Advanced Flink Application Patterns Vol.2: Dynamic Updates of Application Logic
March 24, 2020 - Alexander Fedulov (@alex_fedulov)In the first article of the series, we gave a high-level description of the objectives and required functionality of a Fraud Detection engine. We also described how to make data partitioning in Apache Flink customizable based on modifiable rules instead of using a hardcoded KeysExtractor implementation.
We intentionally omitted details of how the applied rules are initialized and what possibilities exist for updating them at runtime. In this post, we will address exactly these details. You will learn how the approach to data partitioning described in Part 1 can be applied in combination with a dynamic configuration. These two patterns, when used together, can eliminate the need to recompile the code and redeploy your Flink job for a wide range of modifications of the business logic.
Rules Broadcasting #
Let’s first have a look at the previously-defined data-processing pipeline:
DataStream<Alert> alerts =
transactions
.process(new DynamicKeyFunction())
.keyBy((keyed) -> keyed.getKey());
.process(new DynamicAlertFunction())
DynamicKeyFunction provides dynamic data partitioning while DynamicAlertFunction is responsible for executing the main logic of processing transactions and sending alert messages according to defined rules.
Vol.1 of this series simplified the use case and assumed that the applied set of rules is pre-initialized and accessible via the List<Rules> within DynamicKeyFunction.
