PyFlink: Introducing Python Support for UDFs in Flink's Table API
April 9, 2020 - Jincheng Sun (@sunjincheng121) Markos Sfikas (@MarkSfik)Flink 1.9 introduced the Python Table API, allowing developers and data engineers to write Python Table API jobs for Table transformations and analysis, such as Python ETL or aggregate jobs. However, Python users faced some limitations when it came to support for Python UDFs in Flink 1.9, preventing them from extending the system’s built-in functionality.
In Flink 1.10, the community further extended the support for Python by adding Python UDFs in PyFlink. Additionally, both the Python UDF environment and dependency management are now supported, allowing users to import third-party libraries in the UDFs, leveraging Python’s rich set of third-party libraries.
Python Support for UDFs in Flink 1.10 #
Before diving into how you can define and use Python UDFs, we explain the motivation and background behind how UDFs work in PyFlink and provide some additional context about the implementation of our approach. Below we give a brief introduction on the PyFlink architecture from job submission, all the way to executing the Python UDF.
The PyFlink architecture mainly includes two parts — local and cluster — as shown in the architecture visual below. The local phase is the compilation of the job, and the cluster is the execution of the job.

For the local part, the Python API is a mapping of the Java API: each time Python executes a method in the figure above, it will synchronously call the method corresponding to Java through Py4J, and finally generate a Java JobGraph, before submitting it to the cluster.
For the cluster part, just like ordinary Java jobs, the JobMaster schedules tasks to TaskManagers. The tasks that include Python UDF in a TaskManager involve the execution of Java and Python operators. In the Python UDF operator, various gRPC services are used to provide different communications between the Java VM and the Python VM, such as DataService for data transmissions, StateService for state requirements, and Logging and Metrics Services. These services are built on Beam’s Fn API. While currently only Process mode is supported for Python workers, support for Docker mode and External service mode is also considered for future Flink releases.
How to use PyFlink with UDFs in Flink 1.10 #
This section provides some Python user defined function (UDF) examples, including how to install PyFlink, how to define/register/invoke UDFs in PyFlink and how to execute the job.
Install PyFlink #
Using Python in Apache Flink requires installing PyFlink. PyFlink is available through PyPI and can be easily installed using pip:
$ python -m pip install apache-flink
Define a Python UDF #
There are many ways to define a Python scalar function, besides extending the base class ScalarFunction. The following example shows the different ways of defining a Python scalar function that takes two columns of BIGINT as input parameters and returns the sum of them as the result.
# option 1: extending the base class `ScalarFunction`
class Add(ScalarFunction):
def eval(self, i, j):
return i + j
add = udf(Add(), [DataTypes.BIGINT(), DataTypes.BIGINT()], DataTypes.BIGINT())
# option 2: Python function
@udf(input_types=[DataTypes.BIGINT(), DataTypes.BIGINT()], result_type=DataTypes.BIGINT())
def add(i, j):
return i + j
# option 3: lambda function
add = udf(lambda i, j: i + j, [DataTypes.BIGINT(), DataTypes.BIGINT()], DataTypes.BIGINT())
# option 4: callable function
class CallableAdd(object):
def __call__(self, i, j):
return i + j
add = udf(CallableAdd(), [DataTypes.BIGINT(), DataTypes.BIGINT()], DataTypes.BIGINT())
# option 5: partial function
def partial_add(i, j, k):
return i + j + k
add = udf(functools.partial(partial_add, k=1), [DataTypes.BIGINT(), DataTypes.BIGINT()],
DataTypes.BIGINT())
Register a Python UDF #
# register the Python function
table_env.register_function("add", add)
Invoke a Python UDF #
# use the function in Python Table API
my_table.select("add(a, b)")
Below, you can find a complete example of using Python UDF.
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment, DataTypes
from pyflink.table.descriptors import Schema, OldCsv, FileSystem
from pyflink.table.udf import udf
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
t_env = StreamTableEnvironment.create(env)
add = udf(lambda i, j: i + j, [DataTypes.BIGINT(), DataTypes.BIGINT()], DataTypes.BIGINT())
t_env.register_function("add", add)
t_env.connect(FileSystem().path('/tmp/input')) \
.with_format(OldCsv()
.field('a', DataTypes.BIGINT())
.field('b', DataTypes.BIGINT())) \
.with_schema(Schema()
.field('a', DataTypes.BIGINT())
.field('b', DataTypes.BIGINT())) \
.create_temporary_table('mySource')
t_env.connect(FileSystem().path('/tmp/output')) \
.with_format(OldCsv()
.field('sum', DataTypes.BIGINT())) \
.with_schema(Schema()
.field('sum', DataTypes.BIGINT())) \
.create_temporary_table('mySink')
t_env.from_path('mySource')\
.select("add(a, b)") \
.insert_into('mySink')
t_env.execute("tutorial_job")
Submit the job #
Firstly, you need to prepare the input data in the “/tmp/input” file. For example,
$ echo "1,2" > /tmp/input
Next, you can run this example on the command line,
$ python python_udf_sum.py
The command builds and runs the Python Table API program in a local mini-cluster. You can also submit the Python Table API program to a remote cluster using different command lines, (see more details here).
