Stateful Functions 2.0 - An Event-driven Database on Apache Flink
April 7, 2020 - Stephan Ewen (@stephanewen)Today, we are announcing the release of Stateful Functions (StateFun) 2.0 — the first release of Stateful Functions as part of the Apache Flink project. This release marks a big milestone: Stateful Functions 2.0 is not only an API update, but the first version of an event-driven database that is built on Apache Flink.
Stateful Functions 2.0 makes it possible to combine StateFun’s powerful approach to state and composition with the elasticity, rapid scaling/scale-to-zero and rolling upgrade capabilities of FaaS implementations like AWS Lambda and modern resource orchestration frameworks like Kubernetes.
With these features, Stateful Functions 2.0 addresses two of the most cited shortcomings of many FaaS setups today: consistent state and efficient messaging between functions.
An Event-driven Database #
When Stateful Functions joined Apache Flink at the beginning of this year, the project had started as a library on top of Flink to build general-purpose event-driven applications. Users would implement functions that receive and send messages, and maintain state in persistent variables. Flink provided the runtime with efficient exactly-once state and messaging. Stateful Functions 1.0 was a FaaS-inspired mix between stream processing and actor programming — on steroids.
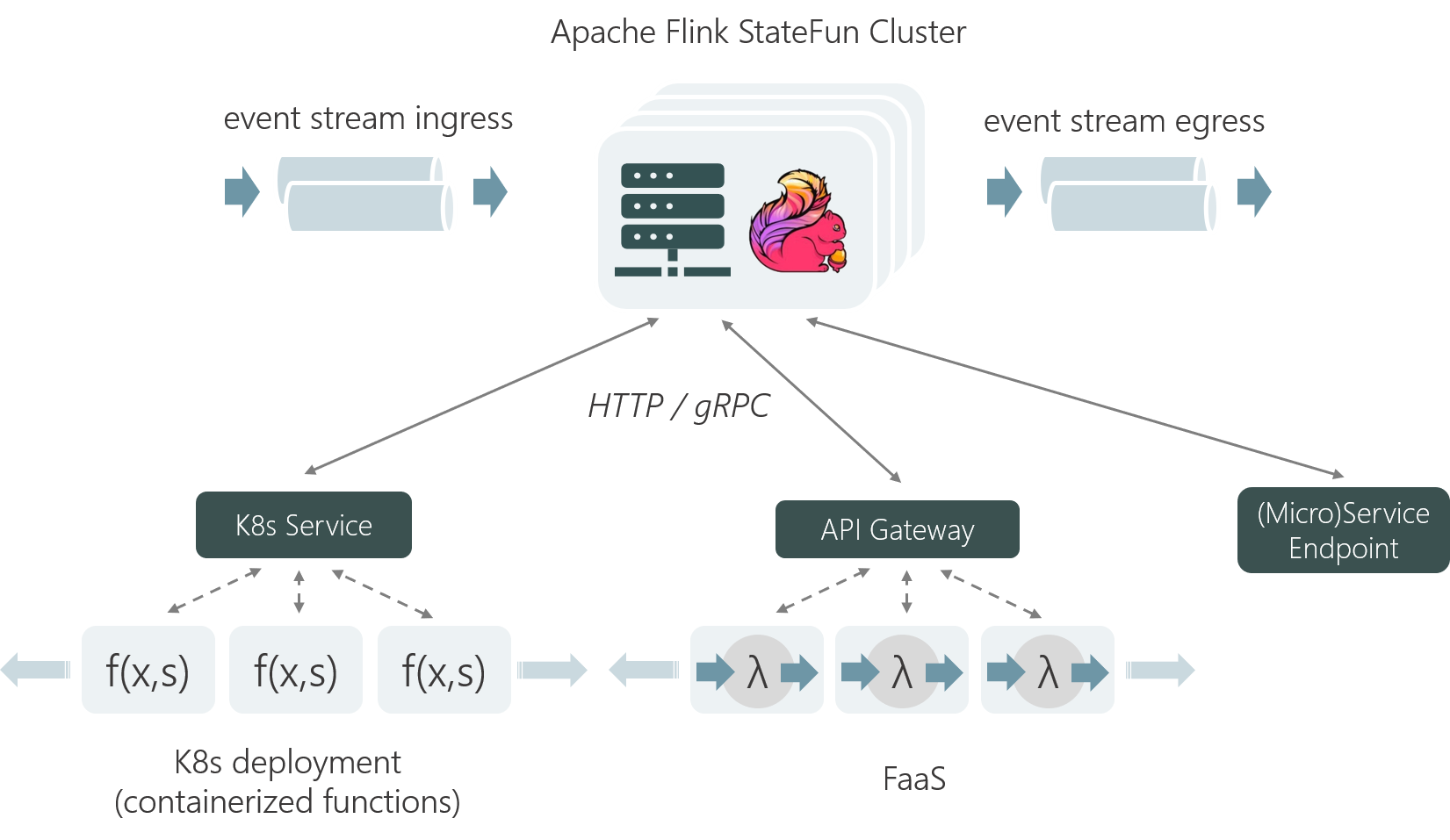
In version 2.0, Stateful Functions now physically decouples the functions from Flink and the JVM, to invoke them through simple services. That makes it possible to execute functions on a FaaS platform, a Kubernetes deployment or behind a (micro) service.
