Monitoring and Controlling Networks of IoT Devices with Flink Stateful Functions
August 18, 2020 - Igal Shilman (@IgalShilman)In this blog post, we’ll take a look at a class of use cases that is a natural fit for Flink Stateful Functions: monitoring and controlling networks of connected devices (often called the “Internet of Things” (IoT)).
IoT networks are composed of many individual, but interconnected components, which makes getting some kind of high-level insight into the status, problems, or optimization opportunities in these networks not trivial. Each individual device “sees” only its own state, which means that the status of groups of devices, or even the network as a whole, is often a complex aggregation of the individual devices’ state. Diagnosing, controlling, or optimizing these groups of devices thus requires distributed logic that analyzes the “bigger picture” and then acts upon it.
A powerful approach to implement this is using digital twins: each device has a corresponding virtual entity (i.e. the digital twin), which also captures their relationships and interactions. The digital twins track the status of their corresponding devices and send updates to other twins, representing groups (such as geographical regions) of devices. Those, in turn, handle the logic to obtain the network’s aggregated view, or this “bigger picture” we mentioned before.
Our Scenario: Datacenter Monitoring and Alerting #

There are many examples of the digital twins approach in the real world, such as smart grids of batteries, smart cities, or monitoring infrastructure software clusters. In this blogpost, we’ll use the example of data center monitoring and alert correlation implemented with Stateful Functions.
Consider a very simplified view of a data center, consisting of many thousands of commodity servers arranged in server racks. Each server rack typically contains up to 40 servers, with a ToR (Top of the Rack) network switch connected to each server. The switches from all the racks connect through a larger switch (Fig. 1).
