Advanced Flink Application Patterns Vol.3: Custom Window Processing
July 30, 2020 - Alexander Fedulov (@alex_fedulov)
Introduction #
In the previous articles of the series, we described how you can achieve flexible stream partitioning based on dynamically-updated configurations (a set of fraud-detection rules) and how you can utilize Flink's Broadcast mechanism to distribute processing configuration at runtime among the relevant operators.
Following up directly where we left the discussion of the end-to-end solution last time, in this article we will describe how you can use the "Swiss knife" of Flink - the Process Function to create an implementation that is tailor-made to match your streaming business logic requirements. Our discussion will continue in the context of the Fraud Detection engine. We will also demonstrate how you can implement your own custom replacement for time windows for cases where the out-of-the-box windowing available from the DataStream API does not satisfy your requirements. In particular, we will look at the trade-offs that you can make when designing a solution which requires low-latency reactions to individual events.
This article will describe some high-level concepts that can be applied independently, but it is recommended that you review the material in part one and part two of the series as well as checkout the code base in order to make it easier to follow along.
ProcessFunction as a “Window” #
Low Latency #
Let’s start with a reminder of the type of fraud detection rule that we would like to support:
“Whenever the sum of payments from the same payer to the same beneficiary within a 24 hour period is greater than 200 000 $ - trigger an alert.”
In other words, given a stream of transactions partitioned by a key that combines the payer and the beneficiary fields, we would like to look back in time and determine, for each incoming transaction, if the sum of all previous payments between the two specific participants exceeds the defined threshold. In effect, the computation window is always moved along to the position of the last observed event for a particular data partitioning key.
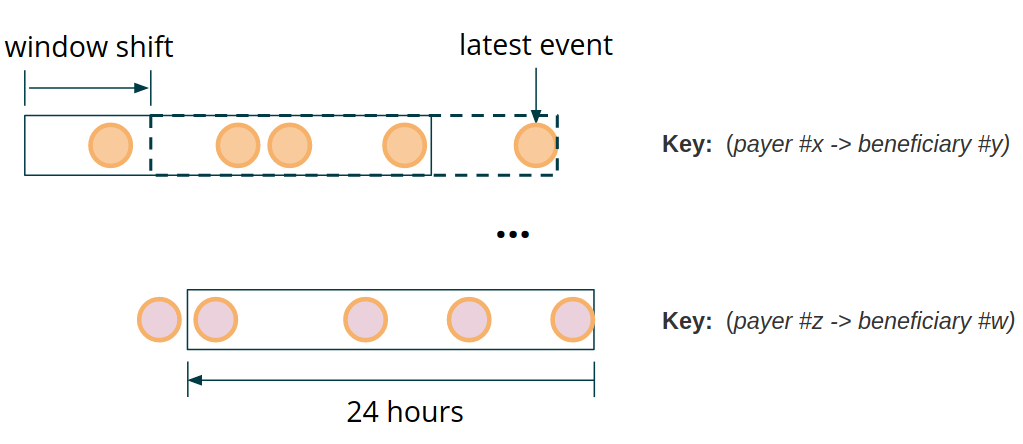
Figure 1: Time Windows
One of the common key requirements for a fraud detection system is low response time. The sooner the fraudulent action gets detected, the higher the chances that it can be blocked and its negative consequences mitigated. This requirement is especially prominent in the financial domain, where you have one important constraint - any time spent evaluating a fraud detection model is time that a law-abiding user of your system will spend waiting for a response. Swiftness of processing often becomes a competitive advantage between various payment systems and the time limit for producing an alert could lie as low as 300-500 ms. This is all the time you get from the moment of ingestion of a transaction event into a fraud detection system until an alert has to become available to downstream systems.