Flink invokes the functions through a service endpoint via HTTP or gRPC based on incoming events, and supplies state access. The system makes sure that only one invocation per entity (type+ID) is ongoing at any point in time, thus guaranteeing consistency through isolation.
By supplying state access as part of the function invocation, the functions themselves behave like stateless applications and can be managed with the same simplicity and benefits: rapid scalability, scale-to-zero, rolling/zero-downtime upgrades and so on.
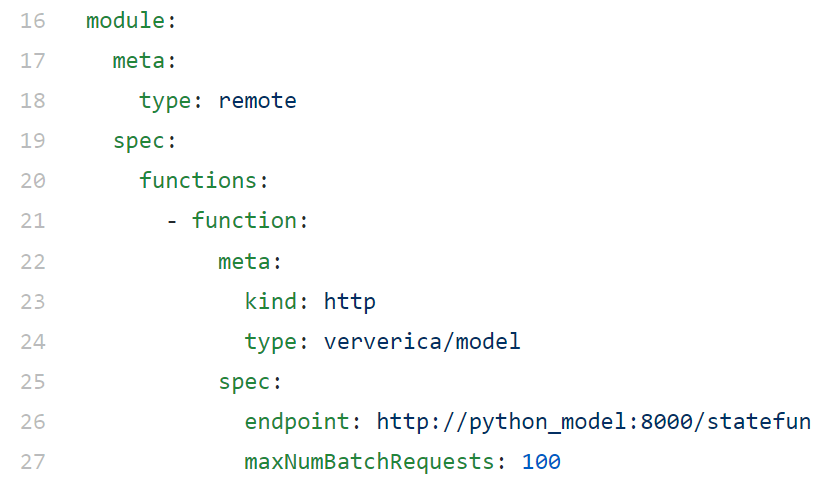
The functions can be implemented in any programming language that can handle HTTP requests or bring up a gRPC server. The StateFun project includes a very slim SDK for Python, taking requests and dispatching them to annotated functions. We aim to provide similar SDKs for other languages, such as Go, JavaScript or Rust. Users do not need to write any Flink code (or JVM code) at all; data ingresses/egresses and function endpoints can be defined in a compact YAML spec.

The Flink processes (and the JVM) are not executing any user-code at all — though this is possible, for performance reasons (see Embedded Functions). Rather than running application-specific dataflows, Flink here stores the state of the functions and provides the dynamic messaging plane through which functions message each other, carefully dispatching messages/invocations to the event-driven functions/services to maintain consistency guarantees.
Effectively, Flink takes the role of the database, but tailored towards event-driven functions and services. It integrates state storage with the messaging between (and the invocations of) functions and services. Because of this, Stateful Functions 2.0 can be thought of as an “Event-driven Database” on Apache Flink.
“Event-driven Database” vs. “Request/Response Database” #
In the case of a traditional database or key/value store (let’s call them request/response databases), the application issues queries to the database (e.g. SQL via JDBC, GET/PUT via HTTP). In contrast, an event-driven database like StateFun inverts that relationship between database and application: the database invokes the functions/services based on arriving messages. This fits very naturally with FaaS and many event-driven application architectures.
