Advanced Flink Application Patterns Vol.1: Case Study of a Fraud Detection System
January 15, 2020 - Alexander Fedulov (@alex_fedulov)In this series of blog posts you will learn about three powerful Flink patterns for building streaming applications:
- Dynamic updates of application logic
- Dynamic data partitioning (shuffle), controlled at runtime
- Low latency alerting based on custom windowing logic (without using the window API)
These patterns expand the possibilities of what is achievable with statically defined data flows and provide the building blocks to fulfill complex business requirements.
Dynamic updates of application logic allow Flink jobs to change at runtime, without downtime from stopping and resubmitting the code.
Dynamic data partitioning provides the ability to change how events are distributed and grouped by Flink at runtime. Such functionality often becomes a natural requirement when building jobs with dynamically reconfigurable application logic.
Custom window management demonstrates how you can utilize the low level process function API, when the native window API is not exactly matching your requirements. Specifically, you will learn how to implement low latency alerting on windows and how to limit state growth with timers.
These patterns build on top of core Flink functionality, however, they might not be immediately apparent from the framework’s documentation as explaining and presenting the motivation behind them is not always trivial without a concrete use case. That is why we will showcase these patterns with a practical example that offers a real-world usage scenario for Apache Flink — a Fraud Detection engine. We hope that this series will place these powerful approaches into your tool belt and enable you to take on new and exciting tasks.
In the first blog post of the series we will look at the high-level architecture of the demo application, describe its components and their interactions. We will then deep dive into the implementation details of the first pattern in the series - dynamic data partitioning.