As you might know, Flink provides a powerful Window API that is applicable for a wide range of use cases. However, if you go over all of the available types of supported windows, you will realize that none of them exactly match our main requirement for this use case - the low-latency evaluation of each incoming transaction. There is no type of window in Flink that can express the “x minutes/hours/days back from the current event” semantic. In the Window API, events fall into windows (as defined by the window assigners), but they cannot themselves individually control the creation and evaluation of windows*. As described above, our goal for the fraud detection engine is to achieve immediate evaluation of the previous relevant data points as soon as the new event is received. This raises the question of feasibility of applying the Window API in this case. The Window API offers some options for defining custom triggers, evictors, and window assigners, which may get to the required result. However, it is usually difficult to get this right (and easy to break). Moreover, this approach does not provide access to broadcast state, which is required for implementing dynamic reconfiguration of business rules.
*) apart from the session windows, but they are limited to assignments based on the session gaps
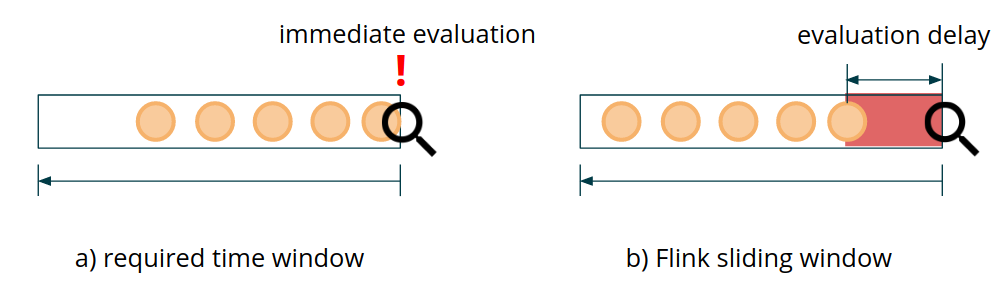
Figure 2: Evaluation Delays
Let’s take an example of using a sliding window from Flink’s Window API. Using sliding windows with the slide of S translates into an expected value of evaluation delay equal to S/2. This means that you would need to define a window slide of 600-1000 ms to fulfill the low-latency requirement of 300-500 ms delay, even before taking any actual computation time into account. The fact that Flink stores a separate window state for each sliding window pane renders this approach unfeasible under any moderately high load conditions.
In order to satisfy the requirements, we need to create our own
low-latency window implementation. Luckily, Flink gives us all the tools
required to do so. ProcessFunction is a low-level, but powerful
building block in Flink's API. It has a simple contract:
public class SomeProcessFunction extends KeyedProcessFunction<KeyType, InputType, OutputType> {
public void processElement(InputType event, Context ctx, Collector<OutputType> out){}
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OutputType> out) {}
public void open(Configuration parameters){}
}
-
processElement()receives input events one by one. You can react to each input by producing one or more output events to the next operator by callingout.collect(someOutput). You can also pass data to a side output or ignore a particular input altogether. -
onTimer()is called by Flink when a previously-registered timer fires. Both event time and processing time timers are supported. -
open()is equivalent to a constructor. It is called inside of the TaskManager’s JVM, and is used for initialization, such as registering Flink-managed state. It is also the right place to initialize fields that are not serializable and cannot be transferred from the JobManager’s JVM.
Most importantly, ProcessFunction also has access to the fault-tolerant
state, handled by Flink. This combination, together with Flink's
message processing and delivery guarantees, makes it possible to build
resilient event-driven applications with almost arbitrarily
sophisticated business logic. This includes creation and processing of
custom windows with state.
Implementation #
State and Clean-up #
In order to be able to process time windows, we need to keep track of data belonging to the window inside of our program. To ensure that this data is fault-tolerant and can survive failures in a distributed system, we should store it inside of Flink-managed state. As the time progresses, we do not need to keep all previous transactions. According to the sample rule, all events that are older than 24 hours become irrelevant. We are looking at a window of data that constantly moves and where stale transactions need to be constantly moved out of scope (in other words, cleaned up from state).