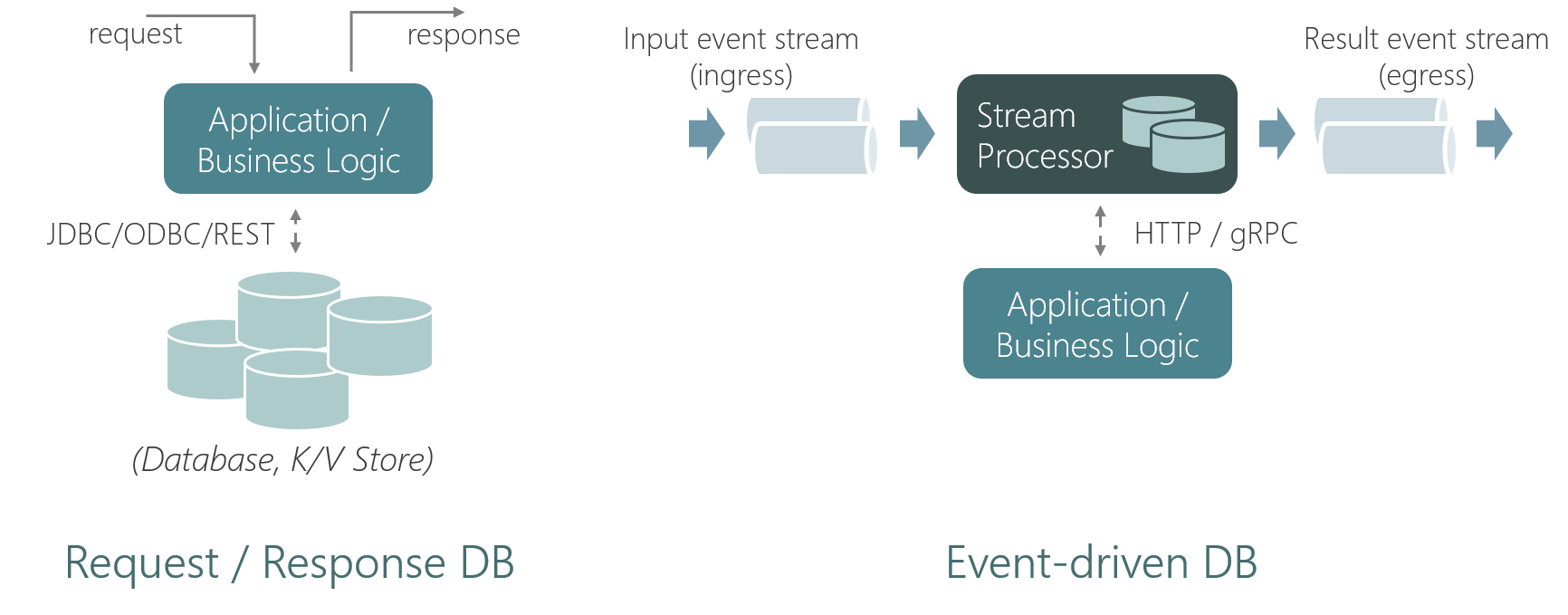
In the case of applications built on request/response databases, the database is responsible only for the state. Communication between different functions/services is a separate concern handled within the application layer. In contrast to that, an event-driven database takes care of both state storage and message transport, in a tightly integrated manner.
Similar to Actor Programming, Stateful Functions uses the idea of addressable entities - here, the entity is a function type with an invocation scoped to an ID. These addressable entities own the state and are the targets of messages. Different to actor systems is that the application logic is external and the addressable entities are not physical objects in memory (i.e. actors), but rows in Flink’s managed state, together with the entities’ mailboxes.
State and Consistency #
Besides matching the needs of serverless applications and FaaS well, the event-driven database approach also helps with simplifying consistent state management.