You will be able to run the full Fraud Detection Demo application locally and look into the details of the implementation by using the accompanying GitHub repository.
Fraud Detection Demo #
The full source code for our fraud detection demo is open source and available online. To run it locally, check out the following repository and follow the steps in the README:
https://github.com/afedulov/fraud-detection-demo
You will see the demo is a self-contained application - it only requires docker and docker-compose to be built from sources and includes the following components:
- Apache Kafka (message broker) with ZooKeeper
- Apache Flink (application cluster)
- Fraud Detection Web App
The high-level goal of the Fraud Detection engine is to consume a stream of financial transactions and evaluate them against a set of rules. These rules are subject to frequent changes and tweaks. In a real production system, it is important to be able to add and remove them at runtime, without incurring an expensive penalty of stopping and restarting the job.
When you navigate to the demo URL in your browser, you will be presented with the following UI:
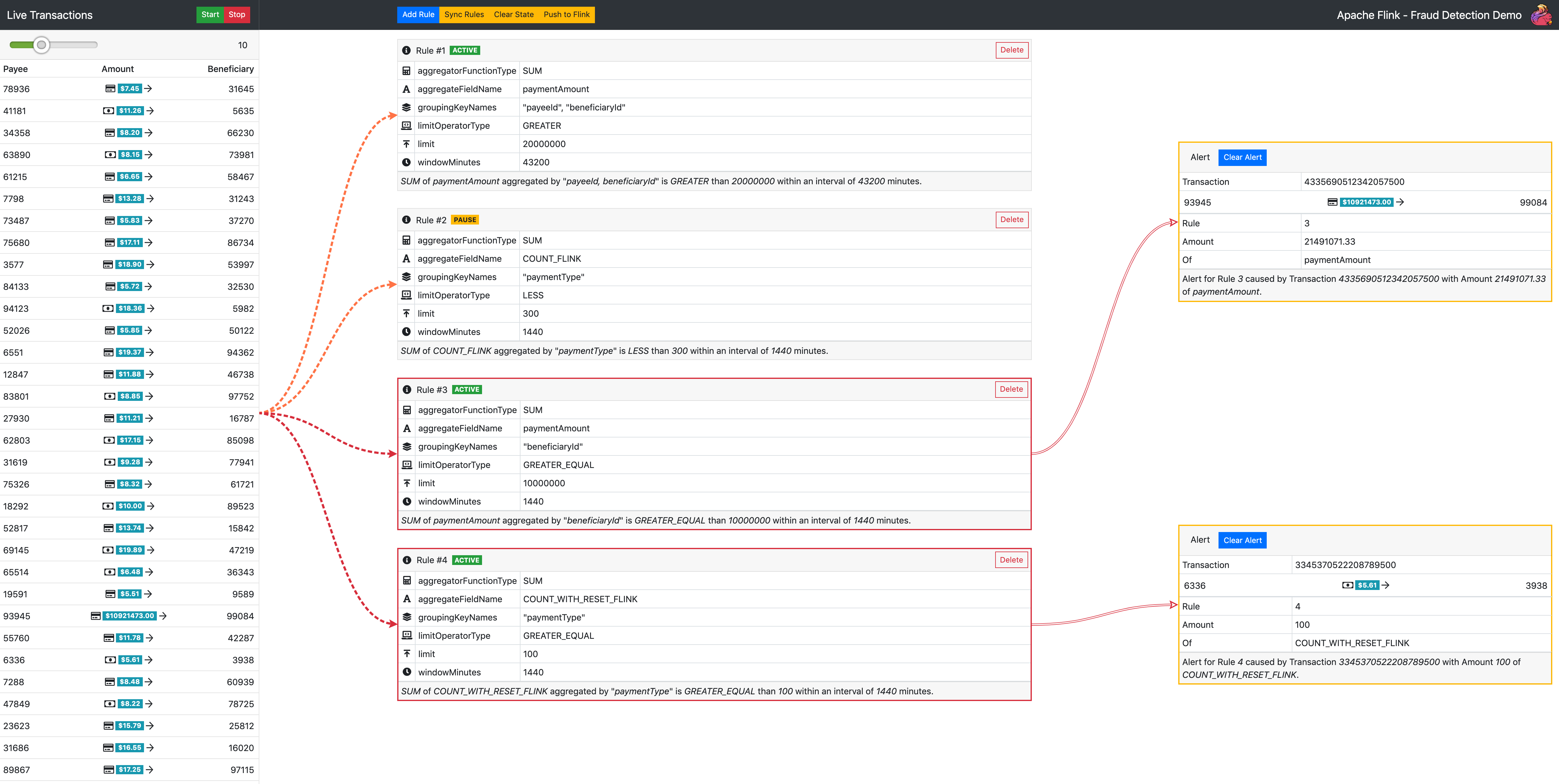
Figure 1: Fraud Detection Demo UI
On the left side, you can see a visual representation of financial transactions flowing through the system after you click the “Start” button. The slider at the top allows you to control the number of generated transactions per second. The middle section is devoted to managing the rules evaluated by Flink. From here, you can create new rules as well as issue control commands, such as clearing Flink’s state.
The demo out-of-the-box comes with a set of predefined sample rules. You can click the Start button and, after some time, will observe alerts displayed in the right section of the UI. These alerts are the result of Flink evaluating the generated transactions stream against the predefined rules.
Our sample fraud detection system consists of three main components:
- Frontend (React)
- Backend (SpringBoot)
- Fraud Detection application (Apache Flink)
Interactions between the main elements are depicted in Figure 2.
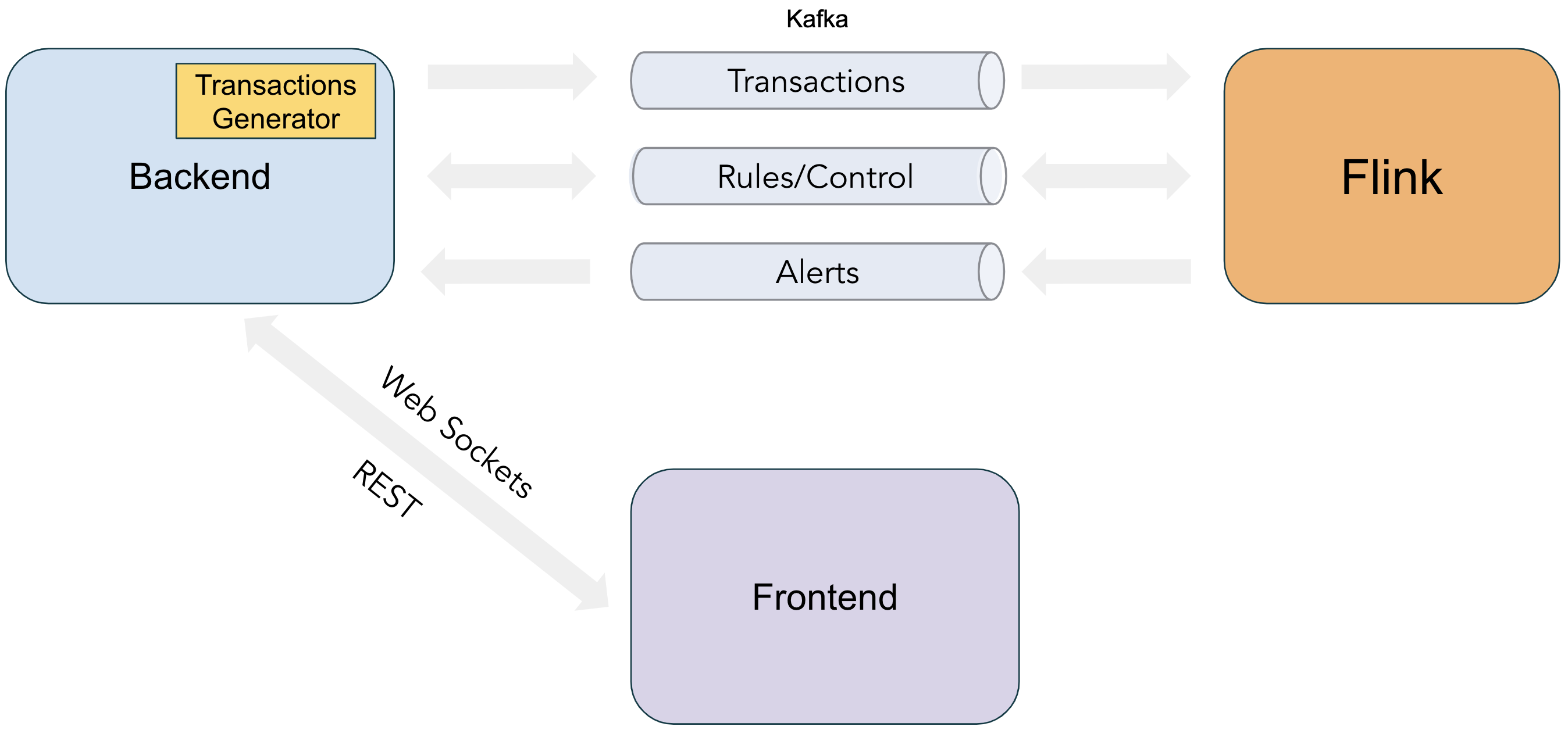
