Application Deployment in Flink: Current State and the new Application Mode
July 14, 2020 - Kostas Kloudas (@kkloudas)With the rise of stream processing and real-time analytics as a critical tool for modern businesses, an increasing number of organizations build platforms with Apache Flink at their core and offer it internally as a service. Many talks with related topics from companies like Uber, Netflix and Alibaba in the latest editions of Flink Forward further illustrate this trend.
These platforms aim at simplifying application submission internally by lifting all the operational burden from the end user. To submit Flink applications, these platforms usually expose only a centralized or low-parallelism endpoint (e.g. a Web frontend) for application submission that we will call the Deployer.
One of the roadblocks that platform developers and maintainers often mention is that the Deployer can be a heavy resource consumer that is difficult to provision for. Provisioning for average load can lead to the Deployer service being overwhelmed with deployment requests (in the worst case, for all production applications in a short period of time), while planning based on top load leads to unnecessary costs. Building on this observation, Flink 1.11 introduces the Application Mode as a deployment option, which allows for a lightweight, more scalable application submission process that manages to spread more evenly the application deployment load across the nodes in the cluster.
In order to understand the problem and how the Application Mode solves it, we start by describing briefly the current status of application execution in Flink, before describing the architectural changes introduced by the new deployment mode and how to leverage them.
Application Execution in Flink #
The execution of an application in Flink mainly involves three entities: the Client, the JobManager and the TaskManagers. The Client is responsible for submitting the application to the cluster, the JobManager is responsible for the necessary bookkeeping during execution, and the TaskManagers are the ones doing the actual computation. For more details please refer to Flink’s Architecture documentation page.
Current Deployment Modes #
Before the introduction of the Application Mode in version 1.11, Flink allowed users to execute an application either on a Session or a Per-Job Cluster. The differences between the two have to do with the cluster lifecycle and the resource isolation guarantees they provide.
Session Mode #
Session Mode assumes an already running cluster and uses the resources of that cluster to execute any submitted application. Applications executed in the same (session) cluster use, and consequently compete for, the same resources. This has the advantage that you do not pay the resource overhead of spinning up a full cluster for every submitted job. But, if one of the jobs misbehaves or brings down a TaskManager, then all jobs running on that TaskManager will be affected by the failure. Apart from a negative impact on the job that caused the failure, this implies a potential massive recovery process with all the restarting jobs accessing the file system concurrently and making it unavailable to other services. Additionally, having a single cluster running multiple jobs implies more load for the JobManager, which is responsible for the bookkeeping of all the jobs in the cluster. This mode is ideal for short jobs where startup latency is of high importance, e.g. interactive queries.
Per-Job Mode #
In Per-Job Mode, the available cluster manager framework (e.g. YARN or Kubernetes) is used to spin up a Flink cluster for each submitted job, which is available to that job only. When the job finishes, the cluster is shut down and any lingering resources (e.g. files) are cleaned up. This mode allows for better resource isolation, as a misbehaving job cannot affect any other job. In addition, it spreads the load of bookkeeping across multiple entities, as each application has its own JobManager. Given the aforementioned resource isolation concerns of the Session Mode, users often opt for the Per-Job Mode for long-running jobs which are willing to accept some increase in startup latency in favor of resilience.
To summarize, in Session Mode, the cluster lifecycle is independent of any job running on the cluster and all jobs running on the cluster share its resources. The per-job mode chooses to pay the price of spinning up a cluster for every submitted job, in order to provide better resource isolation guarantees as the resources are not shared across jobs. In this case, the lifecycle of the cluster is bound to that of the job.
Application Submission #
Flink application execution consists of two stages: pre-flight, when the users’ main()
method is called; and runtime, which is triggered as soon as the user code calls execute().
The main() method constructs the user program using one of Flink’s APIs
(DataStream API, Table API, DataSet API). When the main() method calls env.execute(),
the user-defined pipeline is translated into a form that Flink’s runtime can understand,
called the job graph, and it is shipped to the cluster.
