Flink on Zeppelin Notebooks for Interactive Data Analysis - Part 1
June 15, 2020 - Jeff Zhang (@zjffdu)The latest release of Apache Zeppelin comes with a redesigned interpreter for Apache Flink (version Flink 1.10+ is only supported moving forward) that allows developers to use Flink directly on Zeppelin notebooks for interactive data analysis. I wrote 2 posts about how to use Flink in Zeppelin. This is part-1 where I explain how the Flink interpreter in Zeppelin works, and provide a tutorial for running Streaming ETL with Flink on Zeppelin.
The Flink Interpreter in Zeppelin 0.9 #
The Flink interpreter can be accessed and configured from Zeppelin’s interpreter settings page. The interpreter has been refactored so that Flink users can now take advantage of Zeppelin to write Flink applications in three languages, namely Scala, Python (PyFlink) and SQL (for both batch & streaming executions). Zeppelin 0.9 now comes with the Flink interpreter group, consisting of the below five interpreters:
- %flink - Provides a Scala environment
- %flink.pyflink - Provides a python environment
- %flink.ipyflink - Provides an ipython environment
- %flink.ssql - Provides a stream sql environment
- %flink.bsql - Provides a batch sql environment
Not only has the interpreter been extended to support writing Flink applications in three languages, but it has also extended the available execution modes for Flink that now include:
- Running Flink in Local Mode
- Running Flink in Remote Mode
- Running Flink in Yarn Mode
You can find more information about how to get started with Zeppelin and all the execution modes for Flink applications in Zeppelin notebooks in this post.
Flink on Zeppelin for Stream processing #
Performing stream processing jobs with Apache Flink on Zeppelin allows you to run most major streaming cases, such as streaming ETL and real time data analytics, with the use of Flink SQL and specific UDFs. Below we showcase how you can execute streaming ETL using Flink on Zeppelin:
You can use Flink SQL to perform streaming ETL by following the steps below (for the full tutorial, please refer to the Flink Tutorial/Streaming ETL tutorial of the Zeppelin distribution):
- Step 1. Create source table to represent the source data.

- Step 2. Create a sink table to represent the processed data.

- Step 3. After creating the source and sink table, we can insert them to our statement to trigger the stream processing job as the following:

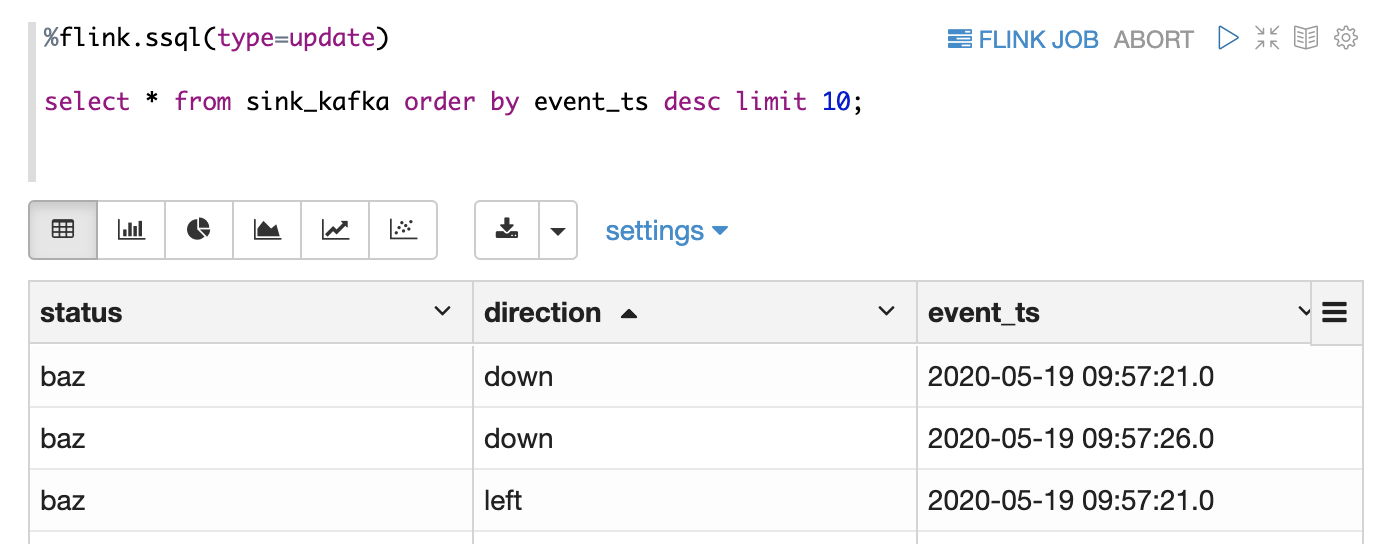
- Step 4. After initiating the streaming job, you can use another SQL statement to query the sink table to verify the results of your job. Here you can see the top 10 records which will be refreshed every 3 seconds.
Summary #
In this post, we explained how the redesigned Flink interpreter works in Zeppelin 0.9.0 and provided some examples for performing streaming ETL jobs with Flink and Zeppelin. In the next post, I will talk about how to do streaming data visualization via Flink on Zeppelin. Besides that, you can find an additional tutorial for batch processing with Flink on Zeppelin as well as using Flink on Zeppelin for more advance operations like resource isolation, job concurrency & parallelism, multiple Hadoop & Hive environments and more on our series of posts on Medium. And here’s a list of Flink on Zeppelin tutorial videos for your reference.
References #
- Apache Zeppelin official website
- Flink on Zeppelin tutorials - Part 1
- Flink on Zeppelin tutorials - Part 2
- Flink on Zeppelin tutorials - Part 3
- Flink on Zeppelin tutorials - Part 4
- Flink on Zeppelin tutorial videos