Figure 2: Fraud Detection Demo Components
The Backend exposes a REST API to the Frontend for creating/deleting rules as well as issuing control commands for managing the demo execution. It then relays those Frontend actions to Flink by sending them via a “Control” Kafka topic. The Backend additionally includes a Transactions Generator component, which sends an emulated stream of money transfer events to Flink via a separate “Transactions” topic. Alerts generated by Flink are consumed by the Backend from “Alerts” topic and relayed to the UI via WebSockets.
Now that you are familiar with the overall layout and the goal of our Fraud Detection engine, let’s now go into the details of what is required to implement such a system.
Dynamic Data Partitioning #
The first pattern we will look into is Dynamic Data Partitioning.
If you have used Flink’s DataStream API in the past, you are undoubtedly familiar with the keyBy method. Keying a stream shuffles all the records such that elements with the same key are assigned to the same partition. This means all records with the same key are processed by the same physical instance of the next operator.
In a typical streaming application, the choice of key is fixed, determined by some static field within the elements. For instance, when building a simple window-based aggregation of a stream of transactions, we might always group by the transactions account id.
DataStream<Transaction> input = // [...]
DataStream<...> windowed = input
.keyBy(Transaction::getAccountId)
.window(/*window specification*/);
This approach is the main building block for achieving horizontal scalability in a wide range of use cases. However, in the case of an application striving to provide flexibility in business logic at runtime, this is not enough. To understand why this is the case, let us start with articulating a realistic sample rule definition for our fraud detection system in the form of a functional requirement:
“Whenever the sum of the accumulated payment amount from the same payer to the same beneficiary within the duration of a week is greater than 1 000 000 $ - fire an alert.”
