From Aligned to Unaligned Checkpoints - Part 1: Checkpoints, Alignment, and Backpressure
October 15, 2020 - Arvid Heise Stephan EwenApache Flink’s checkpoint-based fault tolerance mechanism is one of its defining features. Because of that design, Flink unifies batch and stream processing, can easily scale to both very small and extremely large scenarios and provides support for many operational features like stateful upgrades with state evolution or roll-backs and time-travel.
Despite all these great properties, Flink’s checkpointing method has an Achilles Heel: the speed of a completed checkpoint is determined by the speed at which data flows through the application. When the application backpressures, the processing of checkpoints is backpressured as well (Appendix 1 recaps what is backpressure and why it can be a good thing). In such cases, checkpoints may take longer to complete or even time out completely.
In Flink 1.11, the community introduced a first version of a new feature called “unaligned checkpoints” that aims at solving this issue, while Flink 1.12 plans to further expand its functionality. In this two-series blog post, we discuss how Flink’s checkpointing mechanism has been modified to support unaligned checkpoints, how unaligned checkpoints work, and how this new mode impacts Flink users. In the first of the two posts, we start with a recap of the original checkpointing process in Flink, its core properties and issues under backpressure.
State in Streaming Applications #
Simply put, state is the information that you need to remember across events. Even the most trivial streaming applications are typically stateful because of their need to “remember” the exact position they are processing data from, for example in the form of a Kafka Partition Offset or a File Offset. In addition, many applications hold state internally as a way to support their internal operations, such as windows, aggregations, joins, or state machines.
For the remainder of this article, we’ll use the following example showing a streaming application consisting of four operators, each one holding some state.

State Persistence through Checkpoints #
Streaming applications are long-lived. They inevitably experience hardware and software failures but should, ideally, look from the outside as if no failure ever happened. Since applications are long-lived — and can potentially accumulate very large state —, recomputing partial results after failures can take quite some time, and so a way to persist and recover this (potentially very large) application state is necessary.