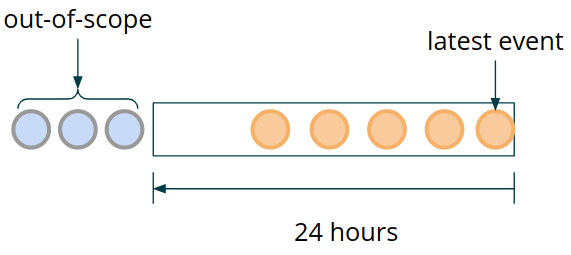
Figure 3: Window Clean-up
We will
use
MapState to store the individual events of the window. In order to allow
efficient clean-up of the out-of-scope events, we will utilize event
timestamps as the MapState keys.
In a general case, we have to take into account the fact that there might be different events with exactly the same timestamp, therefore instead of individual Transaction per key(timestamp) we will store sets.
MapState<Long, Set<Transaction>> windowState;
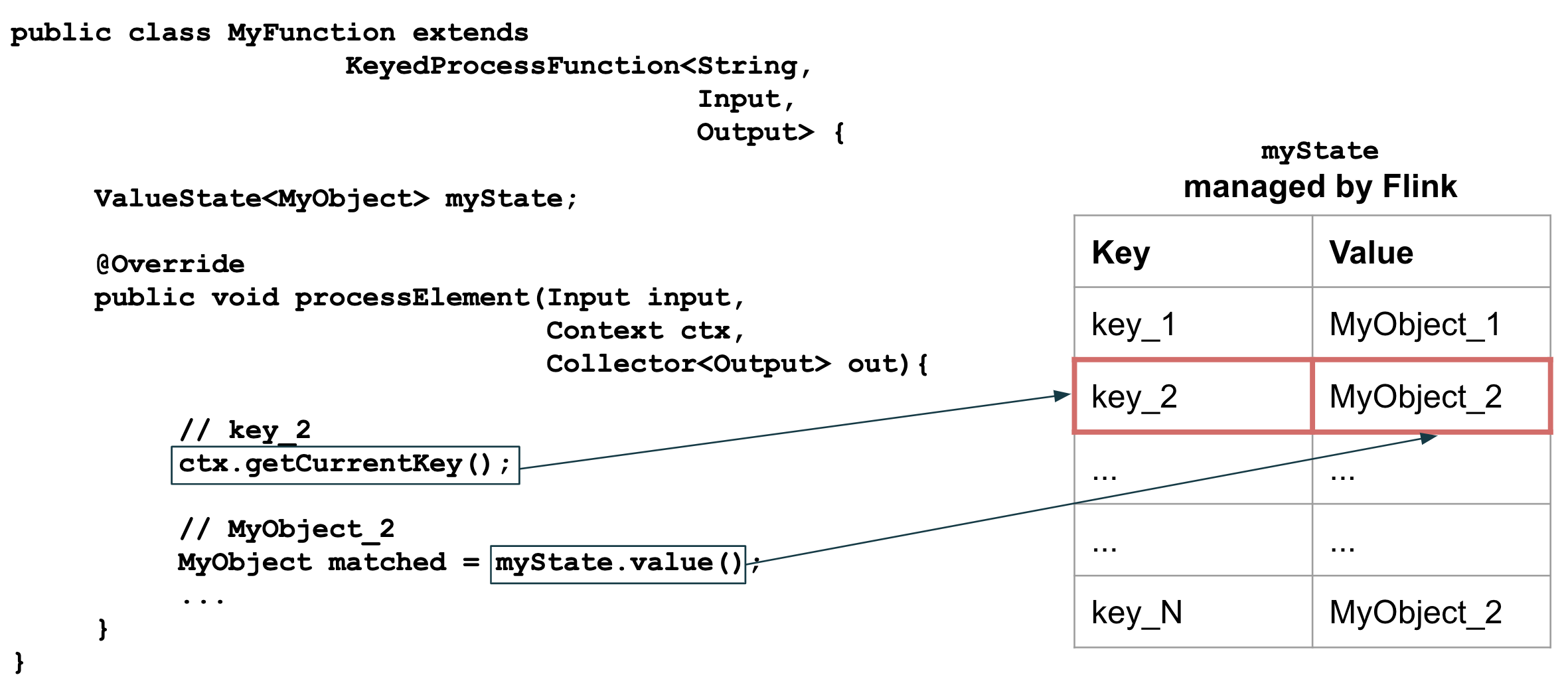
Figure 4: Keyed State Scoping
As described in the first blog of the series, we are dispatching events based on the keys
specified in the active fraud detection rules. Multiple distinct rules
can be based on the same grouping key. This means that our alerting
function can potentially receive transactions scoped by the same key
(e.g. {payerId=25;beneficiaryId=12}), but destined to be evaluated
according to different rules, which implies potentially different
lengths of the time windows. This raises the question of how can we best
store fault-tolerant window state within the KeyedProcessFunction. One
approach would be to create and manage separate MapStates per rule. Such
an approach, however, would be wasteful - we would separately hold state
for overlapping time windows, and therefore unnecessarily store
duplicate events. A better approach is to always store just enough data
to be able to estimate all currently active rules which are scoped by
the same key. In order to achieve that, whenever a new rule is added, we
will determine if its time window has the largest span and store it in
the broadcast state under the special reserved WIDEST_RULE_KEY. This
information will later be used during the state clean-up procedure, as
described later in this section.