In this formulation we can spot a number of parameters that we would like to be able to specify in a newly-submitted rule and possibly even later modify or tweak at runtime:
- Aggregation field (payment amount)
- Grouping fields (payer + beneficiary)
- Aggregation function (sum)
- Window duration (1 week)
- Limit (1 000 000)
- Limit operator (greater)
Accordingly, we will use the following simple JSON format to define the aforementioned parameters:
{
"ruleId": 1,
"ruleState": "ACTIVE",
"groupingKeyNames": ["payerId", "beneficiaryId"],
"aggregateFieldName": "paymentAmount",
"aggregatorFunctionType": "SUM",
"limitOperatorType": "GREATER",
"limit": 1000000,
"windowMinutes": 10080
}
At this point, it is important to understand that groupingKeyNames determine the actual physical grouping of events - all Transactions with the same values of specified parameters (e.g. payer #25 -> beneficiary #12) have to be aggregated in the same physical instance of the evaluating operator. Naturally, the process of distributing data in such a way in Flink’s API is realised by a keyBy() function.
Most examples in Flink’s keyBy()documentation use a hard-coded KeySelector, which extracts specific fixed events’ fields. However, to support the desired flexibility, we have to extract them in a more dynamic fashion based on the specifications of the rules. For this, we will have to use one additional operator that prepares every event for dispatching to a correct aggregating instance.
On a high level, our main processing pipeline looks like this:
DataStream<Alert> alerts =
transactions
.process(new DynamicKeyFunction())
.keyBy(/* some key selector */);
.process(/* actual calculations and alerting */)
We have previously established that each rule defines a groupingKeyNames parameter that specifies which combination of fields will be used for the incoming events’ grouping. Each rule might use an arbitrary combination of these fields. At the same time, every incoming event potentially needs to be evaluated against multiple rules. This implies that events might simultaneously need to be present at multiple parallel instances of evaluating operators that correspond to different rules and hence will need to be forked. Ensuring such events dispatching is the purpose of DynamicKeyFunction().
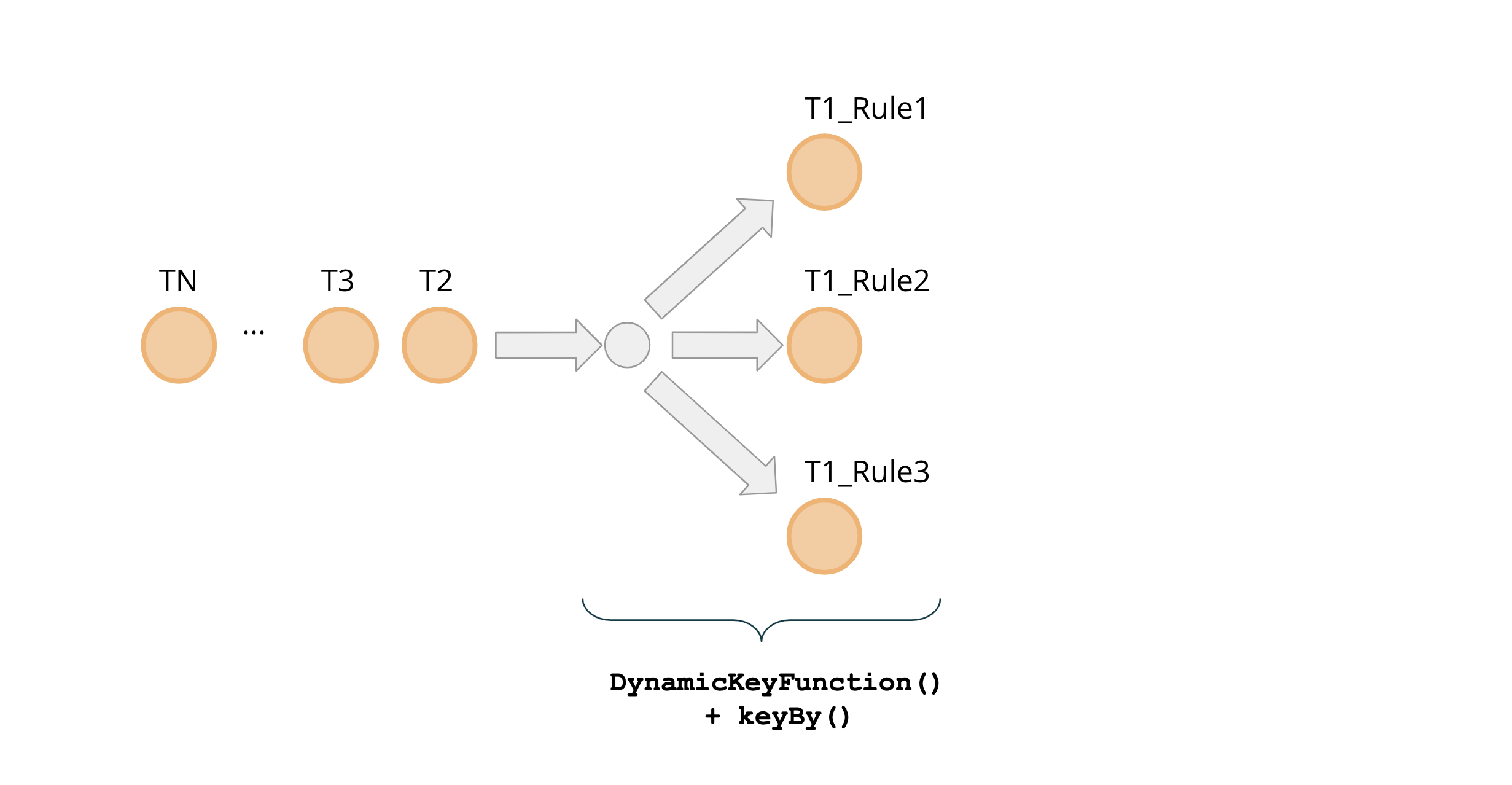
Figure 3: Forking events with Dynamic Key Function
DynamicKeyFunction iterates over a set of defined rules and prepares every event to be processed by a keyBy() function by extracting the required grouping keys:
public class DynamicKeyFunction
extends ProcessFunction<Transaction, Keyed<Transaction, String, Integer>> {
...
/* Simplified */
List<Rule> rules = /* Rules that are initialized somehow.
Details will be discussed in a future blog post. */;
@Override
public void processElement(
Transaction event,
Context ctx,
Collector<Keyed<Transaction, String, Integer>> out) {
for (Rule rule :rules) {
out.collect(
new Keyed<>(
event,
KeysExtractor.getKey(rule.getGroupingKeyNames(), event),
rule.getRuleId()));
}
}
...
}