Flink relies on its state checkpointing and recovery mechanism to implement such behavior, as shown in the figure below. Periodic checkpoints store a snapshot of the application’s state on some Checkpoint Storage (commonly an Object Store or Distributed File System, like S3, HDFS, GCS, Azure Blob Storage, etc.). When a failure is detected, the affected parts of the application are reset to the state of the latest checkpoint (either by a local reset or by loading the state from the checkpoint storage).
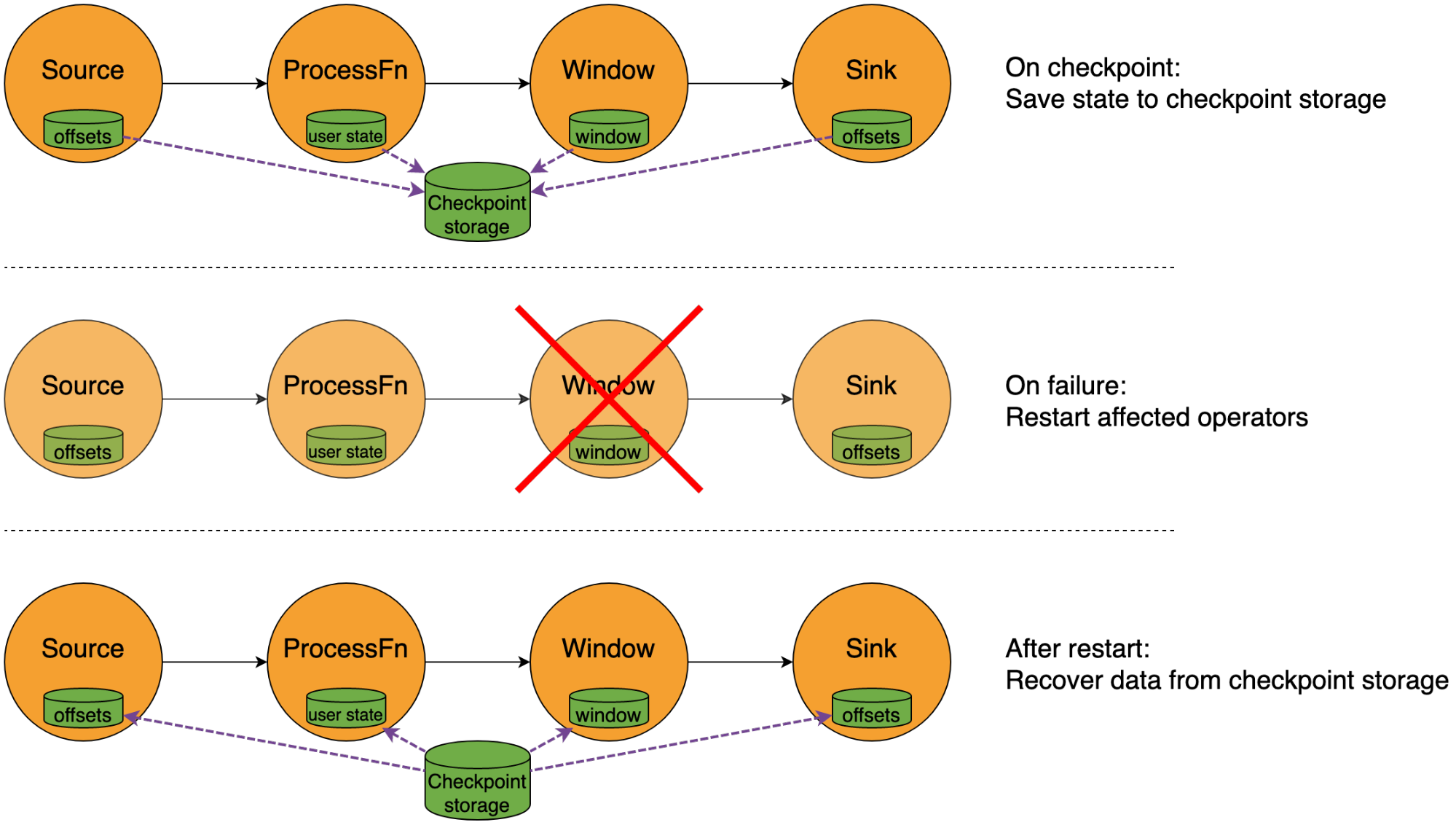
Flink’s checkpoint-based approach differs from the approach taken by other stream processing systems that keep state in a distributed database or write state changes to a log, for example. The checkpoint-based approach has some nice properties, described below, which make it a great option for Flink.
-
Checkpointing has very simple external dependencies: An Object Storage or a Distributed FileSystem are probably the most available and easiest-to-administer services. Because these are available on all public cloud providers and among the first systems to provide on-premises, Flink becomes well-suited for a cloud-native stack. In addition, these storage systems are cheaper by an order of magnitude (GB/month) when compared to distributed databases, key/value stores, or event brokers.
-
Checkpoints are immutable and versioned: Together with immutable and versioned inputs (as input streams are, by nature), checkpoints support storing immutable application snapshots that can be used for rollbacks, debugging, testing, or as a cheap alternative to analyze application state outside the production setup.
-
Checkpoints decouple the “stream transport” from the persistence mechanism: “Stream transport” refers to how data is being exchanged between operators (e.g. during a shuffle). This decoupling is key to Flink’s batch <-> streaming unification in one system, because it allows Flink to implement a data transport that can take the shape of both a low-latency streaming exchange or a decoupled batch data exchange.
The Checkpointing Mechanism #
The fundamental challenge solved by the checkpointing algorithm (details in this paper) is drawing a snapshot out of the ever-changing state of a streaming application without suspending the continuous processing of events. Because there are always events in-flight (on the network, in I/O buffers, etc.), up- and downstream operators can be processing events from different times: the sink may write data from 11:04, while the source already ingests events from 11:06. Ideally, all snapshotted data should belong to the same point-in-time, as if the input was paused and we waited until all in-flight data was drained (i.e. the pipeline becoming idle) before taking the snapshot.