Consider the example below, with two entities of an application — for example two microservices (Service 1, Service 2). Service 1 is invoked, updates the state in the database, and sends a request to Service 2. Assume that this request fails. There is, in general, no way for Service 1 to know whether Service 2 processed the request and updated its state or not (c.f. Two Generals Problem). To work around that, many techniques exist — making requests idempotent and retrying, commit/rollback protocols, or external transaction coordinators, for example. Solving this in the application layer is complex enough, and including the database into these approaches only adds more complexity.
In the scenario where the event-driven database takes care of state and messaging, we have a much easier problem to solve. Assume one shard of the database receives the initial message, updates its state, invokes Service 1, and routes the message produced by the function to another shard, to be delivered to Service 2. Now assume message transport errored — it may have failed or not, we cannot know for certain. Because the database is in charge of state and messaging, it can offer a generic solution to make sure that either both go through or none does, for example through transactions or consistent snapshots. The application functions are stateless and their invocations without side effects, which means they can be re-invoked again without implications on consistency.
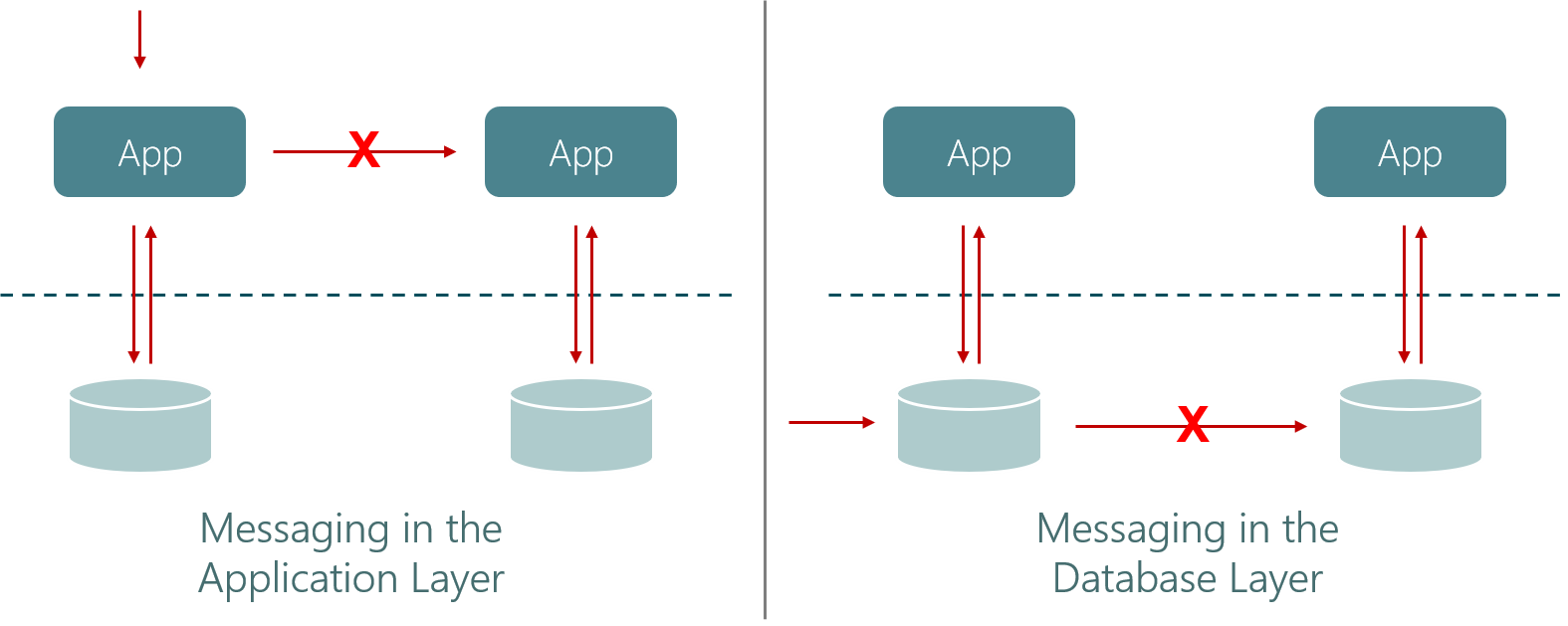
That is the big lesson we learned from working on stream processing technology in the past years: state access/updates and messaging need to be integrated. This gives you consistency, scalable behavior and backpressures well based on both state access and compute bottlenecks.