Despite their differences, both session and per-job modes execute the application’s main()
method, i.e. the pre-flight phase, on the client side.1
This is usually not a problem for individual users who already have all the dependencies of their jobs locally, and then submit their applications through a client running on their machine. But in the case of submission through a remote entity like the Deployer, this process includes:
-
downloading the application’s dependencies locally,
-
executing the main()method to extract the job graph,
-
ship the job graph and its dependencies to the cluster for execution and,
-
potentially, wait for the result.
This makes the Client a heavy resource consumer as it may need substantial network
bandwidth to download dependencies and ship binaries to the cluster, and CPU cycles to
execute the main() method. This problem is even more pronounced as more users share
the same Client.
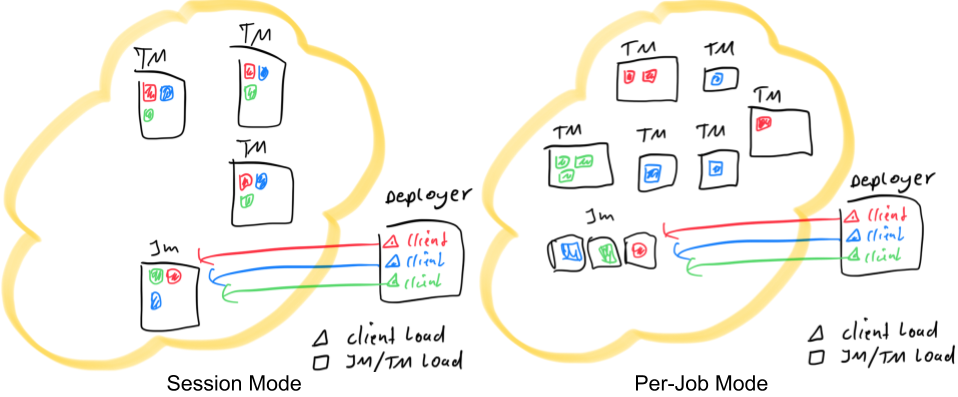
The figure above illustrates the two deployment modes using 3 applications depicted in red, blue and green. Each one has a parallelism of 3. The black rectangles represent different processes: TaskManagers, JobManagers and the Deployer; and we assume a single Deployer process in all scenarios. The colored triangles represent the load of the submission process, while the colored rectangles represent the load of the TaskManager and JobManager processes. As shown in the figure, the Deployer in both per-job and session mode share the same load. Their difference lies in the distribution of the tasks and the JobManager load. In the Session Mode, there is a single JobManager for all the jobs in the cluster while in the per-job mode, there is one for each job. In addition, tasks in Session Mode are assigned randomly to TaskManagers while in Per-Job Mode, each TaskManager can only have tasks of a single job.
Application Mode #
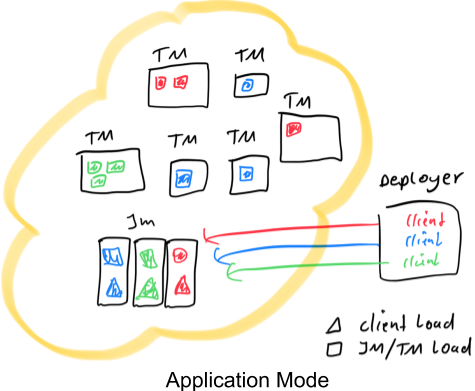
The Application Mode builds on the above observations and tries to combine the resource
isolation of the per-job mode with a lightweight and scalable application submission
process. To achieve this, it creates a cluster per submitted application, but this
time, the main() method of the application is executed on the JobManager.
Creating a cluster per application can be seen as creating a session cluster shared only among the jobs of a particular application and torn down when the application finishes. With this architecture, the Application Mode provides the same resource isolation and load balancing guarantees as the Per-Job Mode, but at the granularity of a whole application. This makes sense, as jobs belonging to the same application are expected to be correlated and treated as a unit.