In this datacenter, many things can go wrong: a disk in a server can stop working, network cards can start dropping packets, or ToR switches might cease to function. The entire data center might also be affected by power supply degradation, causing servers to operate at reduced capacity. On-site engineers must be able to identify these incidents quickly and fix them promptly.
Diagnosing individual server failures is rather straightforward: take a recent history of metric reports from that particular server, analyse it and pinpoint the anomaly. On the other hand, other incidents only make sense “together”, because they share a common root cause. Diagnosing or predicting causes of networking degradation at a rack or datacenter level requires an aggregate view of metrics (such as package drop rates) from the individual machines and racks, and possibly some prediction model or diagnosis code that runs under certain conditions.
Monitoring a Virtual Datacenter via Digital Twins #
For the sake of this blog post, our oversimplified data center has some servers and racks, each with a unique ID. Each server has a metrics-collecting daemon that publishes metrics to a message queue, and there is a provisioning service that operators will use to ask for server commission- and decommissioning.
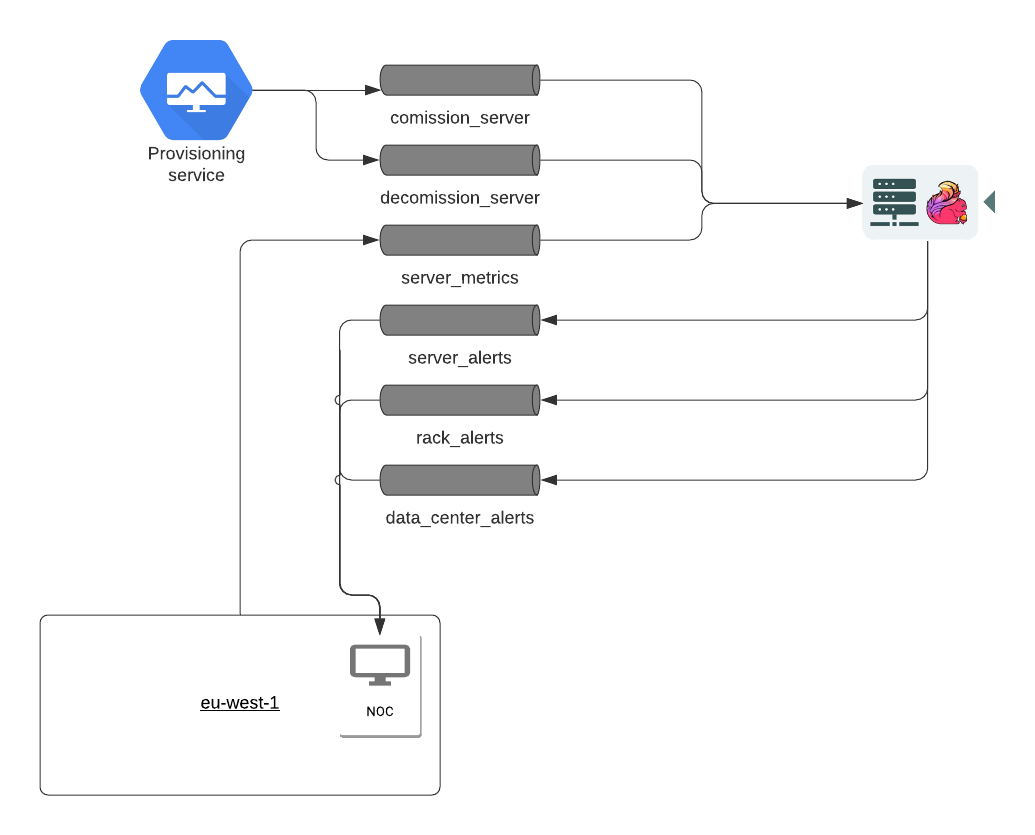
Our application will consume these server metrics and commission/decommission events, and produce server/rack/datacenter alerts. There will also be an operator consuming any alerts triggered by the monitoring system. In the next section, we’ll show how this use case can be naturally modeled with Stateful Functions (StateFun).
Implementing the use case with Flink StateFun #
The basic building block for modeling a StateFun application is a stateful function, which has the following properties:
-
It has a logical unique address; and persisted, fault tolerant state, scoped to that address.
-