Despite state and computation being physically separated here, the scheduling/dispatching of function invocations is still integrated and physically co-located with state access, preserving the consistency guarantees given by physical state/compute co-location.
Remote, Co-located or Embedded Functions #
Functions can be deployed in various ways that trade off loose coupling and independent scaling with performance overhead. Each module of functions can be of a different kind, so some functions can run remote, while others could run embedded.
Remote Functions #
Remote Functions are the mechanism described so far, where functions are deployed separately from the Flink StateFun cluster. The state/messaging tier (i.e. the Flink processes) and the function tier can be deployed and scaled independently. All function invocations are remote and have to go through the endpoint service.
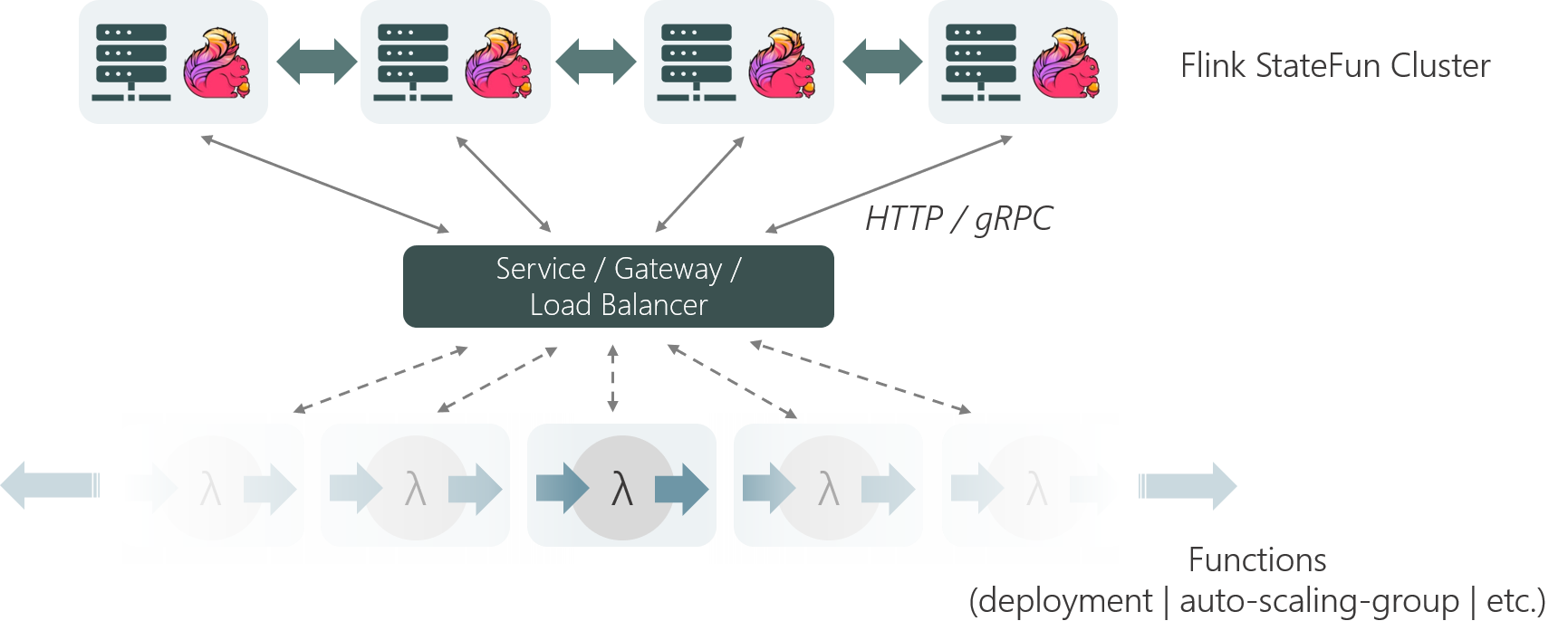
In a similar way as databases are accessed via a standardized protocol (e.g. ODBC/JDBC for relational databases, REST for many key/value stores), StateFun 2.0 invokes functions and services through a standardized protocol: HTTP or gRPC with data in a well-defined ProtoBuf schema.