Finally, you can see the execution result on the command line:
$ cat /tmp/output 3
Python UDF dependency management #
In many cases, you would like to import third-party dependencies in the Python UDF. The example below provides detailed guidance on how to manage such dependencies.
Suppose you want to use the mpmath to perform the sum of the example above. The Python UDF may look like:
@udf(input_types=[DataTypes.BIGINT(), DataTypes.BIGINT()], result_type=DataTypes.BIGINT())
def add(i, j):
from mpmath import fadd # add third-party dependency
return int(fadd(i, j))
To make it available on the worker node that does not contain the dependency, you can specify the dependencies with the following commands and API:
$ cd /tmp
$ echo mpmath==1.1.0 > requirements.txt
$ pip download -d cached_dir -r requirements.txt --no-binary :all:
t_env.set_python_requirements("/tmp/requirements.txt", "/tmp/cached_dir")
A requirements.txt file that defines the third-party dependencies is used. If the dependencies cannot be accessed in the cluster, then you can specify a directory containing the installation packages of these dependencies by using the parameter “requirements_cached_dir”, as illustrated in the example above. The dependencies will be uploaded to the cluster and installed offline.
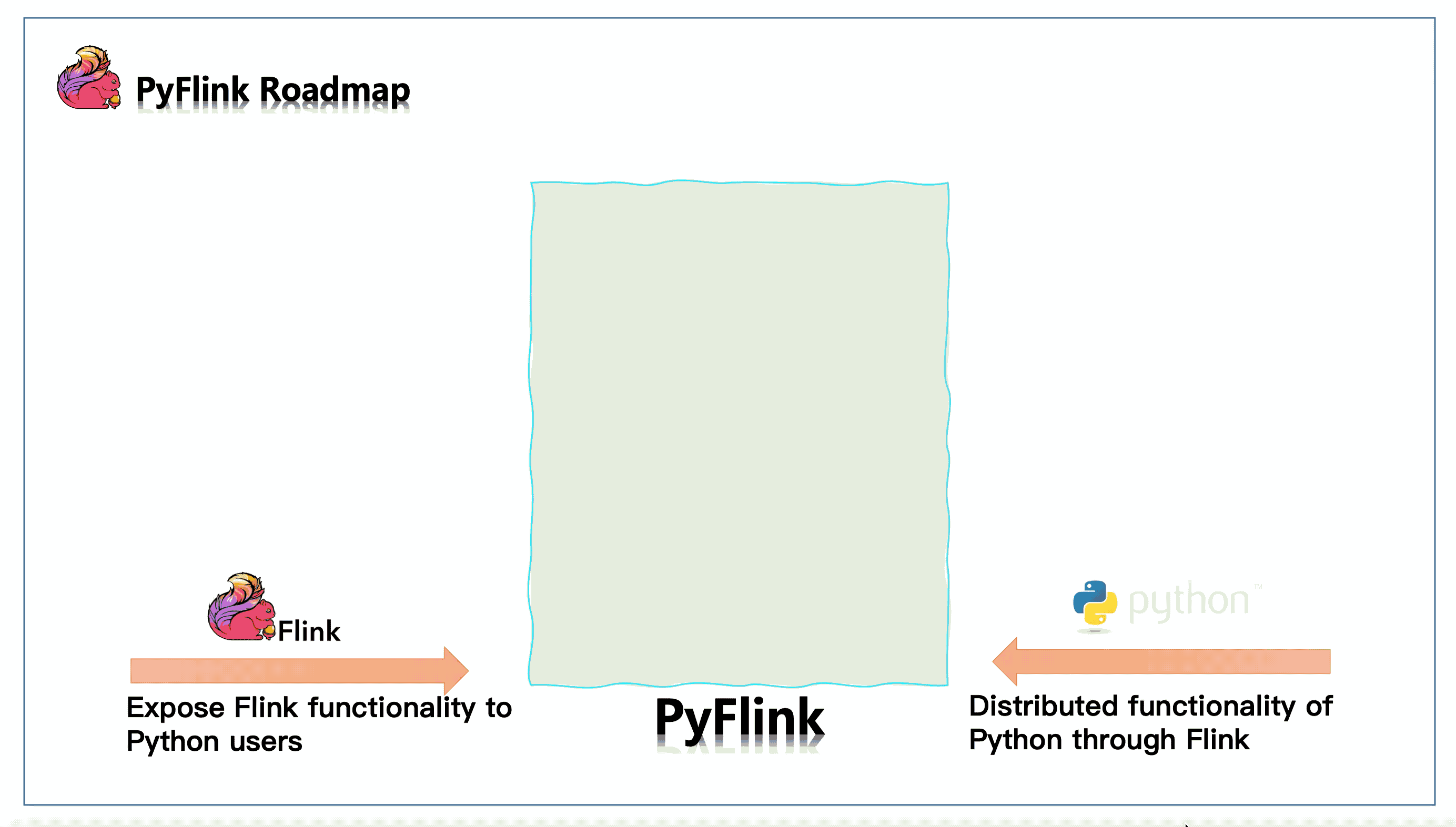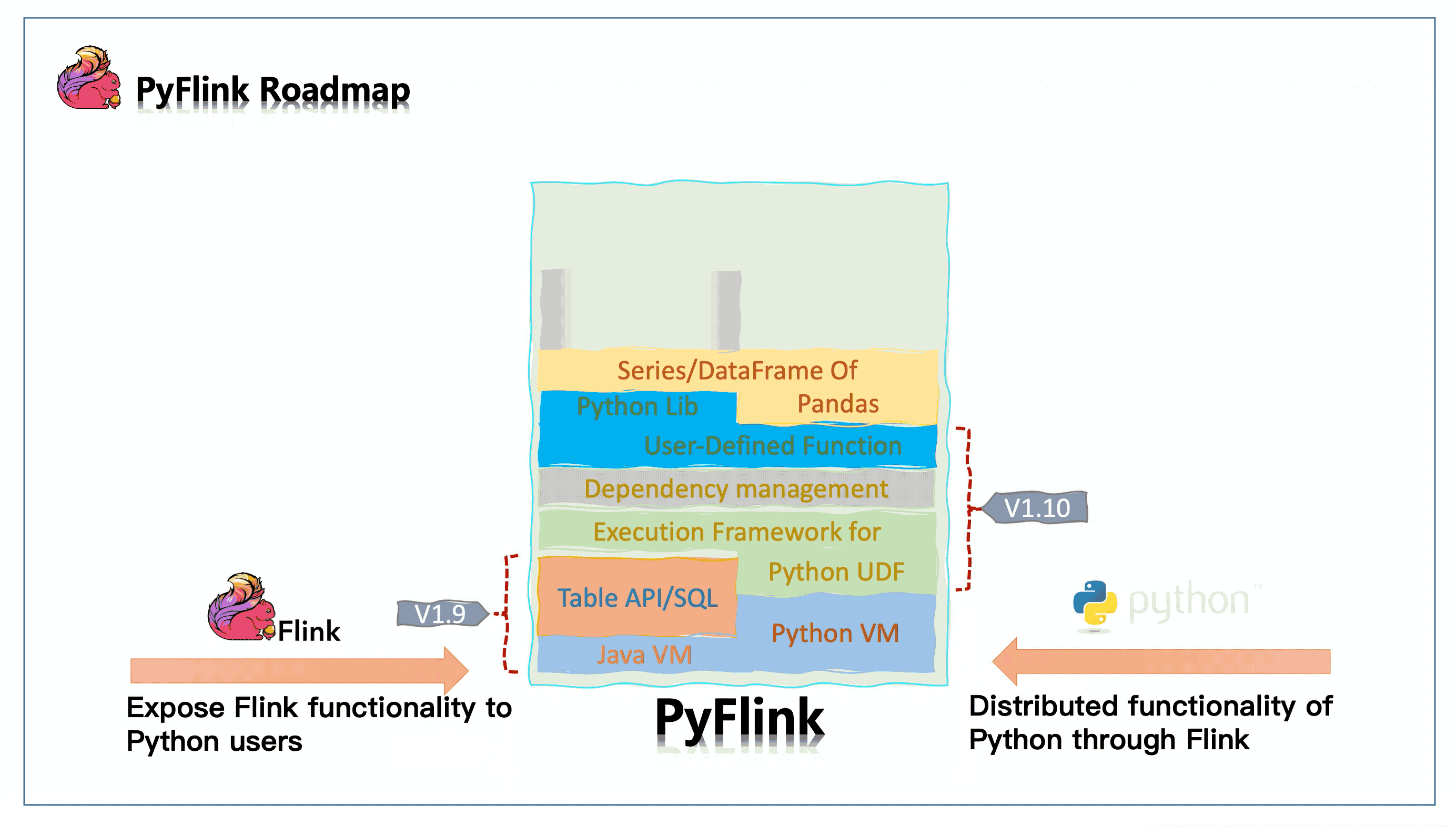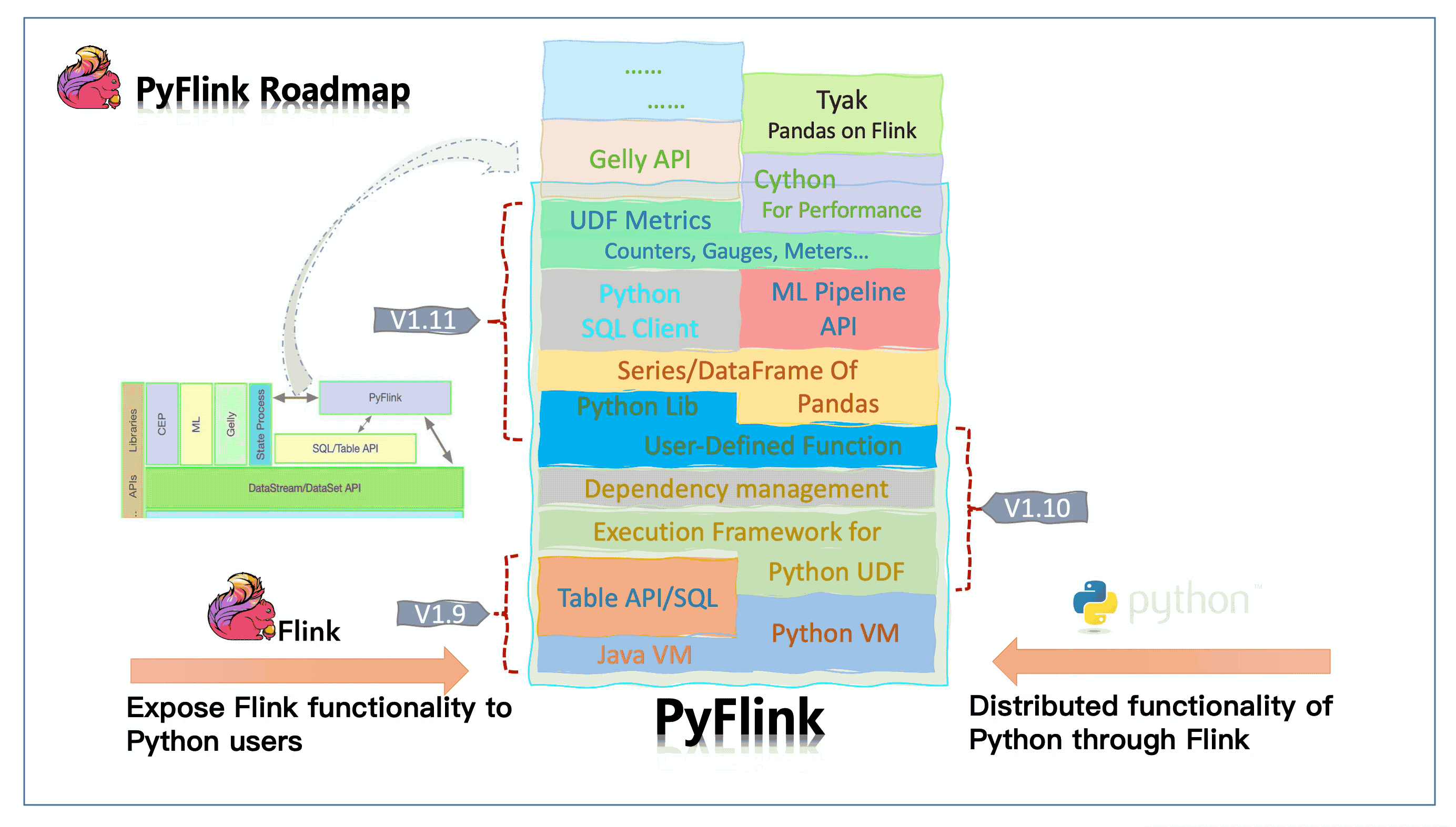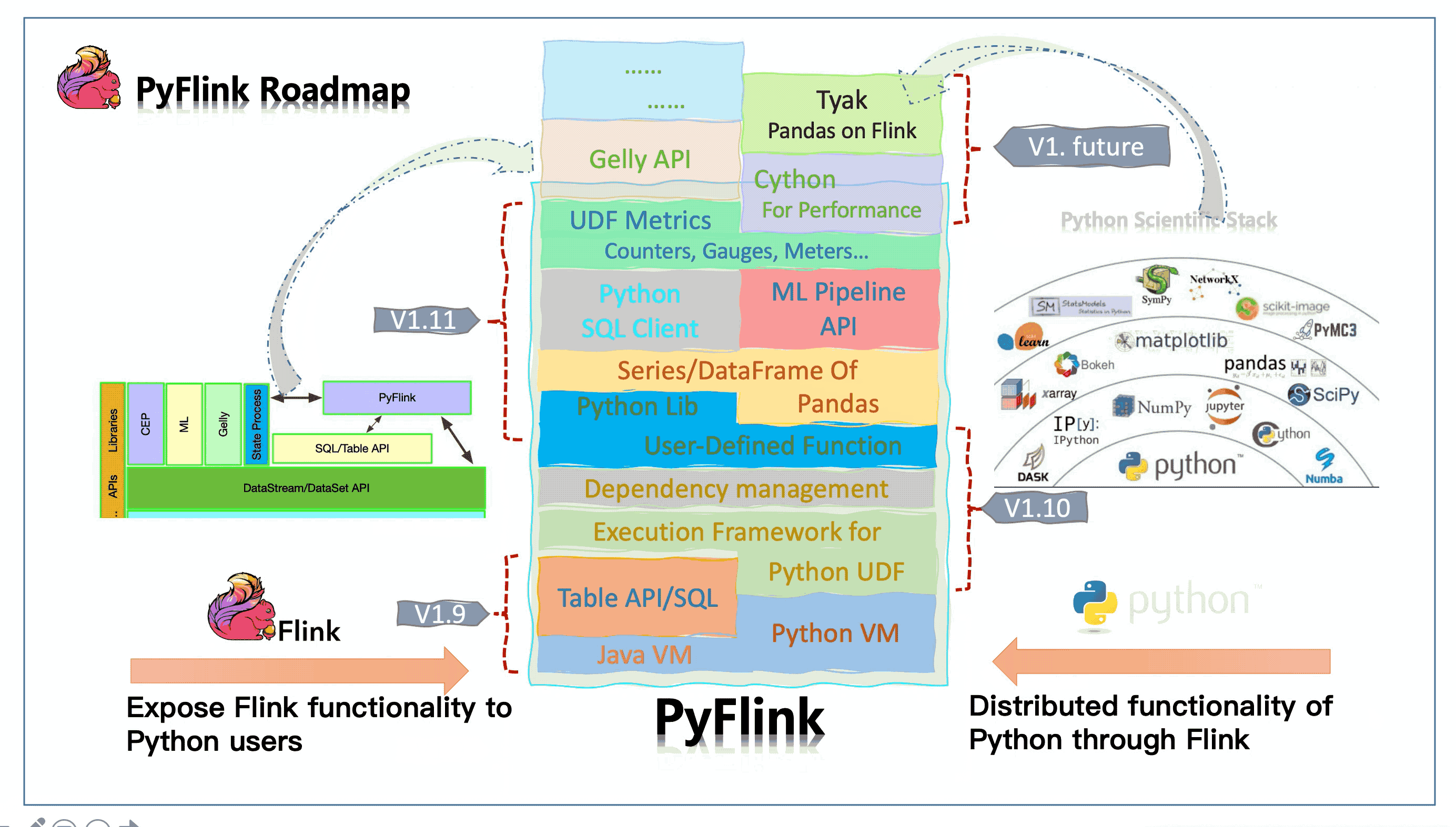
Conclusion & Upcoming work #
In this blog post, we introduced the architecture of Python UDFs in PyFlink and provided some examples on how to define, register and invoke UDFs. Flink 1.10 brings Python support in the framework to new levels, allowing Python users to write even more magic with their preferred language. The community is actively working towards continuously improving the functionality and performance of PyFlink. Future work in upcoming releases will introduce support for Pandas UDFs in scalar and aggregate functions, add support to use Python UDFs through the SQL client to further expand the usage scope of Python UDFs, provide support for a Python ML Pipeline API and finally work towards even more performance improvements. The picture below provides more details on the roadmap for succeeding releases.