public class DynamicKeyFunction
extends ProcessFunction<Transaction, Keyed<Transaction, String, Integer>> {
/* Simplified */
List<Rule> rules = /* Rules that are initialized somehow.*/;
...
}
Adding rules to this list is obviously possible directly inside the code of the Flink Job at the stage of its initialization (Create a List object; use it’s add method). A major drawback of doing so is that it will require recompilation of the job with each rule modification. In a real Fraud Detection system, rules are expected to change on a frequent basis, making this approach unacceptable from the point of view of business and operational requirements. A different approach is needed.
Next, let’s take a look at a sample rule definition that we introduced in the previous post of the series:

Figure 1: Rule definition
The previous post covered use of groupingKeyNames by DynamicKeyFunction to extract message keys. Parameters from the second part of this rule are used by DynamicAlertFunction: they define the actual logic of the performed operations and their parameters (such as the alert-triggering limit). This means that the same rule must be present in both DynamicKeyFunction and DynamicAlertFunction. To achieve this result, we will use the broadcast data distribution mechanism of Apache Flink.
Figure 2 presents the final job graph of the system that we are building:
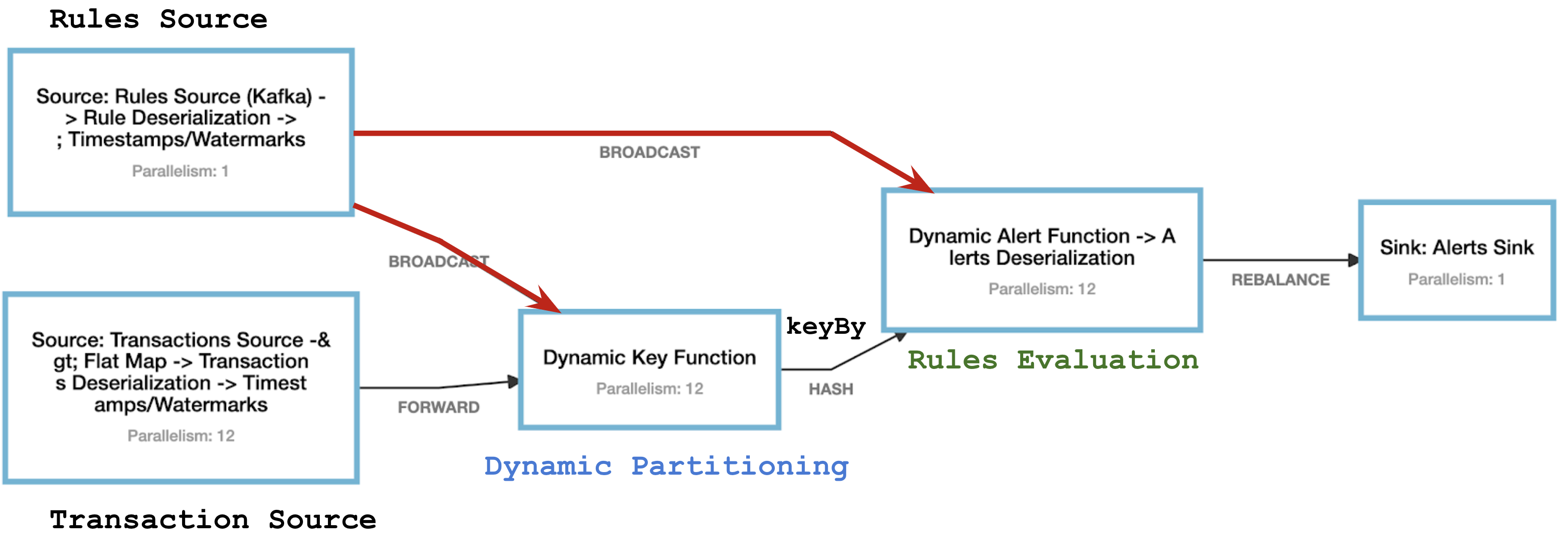