Co-located Functions #
An alternative way of deploying functions is co-location with the Flink JVM processes. In such a setup, each Flink TaskManager would talk to one function process sitting “next to it”. A common way to do this is to use a system like Kubernetes and deploy pods consisting of a Flink container and the function container that communicate via the pod-local network.
This mode supports different languages while avoiding to route invocations through a Service/Gateway/LoadBalancer, but it cannot scale the state and compute parts independently.
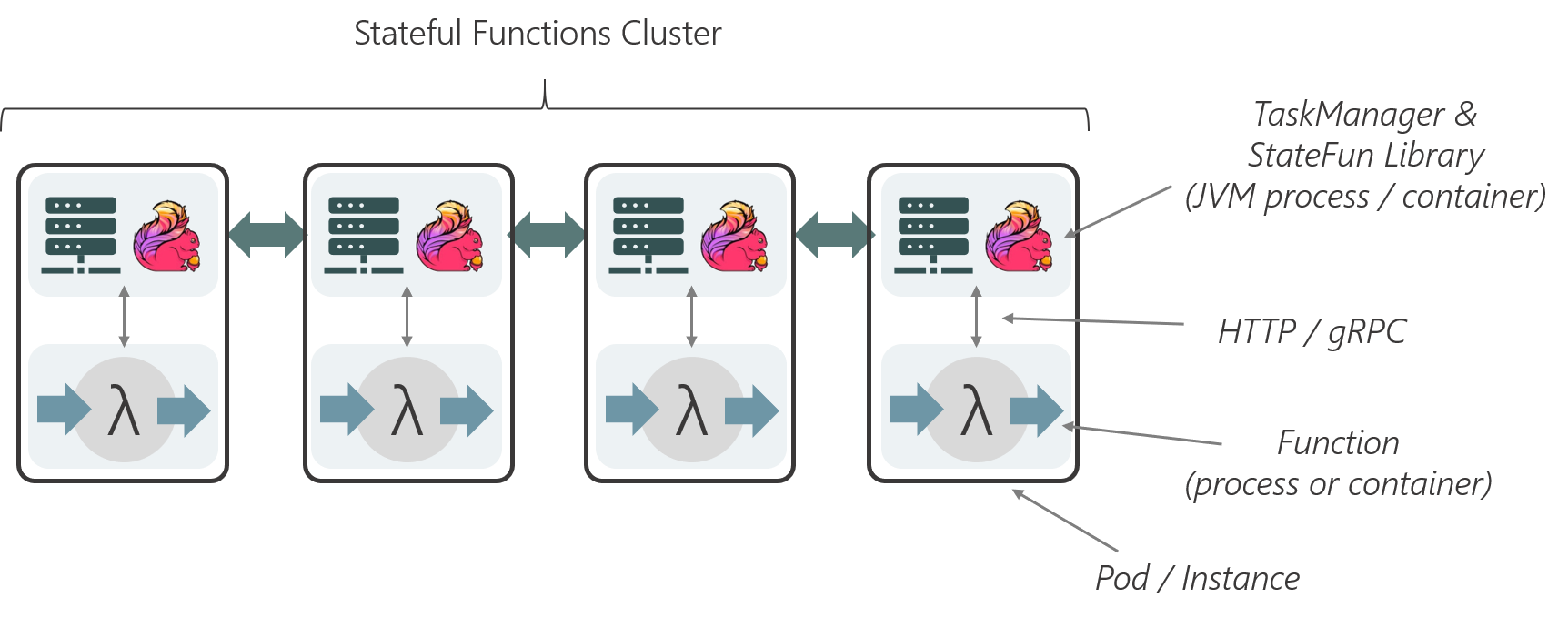
This style of deployment is similar to how Apache Beam’s portability layer and [Flink’s Python API]({{ site.docs-stable }}/tutorials/python_table_api.html) deploy their non-JVM language SDKs.
Embedded Functions #
Embedded Functions are the mode of Stateful Functions 1.0 and Flink’s Java/Scala stream processing APIs. Functions are deployed into the JVM and are directly invoked with the messages and state access. This is the most performant way, though at the cost of only supporting JVM languages.