@Override
public void processBroadcastElement(Rule rule, Context ctx, Collector<Alert> out){
...
updateWidestWindowRule(rule, broadcastState);
}
private void updateWidestWindowRule(Rule rule, BroadcastState<Integer, Rule> broadcastState){
Rule widestWindowRule = broadcastState.get(WIDEST_RULE_KEY);
if (widestWindowRule == null) {
broadcastState.put(WIDEST_RULE_KEY, rule);
return;
}
if (widestWindowRule.getWindowMillis() < rule.getWindowMillis()) {
broadcastState.put(WIDEST_RULE_KEY, rule);
}
}
Let’s now look at the implementation of the main method,
processElement(), in some detail.
In the previous blog post, we described how DynamicKeyFunction allowed
us to perform dynamic data partitioning based on the groupingKeyNames
parameter in the rule definition. The subsequent description is focused
around the DynamicAlertFunction, which makes use of the remaining rule
settings.

Figure 5: Sample Rule Definition
As described in the previous parts of the blog post
series, our alerting process function receives events of type
Keyed<Transaction, String, Integer>, where Transaction is the main
“wrapped” event, String is the key (payer #x - beneficiary #y in
Figure 1), and Integer is the ID of the rule that caused the dispatch of
this event. This rule was previously stored in the broadcast state and has to be retrieved from that state by the ID. Here is the
outline of the implementation:
public class DynamicAlertFunction
extends KeyedBroadcastProcessFunction<
String, Keyed<Transaction, String, Integer>, Rule, Alert> {
private transient MapState<Long, Set<Transaction>> windowState;
@Override
public void processElement(
Keyed<Transaction, String, Integer> value, ReadOnlyContext ctx, Collector<Alert> out){
// Add Transaction to state
long currentEventTime = value.getWrapped().getEventTime(); // <--- (1)
addToStateValuesSet(windowState, currentEventTime, value.getWrapped());
// Calculate the aggregate value
Rule rule = ctx.getBroadcastState(Descriptors.rulesDescriptor).get(value.getId()); // <--- (2)
Long windowStartTimestampForEvent = rule.getWindowStartTimestampFor(currentEventTime);// <--- (3)
SimpleAccumulator<BigDecimal> aggregator = RuleHelper.getAggregator(rule); // <--- (4)
for (Long stateEventTime : windowState.keys()) {
if (isStateValueInWindow(stateEventTime, windowStartForEvent, currentEventTime)) {
aggregateValuesInState(stateEventTime, aggregator, rule);
}
}
// Evaluate the rule and trigger an alert if violated
BigDecimal aggregateResult = aggregator.getLocalValue(); // <--- (5)
boolean isRuleViolated = rule.apply(aggregateResult);
if (isRuleViolated) {
long decisionTime = System.currentTimeMillis();
out.collect(new Alert<>(rule.getRuleId(),
rule,
value.getKey(),
decisionTime,
value.getWrapped(),
aggregateResult));
}
// Register timers to ensure state cleanup
long cleanupTime = (currentEventTime / 1000) * 1000; // <--- (6)
ctx.timerService().registerEventTimeTimer(cleanupTime);
}
Here are the details of the steps: 1) We first add each new event to our window state:
static <K, V> Set<V> addToStateValuesSet(MapState<K, Set<V>> mapState, K key, V value)
throws Exception {
Set<V> valuesSet = mapState.get(key);
if (valuesSet != null) {
valuesSet.add(value);
} else {
valuesSet = new HashSet<>();
valuesSet.add(value);
}
mapState.put(key, valuesSet);
return valuesSet;
}
-
Next, we retrieve the previously-broadcasted rule, according to which the incoming transaction needs to be evaluated.