Figure 2: Job Graph of the Fraud Detection Flink Job
The main blocks of the Transactions processing pipeline are:
-
Transaction Source that consumes transaction messages from Kafka partitions in parallel.
-
Dynamic Key Function that performs data enrichment with a dynamic key. The subsequent
keyByhashes this dynamic key and partitions the data accordingly among all parallel instances of the following operator. -
Dynamic Alert Function that accumulates a data window and creates Alerts based on it.
Data Exchange inside Apache Flink #
The job graph above also indicates various data exchange patterns between the operators. In order to understand how the broadcast pattern works, let’s take a short detour and discuss what methods of message propagation exist in Apache Flink’s distributed runtime.
- The FORWARD connection after the Transaction Source means that all data consumed by one of the parallel instances of the Transaction Source operator is transferred to exactly one instance of the subsequent
DynamicKeyFunctionoperator. It also indicates the same level of parallelism of the two connected operators (12 in the above case). This communication pattern is illustrated in Figure 3. Orange circles represent transactions, and dotted rectangles depict parallel instances of the conjoined operators.
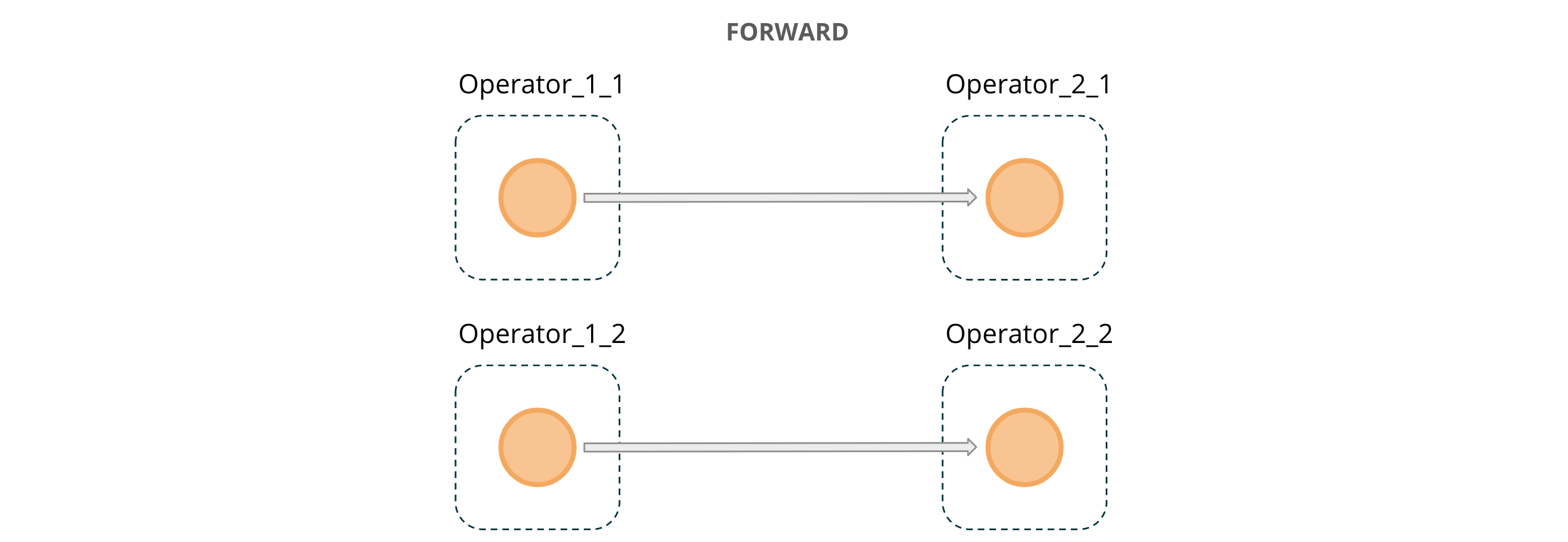
Figure 3: FORWARD message passing across operator instances
- The HASH connection between