It can react to messages, both internal (or, sent from other stateful functions) and external (e.g. a message from Kafka).
-
Invocations of a specific function are serializable, so messages sent to a specific address are not executed concurrently.
-
There can be many billions of function instances in a single StateFun cluster.
To model our use case, we’ll define three functions: ServerFun, RackFun and DataCenterFun.
ServerFun
Each physical server is represented with its digital twin stateful function. This function is responsible for:
-
Maintaining a sliding window of incoming metrics.
-
Applying a model that decides whether or not to trigger an alert.
-
Alerting if metrics are missing for too long.
-
Notifying its containing RackFun about any open incidents.
RackFun
While the ServerFun is responsible for identifying server-local incidents, we need a function that correlates incidents happening on the different servers deployed in the same rack and:
-
Collects open incidents reported by the ServerFun functions.
-
Maintains an histogram of currently opened incidents on this rack.
-
Applies a correlation model to the individual incidents sent by the ServerFun, and reports high-level, related incidents as a single incident to the DataCenterFun.
DataCenterFun
This function maintains a view of incidents across different racks in our datacenter.
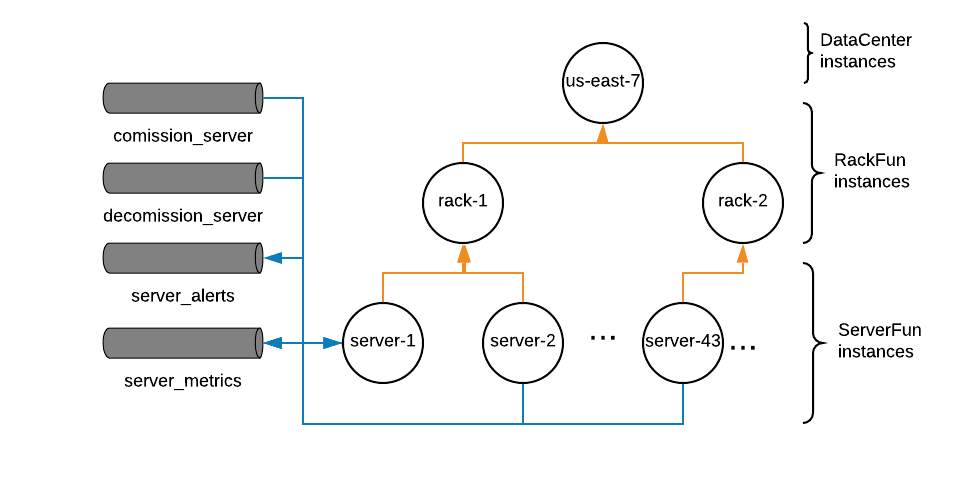
To summarize our plan:
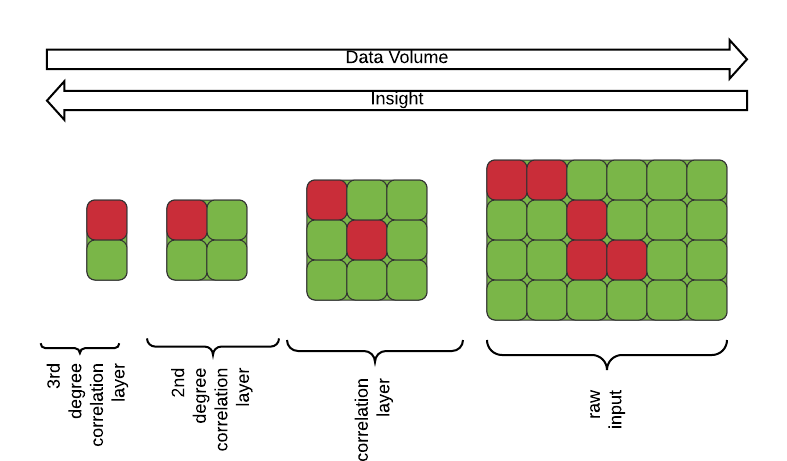
-
Leaf functions ingest raw metric data (blue lines), and apply localized logic to trigger an alert.
-
Intermediate functions operate on already summarized events (orange lines) and correlate them into high-level events.
-
A root function correlates the high-level events across the intermediate functions and into a single healthy/not healthy value.
How does it really look? #
ServerFun #
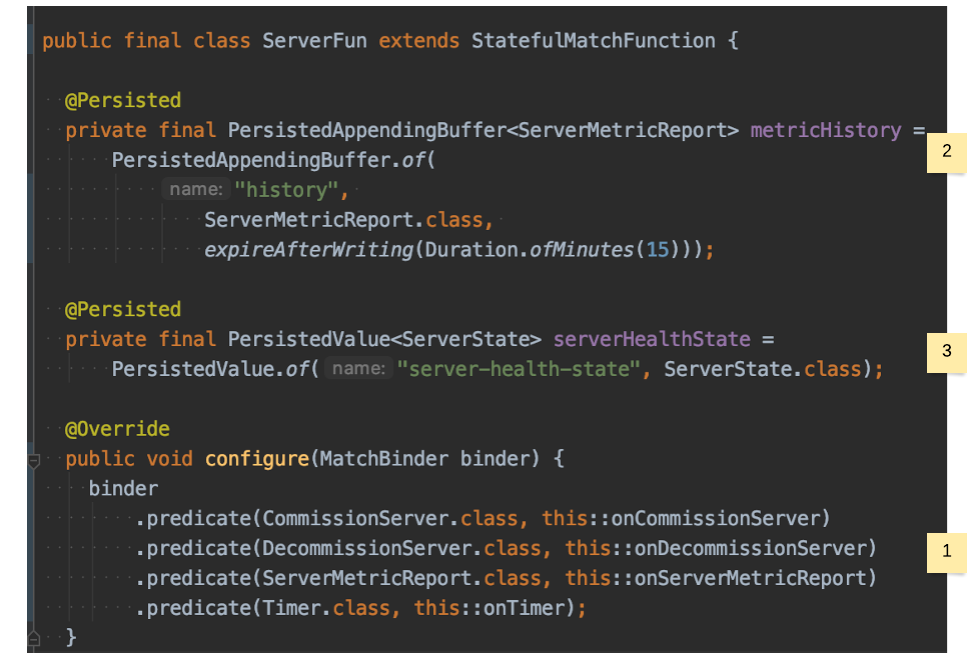
- This section associates a behaviour for every message that the function expects to be invoked with.
