDO CLI by default installs Operators from the official repository, but it also supports installation from your local filesystem. This is useful if you want to develop your own Operator, or modify this demo for your own purposes.
First, clone the “kudobuilder/operators” repository via:
$ git clone https://github.com/kudobuilder/operators.git
Next, change into the “operators” directory and install the demo-operator from your local filesystem:
$ cd operators
$ kubectl kudo install repository/flink/docs/demo/financial-fraud/demo-operator --instance flink-demo
instance.kudo.dev/v1beta1/flink-demo created
This time we didn’t include the –skip-instance flag, so KUDO will actually deploy all the components, including Flink, Kafka, and ZooKeeper. KUDO orchestrates deployments and other lifecycle operations using plans that were defined by the Operator developer. Plans are similar to runbooks and encapsulate all the procedures required to operate the software. We can track the status of the deployment using this KUDO command:
$ kubectl kudo plan status --instance flink-demo
Plan(s) for "flink-demo" in namespace "default":
.
└── flink-demo (Operator-Version: "flink-demo-0.1.4" Active-Plan: "deploy")
└── Plan deploy (serial strategy) [IN_PROGRESS]
├── Phase dependencies [IN_PROGRESS]
│ ├── Step zookeeper (COMPLETE)
│ └── Step kafka (IN_PROGRESS)
├── Phase flink-cluster [PENDING]
│ └── Step flink (PENDING)
├── Phase demo [PENDING]
│ ├── Step gen (PENDING)
│ └── Step act (PENDING)
└── Phase flink-job [PENDING]
└── Step submit (PENDING)
The output shows that the “deploy” plan is in progress and that it consists of 4 phases: “dependencies”, “flink-cluster”, “demo” and “flink-job”. The “dependencies” phase includes steps for “zookeeper” and “kafka”. This is where both dependencies get installed, before KUDO continues to install the Flink cluster and the demo itself. We also see that ZooKeeper installation completed, and that Kafka installation is currently in progress. We can view details about Kafka’s deployment plan via:
$ kubectl kudo plan status --instance flink-demo-kafka
Plan(s) for "flink-demo-kafka" in namespace "default":
.
└── flink-demo-kafka (Operator-Version: "kafka-1.2.0" Active-Plan: "deploy")
├── Plan deploy (serial strategy) [IN_PROGRESS]
│ └── Phase deploy-kafka [IN_PROGRESS]
│ └── Step deploy (IN_PROGRESS)
└── Plan not-allowed (serial strategy) [NOT ACTIVE]
└── Phase not-allowed (serial strategy) [NOT ACTIVE]
└── Step not-allowed (serial strategy) [NOT ACTIVE]
└── not-allowed [NOT ACTIVE]
After Kafka was successfully installed the next phase “flink-cluster” will start and bring up, you guessed it, your flink-cluster. After this is done, the demo phase creates the generator and actor pods that generate and display transactions for this demo. Lastly, we have the flink-job phase in which we submit the actual FinancialFraudJob to the Flink cluster. Once the flink job is submitted, we will be able to see fraud logs in our actor pod shortly after.