-
getWindowStartTimestampFordetermines, given the window span defined in the rule, and the current transaction timestamp, how far back in time our evaluation should span. -
The aggregate value is calculated by iterating over all window state entries and applying an aggregate function. It could be an average, max, min or, as in the example rule from the beginning of this section, a sum.
private boolean isStateValueInWindow(
Long stateEventTime, Long windowStartForEvent, long currentEventTime) {
return stateEventTime >= windowStartForEvent && stateEventTime <= currentEventTime;
}
private void aggregateValuesInState(
Long stateEventTime, SimpleAccumulator<BigDecimal> aggregator, Rule rule) throws Exception {
Set<Transaction> inWindow = windowState.get(stateEventTime);
for (Transaction event : inWindow) {
BigDecimal aggregatedValue =
FieldsExtractor.getBigDecimalByName(rule.getAggregateFieldName(), event);
aggregator.add(aggregatedValue);
}
}
-
Having an aggregate value, we can compare it to the threshold value that is specified in the rule definition and fire an alert, if necessary.
-
At the end, we register a clean-up timer using
ctx.timerService().registerEventTimeTimer(). This timer will be responsible for removing the current transaction when it is going to move out of scope.
- The
onTimermethod will trigger the clean-up of the window state.
As previously described, we are always keeping as many events in the state as required for the evaluation of an active rule with the widest window span. This means that during the clean-up, we only need to remove the state which is out of scope of this widest window.

Figure 6: Widest Window
This is how the clean-up procedure can be implemented:
@Override
public void onTimer(final long timestamp, final OnTimerContext ctx, final Collector<Alert> out)
throws Exception {
Rule widestWindowRule = ctx.getBroadcastState(Descriptors.rulesDescriptor).get(WIDEST_RULE_KEY);
Optional<Long> cleanupEventTimeWindow =
Optional.ofNullable(widestWindowRule).map(Rule::getWindowMillis);
Optional<Long> cleanupEventTimeThreshold =
cleanupEventTimeWindow.map(window -> timestamp - window);
// Remove events that are older than (timestamp - widestWindowSpan)ms
cleanupEventTimeThreshold.ifPresent(this::evictOutOfScopeElementsFromWindow);
}
private void evictOutOfScopeElementsFromWindow(Long threshold) {
try {
Iterator<Long> keys = windowState.keys().iterator();
while (keys.hasNext()) {
Long stateEventTime = keys.next();
if (stateEventTime < threshold) {
keys.remove();
}
}
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
This concludes the description of the implementation details. Our approach triggers evaluation of a time window as soon as a new transaction arrives. It therefore fulfills the main requirement that we have targeted - low delay for potentially issuing an alert. For the complete implementation, please have a look at the project on github.
Improvements and Optimizations #
What are the pros and cons of the described approach?
Pros:
-
Low latency capabilities
-
Tailored solution with potential use-case specific optimizations
-
Efficient state reuse (shared state for the rules with the same key)
Cons:
-
Cannot make use of potential future optimizations in the existing Window API
-
No late event handling, which is available out of the box in the Window API
-
Quadratic computation complexity and potentially large state
Let’s now look at the latter two drawbacks and see if we can address them.