- The
metricsHistorybuffer is our sliding window of the last 15 minutes worth ofServerMetricReports. Note that this buffer is configured to expire entries 15 minutes after they were written. serverHealthStaterepresents the current physical server state, open incidents and so on.
Let’s take a look at what happens when a ServerMetricReport message arrives:

- Retrieve the previously computed
serverHealthStatethat is kept in state. - Evaluate a model on the sliding window of the previous metric reports + the current metric reported + the previously computed server state to obtain an assessment of the current server health.
- If the server is not believed to be healthy, emit an alert via an alerts topic, and also send a message to our containing rack with all the open incidents that this server currently has.
RackFun #
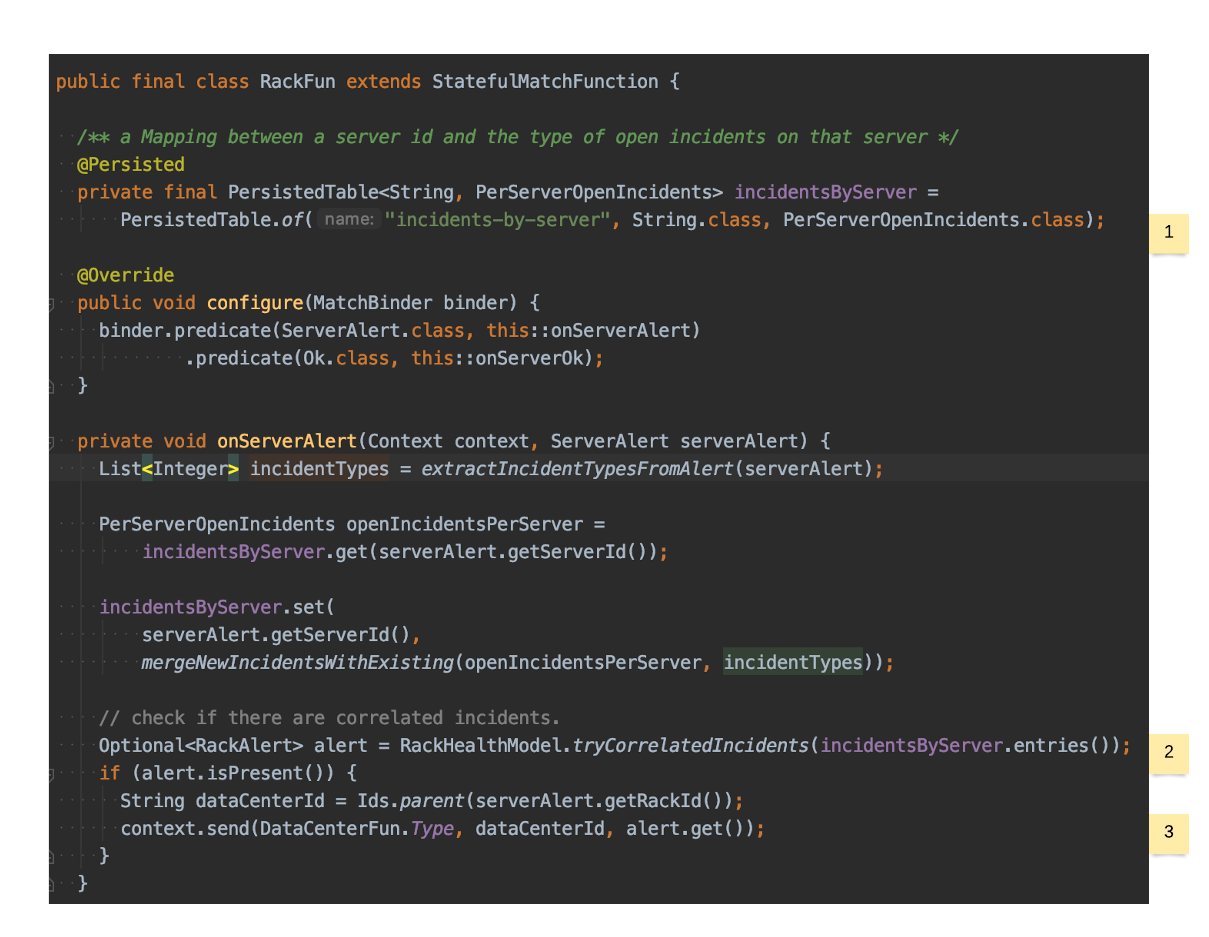
- This function keeps a mapping between a
ServerIdand a set of open incidents on that server. - When new alerts are received, this function tries to correlate the alert with any other open alerts on that rack. If a correlated rack alert is present, this function notifies the DataCenterFun about it.