To achieve that, Flink injects checkpoint barriers into the streams at the sources, which travel through the entire topology and eventually reach the sinks. These barriers divide the stream into a pre-checkpoint epoch (all events that are persisted in state or emitted into sinks) and a post-checkpoint epoch (events not reflected in the state, to be re-processed when resuming from the checkpoint).
The following figure shows what happens when a barrier reaches an operator.
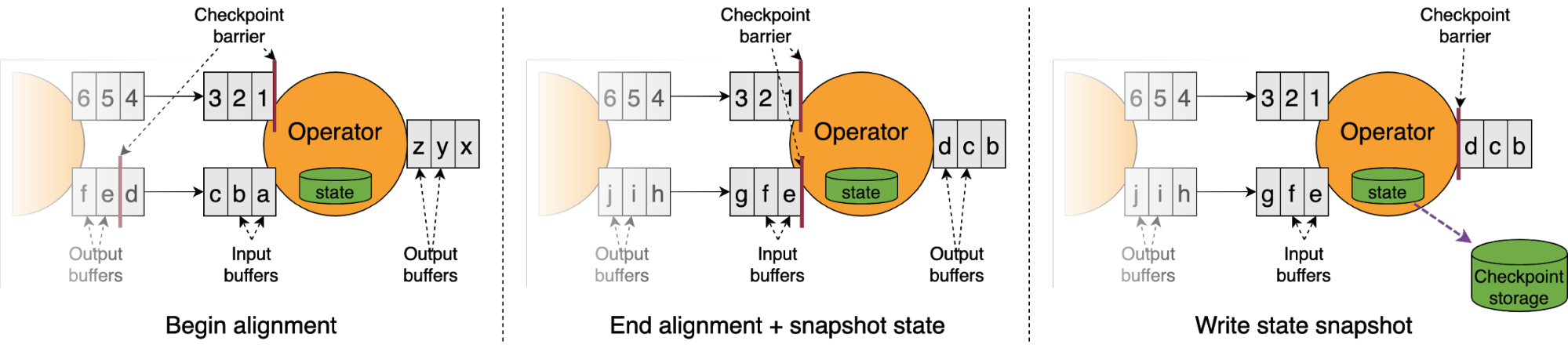
Operators need to make sure that they take the checkpoint exactly when all pre-checkpoint events are processed and no post-checkpoint events have yet been processed. When the first barrier reaches the head of the input buffer queue and is consumed by the operator, the operator starts the so-called alignment phase. During that phase, the operator will not consume any data from the channels where it already received a barrier, until it has received a barrier from all input channels.
Once all barriers are received, the operator snapshots its state, forwards the barrier to the output, and ends the alignment phase, which unblocks all inputs. An operator state snapshot is written into the checkpoint storage, typically asynchronously while data processing continues. Once all operators have successfully written their state snapshot to the checkpoint storage, the checkpoint is successfully completed and can be used for recovery.
One important thing to note here is that the barriers flow with the events, strictly in line. In a healthy setup without backpressure, barriers flow and align in milliseconds. The checkpoint duration is dominated by the time it takes to write the state snapshots to the checkpoint storage, which becomes faster with incremental checkpoints. If the events flow slowly under backpressure, so will the barriers. That means that barriers can take long to travel from sources to sinks resulting in the alignment phase to take even longer to complete.
Recovery #
When operators restart from a checkpoint (automatically during recovery or manually during deployment from a savepoint), the operators first restore their state from the checkpoint storage before resuming the event stream processing.