KeysExtractor.getKey() uses reflection to extract the required values of groupingKeyNames fields from events and combines them as a single concatenated String key, e.g "{payerId=25;beneficiaryId=12}". Flink will calculate the hash of this key and assign the processing of this particular combination to a specific server in the cluster. This will allow tracking all transactions between payer #25 and beneficiary #12 and evaluating defined rules within the desired time window.
Notice that a wrapper class Keyed with the following signature was introduced as the output type of DynamicKeyFunction:
public class Keyed<IN, KEY, ID> {
private IN wrapped;
private KEY key;
private ID id;
...
public KEY getKey(){
return key;
}
}
Fields of this POJO carry the following information: wrapped is the original transaction event, key is the result of using KeysExtractor and id is the ID of the Rule that caused the dispatch of the event (according to the rule-specific grouping logic).
Events of this type will be the input to the keyBy() function in the main processing pipeline and allow the use of a simple lambda-expression as a KeySelector for the final step of implementing dynamic data shuffle.
DataStream<Alert> alerts =
transactions
.process(new DynamicKeyFunction())
.keyBy((keyed) -> keyed.getKey());
.process(new DynamicAlertFunction())
By applying DynamicKeyFunction we are implicitly copying events for performing parallel per-rule evaluation within a Flink cluster. By doing so, we achieve an important property - horizontal scalability of rules’ processing. Our system will be capable of handling more rules by adding more servers to the cluster, i.e. increasing the parallelism. This property is achieved at the cost of data duplication, which might become an issue depending on the specific set of parameters, such as incoming data rate, available network bandwidth, event payload size etc. In a real-life scenario, additional optimizations can be applied, such as combined evaluation of rules which have the same groupingKeyNames, or a filtering layer, which would strip events of all the fields that are not required for processing of a particular rule.
Summary: #
In this blog post, we have discussed the motivation behind supporting dynamic, runtime changes to a Flink application by looking at a sample use case - a Fraud Detection engine. We have described the overall architecture and interactions between its components as well as provided references for building and running a demo Fraud Detection application in a dockerized setup. We then showed the details of implementing a dynamic data partitioning pattern as the first underlying building block to enable flexible runtime configurations.
To remain focused on describing the core mechanics of the pattern, we kept the complexity of the DSL and the underlying rules engine to a minimum. Going forward, it is easy to imagine adding extensions such as allowing more sophisticated rule definitions, including filtering of certain events, logical rules chaining, and other more advanced functionality.