DataCenterFun #
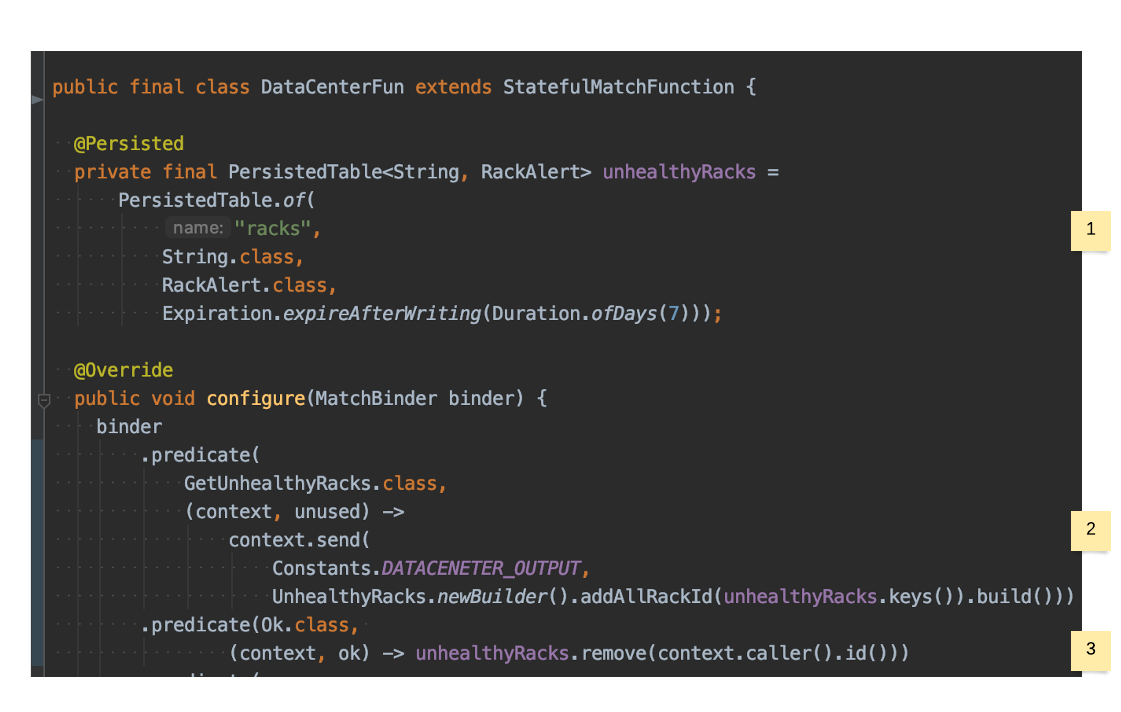
- A persisted mapping between a
RackIdand the latest alert that rack reported. - Throughout the usage of ingress/egress pairs, this function can report back its current view of the world of what racks are currently known to be unhealthy.
- An operator (via a front-end) can send a
GetUnhealthyRacksmessage addressed to that DataCenterFun, and wait for the corresponding responsemessage(UnhealthyRacks). Whenever a rack reports OK, it’ll be removed from the unhealthy racks map.
Conclusion #
This pattern — where each layer of functions performs a stateful aggregation of events sent from the previous layer (or the input) — is useful for a whole class of problems. And, although we used connected devices to motivate this use case, it’s not limited to the IoT domain.
Stateful Functions provides the building blocks necessary for building complex distributed applications (here the digital twins that support analysis and interactions of the physical entities), while removing common complexities of distributed systems like service discovery, retires, circuit breakers, state management, scalability and similar challenges. If you’d like to learn more about Stateful Functions, head over to the official documentation, where you can also find more hands-on tutorials to try out yourself!