DynamicKeyFunctionandDynamicAlertFunctionmeans that for each message a hash code is calculated and messages are evenly distributed among available parallel instances of the next operator. Such a connection needs to be explicitly “requested” from Flink by usingkeyBy.
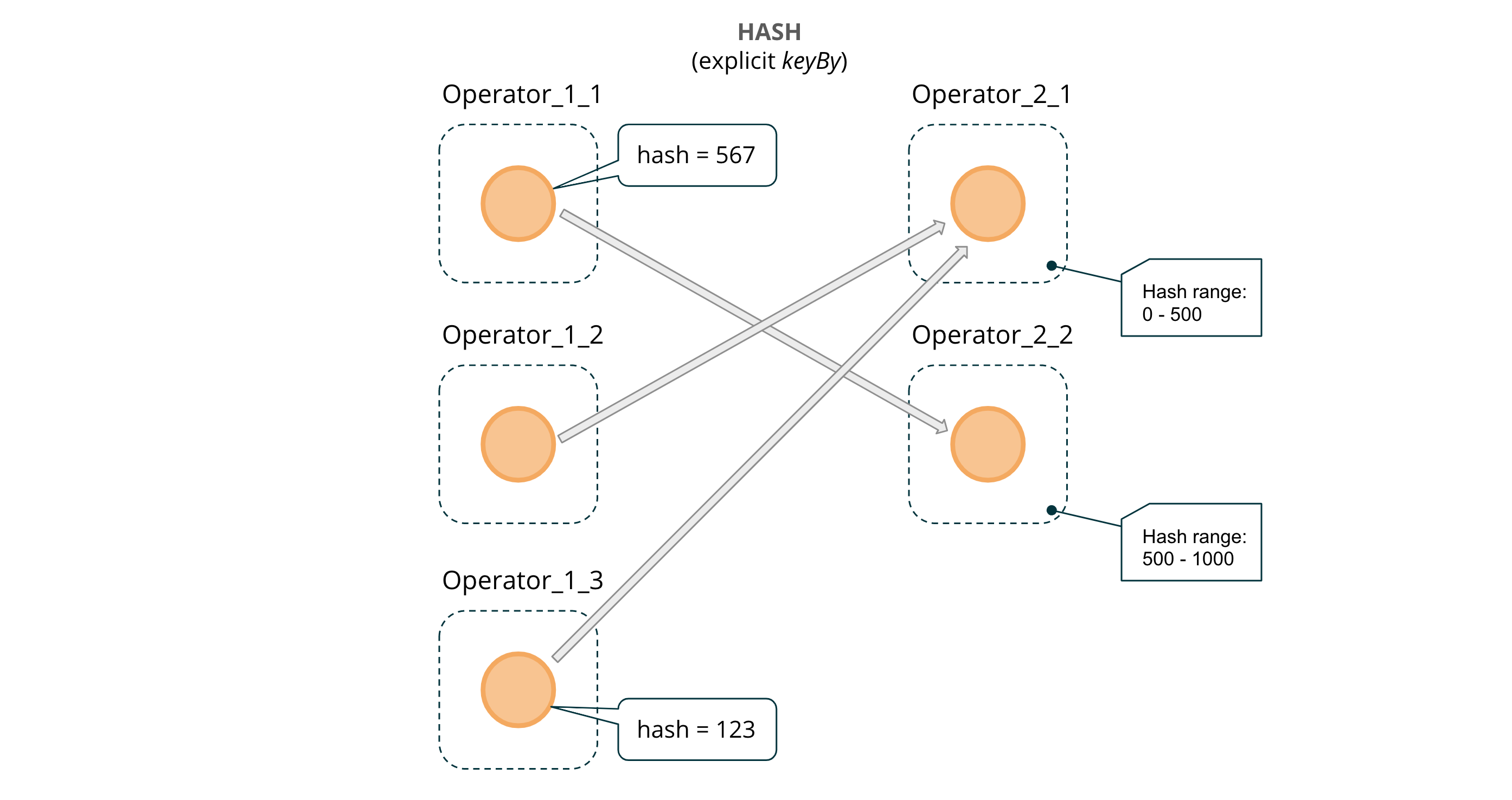
Figure 4: HASHED message passing across operator instances (via `keyBy`)
- A REBALANCE distribution is either caused by an explicit call to
rebalance()or by a change of parallelism (12 -> 1 in the case of the job graph from Figure 2). Callingrebalance()causes data to be repartitioned in a round-robin fashion and can help to mitigate data skew in certain scenarios.
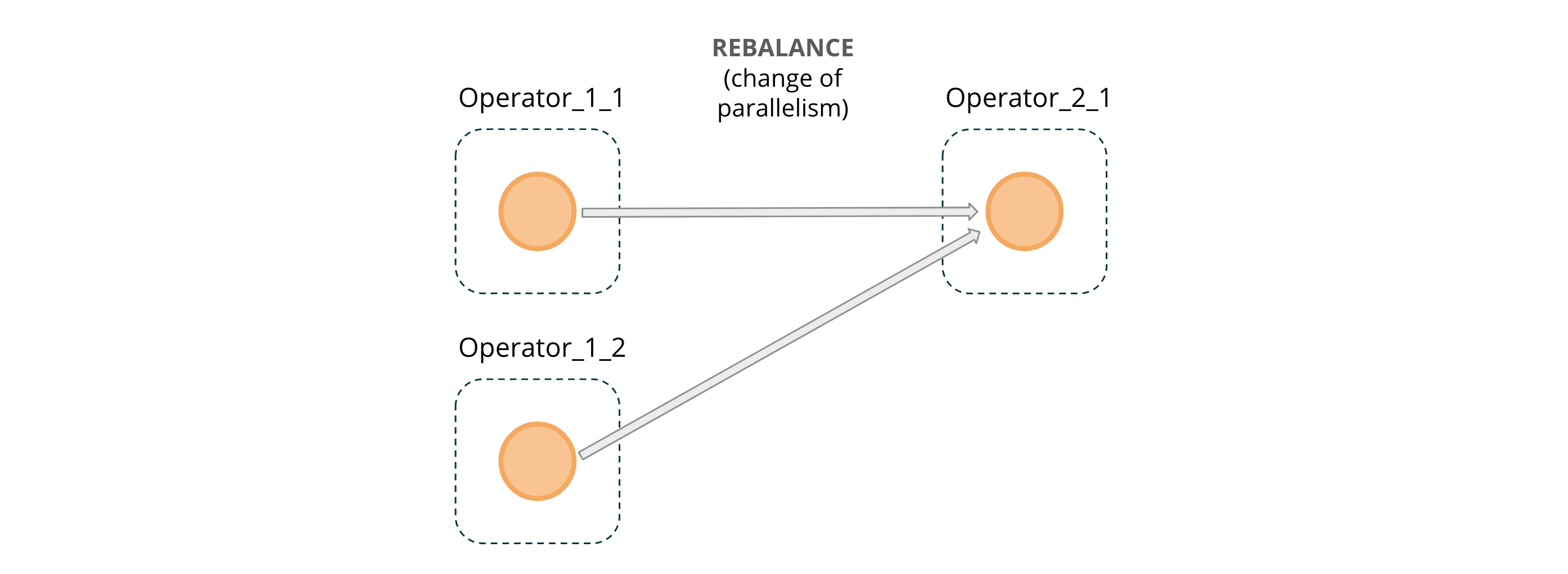
Figure 5: REBALANCE message passing across operator instances
The Fraud Detection job graph in Figure 2 contains an additional data source: Rules Source. It also consumes from Kafka. Rules are “mixed into” the main processing data flow through the BROADCAST channel. Unlike other methods of transmitting data between operators, such as forward, hash or rebalance that make each message available for processing in only one of the parallel instances of the receiving operator, broadcast makes each message available at the input of all of the parallel instances of the operator to which the broadcast stream is connected. This makes broadcast applicable to a wide range of tasks that need to affect the processing of all messages, regardless of their key or source partition.