Late events: #
Processing late events poses a certain question - is it still meaningful to re-evaluate the window in case of a late event arrival? In case this is required, you would need to extend the widest window used for the clean-up by your maximum expected out-of-orderness. This would avoid having potentially incomplete time window data for such late firings (see Figure 7).
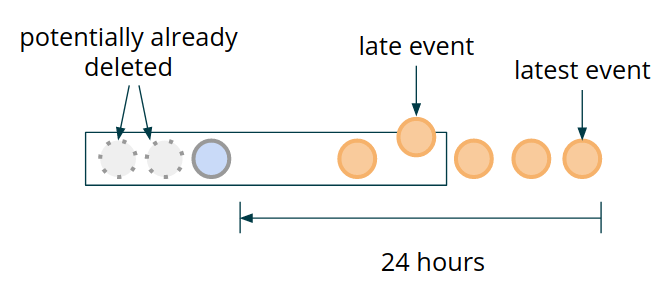
Figure 7: Late Events Handling
It can be argued, however, that for a use case that puts emphasis on low latency processing, such late triggering would be meaningless. In this case, we could keep track of the most recent timestamp that we have observed so far, and for events that do not monotonically increase this value, only add them to the state and skip the aggregate calculation and the alert triggering logic.
Redundant Re-computations and State Size: #
In our described implementation we keep individual transactions in state and go over them to calculate the aggregate again and again on every new event. This is obviously not optimal in terms of wasting computational resources on repeated calculations.
What is the main reason to keep the individual transactions in state? The granularity of stored events directly corresponds to the precision of the time window calculation. Because we store transactions individually, we can precisely ignore individual transactions as soon as they leave the exact 2592000000 ms time window (30 days in ms). At this point, it is worth raising the question - do we really need this milliseconds precision when estimating such a long time window, or is it OK to accept potential false positives in exceptional cases? If the answer for your use case is that such precision is not needed, you could implement additional optimization based on bucketing and pre-aggregation. The idea of this optimization can be broken down as follows:
-
Instead of storing individual events, create a parent class that can either contain fields of a single transaction, or combined values, calculated based on applying an aggregate function to a set of transactions.
-
Instead of using timestamps in milliseconds as
MapStatekeys, round them to the level of “resolution” that you are willing to accept (for instance, a full minute). Each entry therefore represents a bucket. -
Whenever a window is evaluated, append the new transaction’s data to the bucket aggregate instead of storing individual data points per transaction.
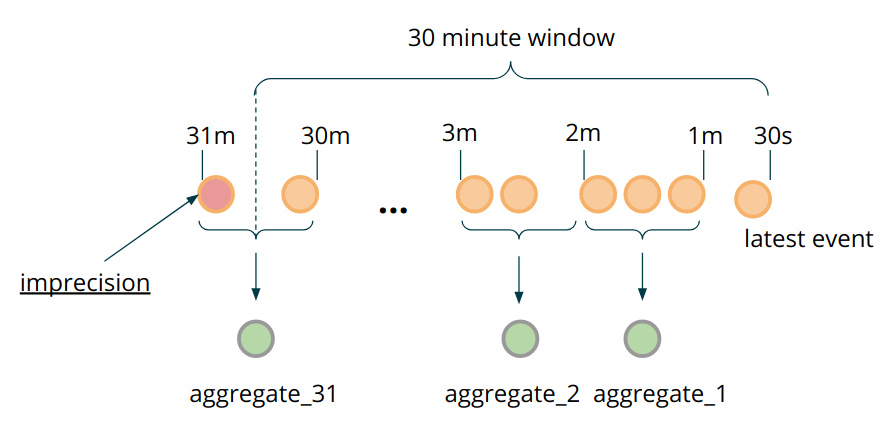
Figure 8: Pre-aggregation
State Data and Serializers #
Another question that we can ask ourselves in order to further optimize
the implementation is how probable is it to get different events with
exactly the same timestamp. In the described implementation, we
demonstrated one way of approaching this question by storing sets of
transactions per timestamp in MapState<Long, Set<Transaction>>. Such
a choice, however, might have a more significant effect on performance
than might be anticipated. The reason is that Flink does not currently
provide a native Set serializer and will enforce a fallback to the less
efficient Kryo
serializer
instead
(FLINK-16729). A
meaningful alternative strategy is to assume that, in a normal scenario,
no two discrepant events can have exactly the same timestamp and to turn
the window state into a MapState<Long, Transaction> type. You can use
side-outputs
to collect and monitor any unexpected occurrences which contradict your
assumption. During performance optimizations, I generally recommend you
to disable the fallback to
Kryo
and verify where your application might be further optimized by ensuring
that more efficient
serializers
are being used.