Executing the main() method on the JobManager allows saving the CPU cycles required
for extracting the job graph, but also the bandwidth required on the client for
downloading the dependencies locally and shipping the job graph and its dependencies
to the cluster. Furthermore, it spreads the network load more evenly, as there is one
JobManager per application. This is illustrated in the figure above, where we have the
same scenario as in the session and per-job deployment mode section, but this time
the client load has shifted to the JobManager of each application.
Compared to the Per-Job Mode, the Application Mode allows the submission of applications
consisting of multiple jobs. The order of job execution is not affected by the deployment
mode but by the call used to launch the job. Using the blocking execute() method
establishes an order and will lead to the execution of the “next” job being postponed
until “this” job finishes. In contrast, the non-blocking executeAsync() method will
immediately continue to submit the “next” job as soon as the current job is submitted.
Reducing Network Requirements #
As described above, by executing the application’s main() method on the JobManager,
the Application Mode manages to save a lot of the resources previously required during
job submission. But there is still room for improvement.
Focusing on YARN, which already supports all the optimizations mentioned here2, and
even with the Application Mode in place, the Client is still required to send the user
jar to the JobManager. In addition, for each application, the Client has to ship to
the cluster the “flink-dist” directory which contains the binaries of the framework
itself, including the flink-dist.jar, lib/ and plugin/ directories. These two can
account for a substantial amount of bandwidth on the client side. Furthermore, shipping
the same flink-dist binaries on every submission is both a waste of bandwidth but also
of storage space which can be alleviated by simply allowing applications to share the
same binaries.
In Flink 1.11, we introduce options that allow the user to:
-
Specify a remote path to a directory where YARN can find the Flink distribution binaries, and
-
Specify a remote path where YARN can find the user jar.
For 1., we leverage YARN’s distributed cache and allow applications to share these binaries. So, if an application happens to find copies of Flink on the local storage of its TaskManager due to a previous application that was executed on the same TaskManager, it will not even have to download it internally.
Example: Application Mode on Yarn #
For a full description, please refer to the official Flink documentation and more specifically to the page that refers to your cluster management framework, e.g. YARN or Kubernetes. Here we will give some examples around YARN, where all the above features are available.
To launch an application in Application Mode, you can use:
./bin/flink run-application -t yarn-application ./MyApplication.jarWith this command, all configuration parameters, such as the path to a savepoint to
be used to bootstrap the application’s state or the required JobManager/TaskManager
memory sizes, can be specified by their configuration option, prefixed by -D. For
a catalog of the available configuration options, please refer to Flink’s
configuration page.
As an example, the command to specify the memory sizes of the JobManager and the TaskManager would look like:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
./MyApplication.jar
As discussed earlier, the above will make sure that your application’s main() method
will be executed on the JobManager.
To further save the bandwidth of shipping the Flink distribution to the cluster, consider
pre-uploading the Flink distribution to a location accessible by YARN and using the
yarn.provided.lib.dirs configuration option, as shown below:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \
./MyApplication.jar
Finally, in order to further save the bandwidth required to submit your application jar,
you can pre-upload it to HDFS, and specify the remote path that points to
./MyApplication.jar, as shown below:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \
hdfs://myhdfs/jars/MyApplication.jar
This will make the job submission extra lightweight as the needed Flink jars and the application jar are going to be picked up from the specified remote locations rather than be shipped to the cluster by the Client. The only thing the Client will ship to the cluster is the configuration of your application which includes all the aforementioned paths.
Conclusion #
We hope that this discussion helped you understand the differences between the various deployment modes offered by Flink and will help you to make informed decisions about which one is suitable in your own setup. Feel free to play around with them and report any issues you may find. If you have any questions or requests, do not hesitate to post them in the mailing lists and, hopefully, see you (virtually) at one of our conferences or meetups soon!