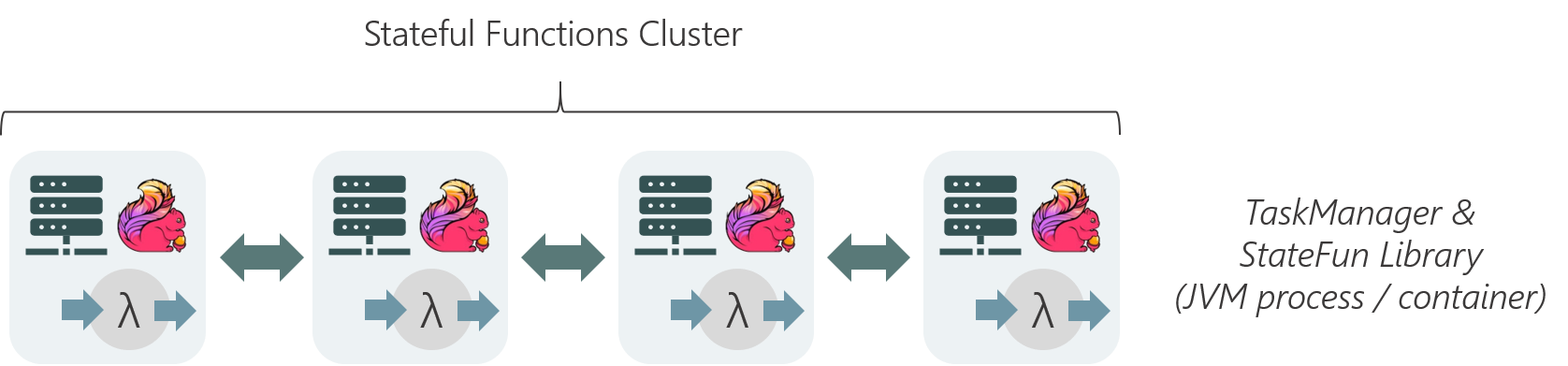
Following the database analogy, embedded functions are a bit like stored procedures, but in a principled way: the functions here are normal Java/Scala/Kotlin functions implementing standard interfaces and can be developed or tested in any IDE.
Loading Data into the Database #
When building a new stateful application, you usually don’t start from a completely blank slate. Often, the application has initial state, such as initial “bootstrap” state, or state from previous versions of the application. When using a database, one could simply bulk load the data to prepare the application.
The equivalent step for Flink would be to write a [savepoint]({{ site.docs-stable }}/ops/state/savepoints.html) that contains the initial state. Savepoints are snapshots of the state of the distributed stream processing application and can be passed to Flink to start processing from that state. Think of them as a database dump, but of a distributed streaming database. In the case of StateFun, the savepoint would contain the state of the functions.
To create a savepoint for a Stateful Functions program, check out the State Bootstrapping API that is part of StateFun 2.0. The State Bootstrapping API uses Flink’s [DataSet API]({{ site.docs-stable }}/dev/batch/), but we plan to expand this to use SQL in the next versions.
Try it out and get involved! #
We hope that we could convey some of the excitement we feel about Stateful Functions. If we managed to pique your curiosity, try it out — for example, starting with this walkthrough.
The project is still in a comparatively early stage, so if you want to get involved, there is lots to work on: SDKs for other languages (e.g. Go, JavaScript, Rust), ingresses/egresses and tools for testing, among others.
To follow the project and learn more, please check out these resources:
- Code: https://github.com/apache/flink-statefun
- Docs: //nightlies.apache.org/flink/flink-statefun-docs-release-2.0/
- Apache Flink project site: https://flink.apache.org/
- Apache Flink on Twitter: @ApacheFlink
- Stateful Functions Webpage: https://statefun.io
- Stateful Functions on Twitter: @StateFun_IO
Thank you! #
The Apache Flink community would like to thank all contributors that have made this release possible:
David Anderson, Dian Fu, Igal Shilman, Seth Wiesman, Stephan Ewen, Tzu-Li (Gordon) Tai, hequn8128