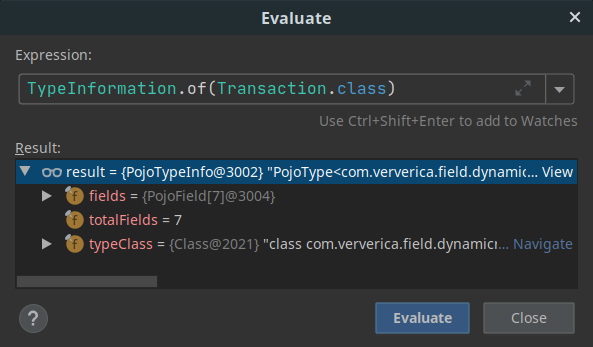 |
PojoTypeInfo indicates that an efficient Flink POJO serializer will be used. |
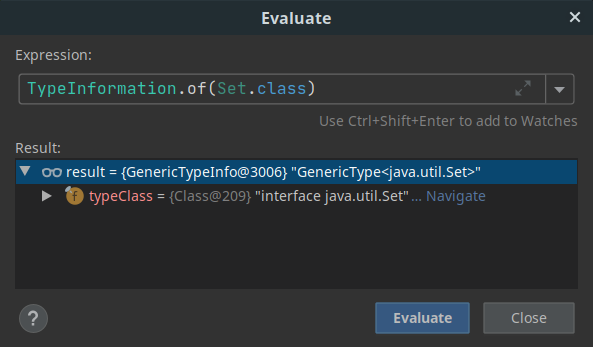 |
GenericTypeInfo indicates the fallback to a Kryo serializer. |
Event pruning: Instead of storing complete events and putting
additional stress on the ser/de machinery, we can reduce individual
events data to only relevant information. This would potentially require
“unpacking” individual events as fields, and storing those fields into a
generic Map<String, Object> data structure, based on the
configurations of active rules.
While this adjustment could potentially produce significant improvements for objects of large size, it should not be your first pick as it can easily turn into a premature optimization.
Summary: #
This article concludes the description of the implementation of the
fraud detection engine that we started in part one. In this blog
post we demonstrated how ProcessFunction can be utilized to
"impersonate" a window with a sophisticated custom logic. We have
discussed the pros and cons of such approach and elaborated how custom
use-case-specific optimizations can be applied - something that would
not be directly possible with the Window API.
The goal of this blog post was to illustrate the power and flexibility of Apache Flink’s APIs. At the core of it are the pillars of Flink, that spare you, as a developer, very significant amounts of work and generalize well to a wide range of use cases by providing:
-
Efficient data exchange in a distributed cluster
-
Horizontal scalability via data partitioning
-
Fault-tolerant state with quick, local access
-
Convenient abstraction for working with this state, which is as simple as using a local variable
-
Multi-threaded, parallel execution engine.
ProcessFunctioncode runs in a single thread, without the need for synchronization. Flink handles all the parallel execution aspects and correct access to the shared state, without you, as a developer, having to think about it (concurrency is hard).
All these aspects make it possible to build applications with Flink that go well beyond trivial streaming ETL use cases and enable implementation of arbitrarily-sophisticated, distributed event-driven applications. With Flink, you can rethink approaches to a wide range of use cases which normally would rely on using stateless parallel execution nodes and “pushing” the concerns of state fault tolerance to a database, an approach that is often destined to run into scalability issues in the face of ever-increasing data volumes.