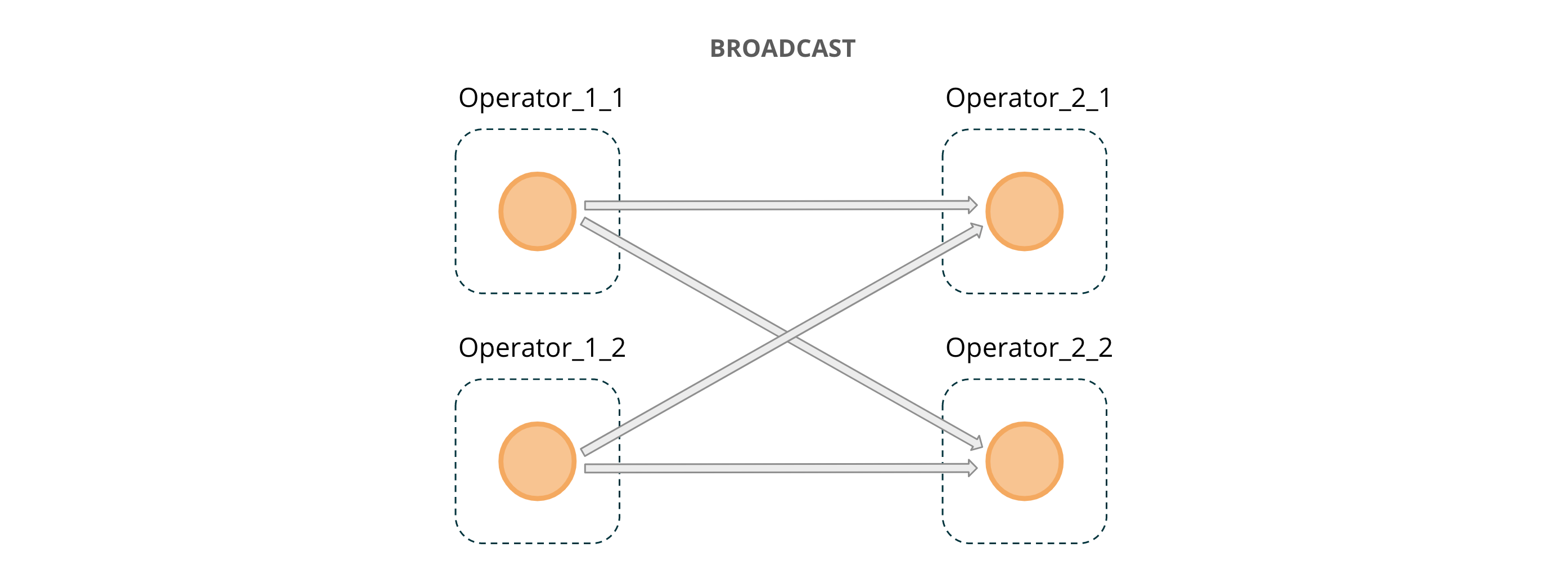
Figure 6: BROADCAST message passing across operator instances
Broadcast State Pattern #
In order to make use of the Rules Source, we need to “connect” it to the main data stream:
// Streams setup
DataStream<Transaction> transactions = [...]