After a while, the state of all plans, phases and steps will change to “COMPLETE”. Now we can view the Flink dashboard to verify that our job is running. To access it from outside the Kubernetes cluster, first start the client proxy, then open the URL below in your browser:
$ kubectl proxy
It should look similar to this, depending on your local machine and how many cores you have available:
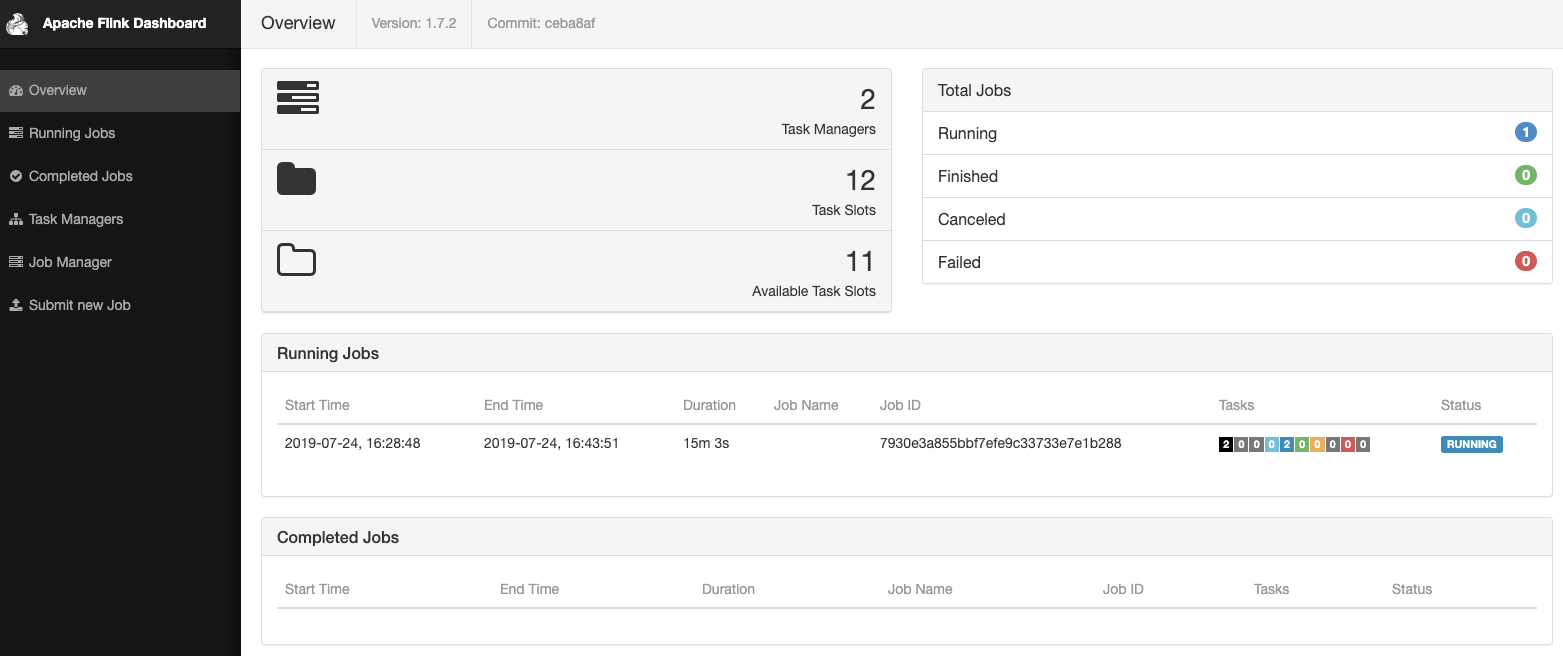
The job is up and running and we should now be able to see fraudulent transaction in the logs of the actor pod:
$ kubectl logs $(kubectl get pod -l actor=flink-demo -o jsonpath="{.items[0].metadata.name}")
Broker: flink-demo-kafka-kafka-0.flink-demo-kafka-svc:9093
Topic: fraud
Detected Fraud: TransactionAggregate {startTimestamp=0, endTimestamp=1563395831000, totalAmount=19895:
Transaction{timestamp=1563395778000, origin=1, target='3', amount=8341}
Transaction{timestamp=1563395813000, origin=1, target='3', amount=8592}
Transaction{timestamp=1563395817000, origin=1, target='3', amount=2802}
Transaction{timestamp=1563395831000, origin=1, target='3', amount=160}}
If you add the “-f” flag to the previous command, you can follow along as more transactions are streaming in and are evaluated by our Flink job.
Conclusion #
In this blog post we demonstrated how to easily deploy an end-to-end streaming data application on Kubernetes using KUDO. We deployed a Flink job and two microservices, as well as all the required infrastructure - Flink, Kafka, and ZooKeeper using just a few kubectl commands. To find out more about KUDO, visit the project website or join the community on Slack.