In the second part of this series, we will describe how the rules make their way into the running Fraud Detection engine. Additionally, we will go over the implementation details of the main processing function of the pipeline - DynamicAlertFunction().
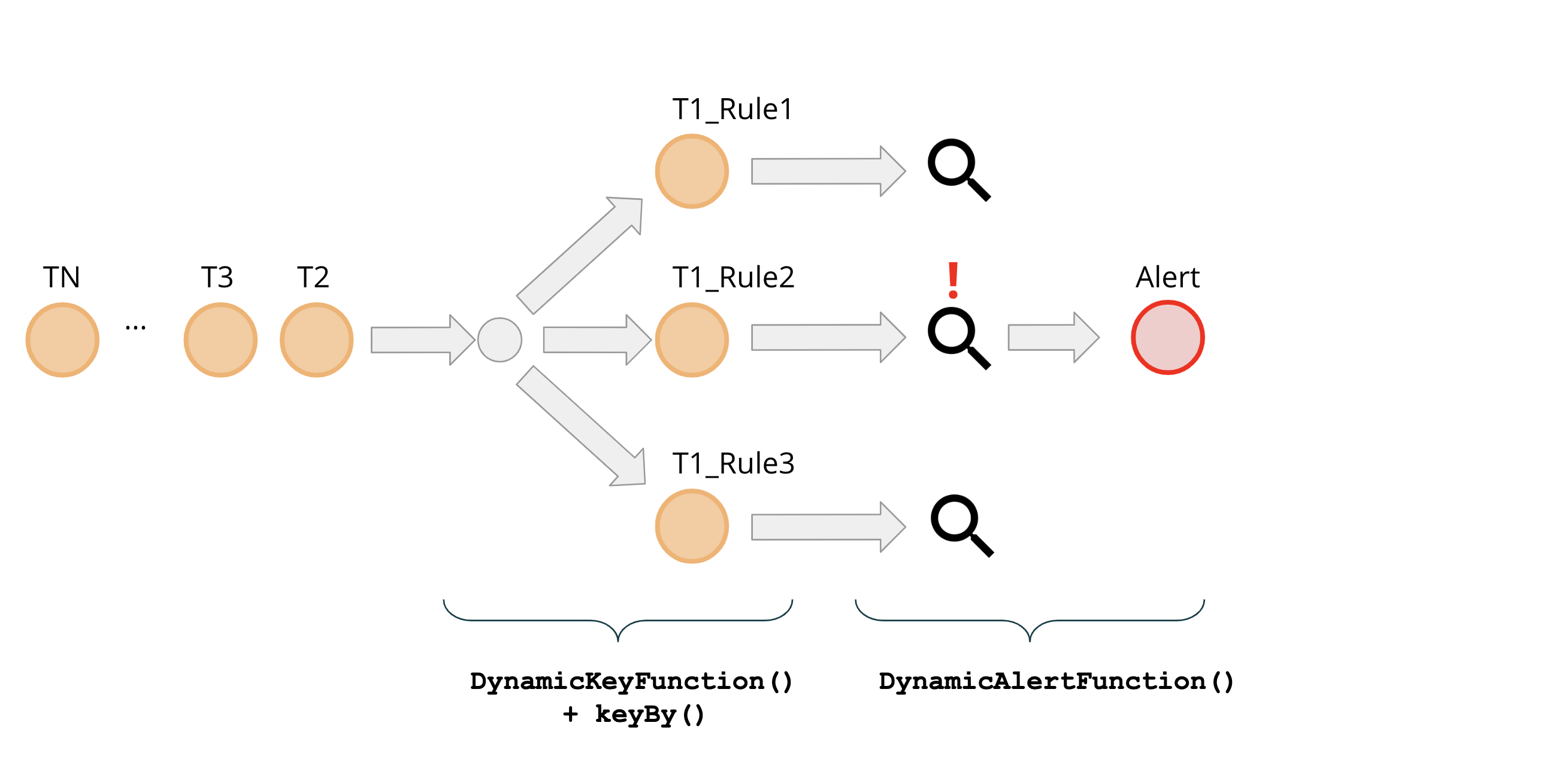
Figure 4: End-to-end pipeline
In the next article, we will see how Flink’s broadcast streams can be utilized to help steer the processing within the Fraud Detection engine at runtime (Dynamic Application Updates pattern).