DataStream<Rule> rulesUpdateStream = [...]
BroadcastStream<Rule> rulesStream = rulesUpdateStream.broadcast(RULES_STATE_DESCRIPTOR);
// Processing pipeline setup
DataStream<Alert> alerts =
transactions
.connect(rulesStream)
.process(new DynamicKeyFunction())
.keyBy((keyed) -> keyed.getKey())
.connect(rulesStream)
.process(new DynamicAlertFunction())
As you can see, the broadcast stream can be created from any regular stream by calling the broadcast method and specifying a state descriptor. Flink assumes that broadcasted data needs to be stored and retrieved while processing events of the main data flow and, therefore, always automatically creates a corresponding broadcast state from this state descriptor. This is different from any other Apache Flink state type in which you need to initialize it in the open() method of the processing function. Also note that broadcast state always has a key-value format (MapState).
public static final MapStateDescriptor<Integer, Rule> RULES_STATE_DESCRIPTOR =
new MapStateDescriptor<>("rules", Integer.class, Rule.class);
Connecting to rulesStream causes some changes in the signature of the processing functions. The previous article presented it in a slightly simplified way as a ProcessFunction. However, DynamicKeyFunction is actually a BroadcastProcessFunction.
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> {
public abstract void processElement(IN1 value,
ReadOnlyContext ctx,
Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value,
Context ctx,
Collector<OUT> out) throws Exception;
}
The difference is the addition of the processBroadcastElement method through which messages of the rules stream will arrive. The following new version of DynamicKeyFunction allows modifying the list of data-distribution keys at runtime through this stream:
public class DynamicKeyFunction
extends BroadcastProcessFunction<Transaction, Rule, Keyed<Transaction, String, Integer>> {
@Override
public void processBroadcastElement(Rule rule,
Context ctx,
Collector<Keyed<Transaction, String, Integer>> out) {
BroadcastState<Integer, Rule> broadcastState = ctx.getBroadcastState(RULES_STATE_DESCRIPTOR);
broadcastState.put(rule.getRuleId(), rule);
}
@Override
public void processElement(Transaction event,
ReadOnlyContext ctx,
Collector<Keyed<Transaction, String, Integer>> out){
ReadOnlyBroadcastState<Integer, Rule> rulesState =
ctx.getBroadcastState(RULES_STATE_DESCRIPTOR);
for (Map.Entry<Integer, Rule> entry : rulesState.immutableEntries()) {
final Rule rule = entry.getValue();
out.collect(
new Keyed<>(
event, KeysExtractor.getKey(rule.getGroupingKeyNames(), event), rule.getRuleId()));
}
}
}
In the above code, processElement() receives Transactions, and processBroadcastElement() receives Rule updates. When a new rule is created, it is distributed as depicted in Figure 6 and saved in all parallel instances of the operator using processBroadcastState. We use a Rule’s ID as the key to store and reference individual rules. Instead of iterating over a hardcoded List<Rules>, we iterate over entries in the dynamically-updated broadcast state.
DynamicAlertFunction follows the same logic with respect to storing the rules in the broadcast MapState. As described in Part 1, each message in the processElement input is intended to be processed by one specific rule and comes “pre-marked” with a corresponding ID by DynamicKeyFunction. All we need to do is retrieve the definition of the corresponding rule from BroadcastState by using the provided ID and process it according to the logic required by that rule. At this stage, we will also add messages to the internal function state in order to perform calculations on the required time window of data. We will consider how this is done in the final blog of the series about Fraud Detection.
Summary #
In this blog post, we continued our investigation of the use case of a Fraud Detection System built with Apache Flink. We looked into different ways in which data can be distributed between parallel operator instances and, most importantly, examined broadcast state. We demonstrated how dynamic partitioning — a pattern described in the first part of the series — can be combined and enhanced by the functionality provided by the broadcast state pattern. The ability to send dynamic updates at runtime is a powerful feature of Apache Flink that is applicable in a variety of other use cases, such as controlling state (cleanup/insert/fix), running A/B experiments or executing updates of ML model coefficients.