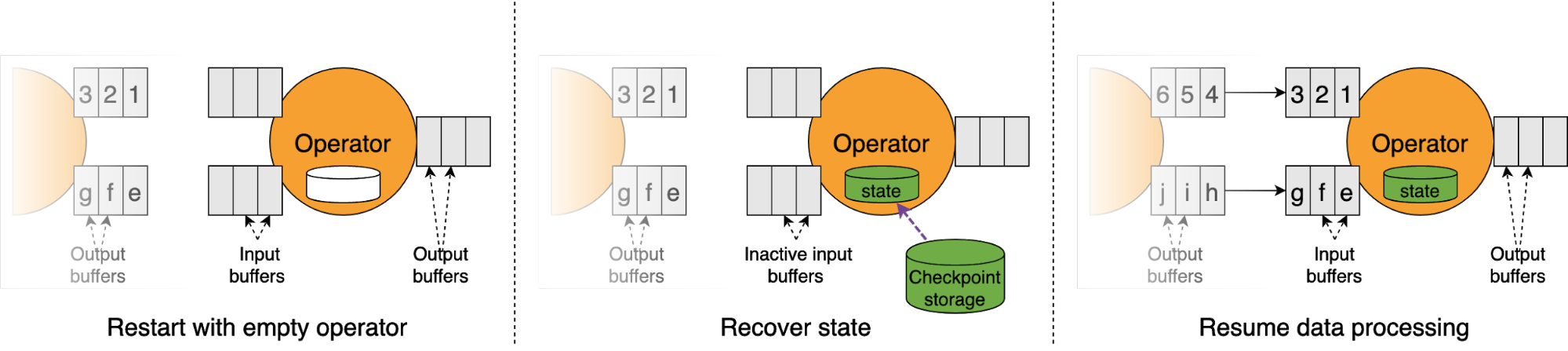
Since sources are bound to the offsets persisted in the checkpoint, recovery time is often calculated as the sum of the time of the recovery process — outlined in the previous figure — and any additional time needed to process any remaining data up to the point right before the system failure. When an application experiences backpressure, recovery time can also include the total time from the very start of the recovery process until backpressure is fully eliminated.
Consistency Guarantees #
The alignment phase is only necessary for checkpoints with exactly-once processing semantics, which is the default setting in Flink. If an application runs with at-least-once processing semantics, checkpoints will not block any channels with barriers during alignment, which has an additional cost from the duplication of the then-not-blocked events when recovering the operator.
This is not to be confused with having at-least-once semantics only in the sinks — something that many Flink users choose over transactional sinks — because many sink operations are idempotent or converge to the same result (like inputs/outputs to key/value stores). Having at-least-once semantics in an intermediate operator state is often not idempotent (for example a simple count aggregation) and hence using exactly-once checkpoints is advisable for the majority of Flink users.
Conclusion #
This blog post recaps how Flink’s fault tolerance mechanism (based on aligned checkpoints) works, and why checkpointing is a fitting mechanism for a fault-tolerant stream processor. The checkpointing mechanism has been optimized over time to make checkpoints faster and cheaper (with both asynchronous and incremental checkpoints) and faster-to-recover (local caching), but the basic concepts (barriers, alignment, operator state snapshots) are still the same as in the original version.
The next part will dig into a major break with the original mechanism that avoids the alignment phase — the recently-introduced “unaligned checkpoints”. Stay tuned for the second part, which explains how unaligned checkpoints work and how they guarantee consistent checkpointing times under backpressure.
Appendix 1 - On Backpressure #
Backpressure refers to the behavior where a slow receiver (e.g. of data/requests) makes the senders slow down in order to not overwhelm the receiver, something that can result in possibly dropping some of the processed data or requests. This is a crucial and very much desirable behavior for systems where completeness/correctness is important. Backpressure is implicitly implemented in many of the most basic building blocks of distributed communication, such as TCP Flow Control, bounded (blocking) I/O queues, poll-based consumers, etc.
Apache Flink implements backpressure across the entire data flow graph. A sink that (temporarily) cannot keep up with the data rate will result in the source connectors slowing down and pulling data out of the source systems more slowly. We believe that this is a good and desirable behavior, because backpressure is not only necessary in order to avoid overwhelming the memory of a receiver (thread), but can also prevent different stages of the streaming application from drifting apart too far.
Consider the example below:
- We have a source (let’s say reading data from Apache Kafka), parsing data, grouping and aggregating data by a key, and writing it to a sink system (some database).
- The application needs to re-group data by key between the parsing and the grouping/aggregation step.
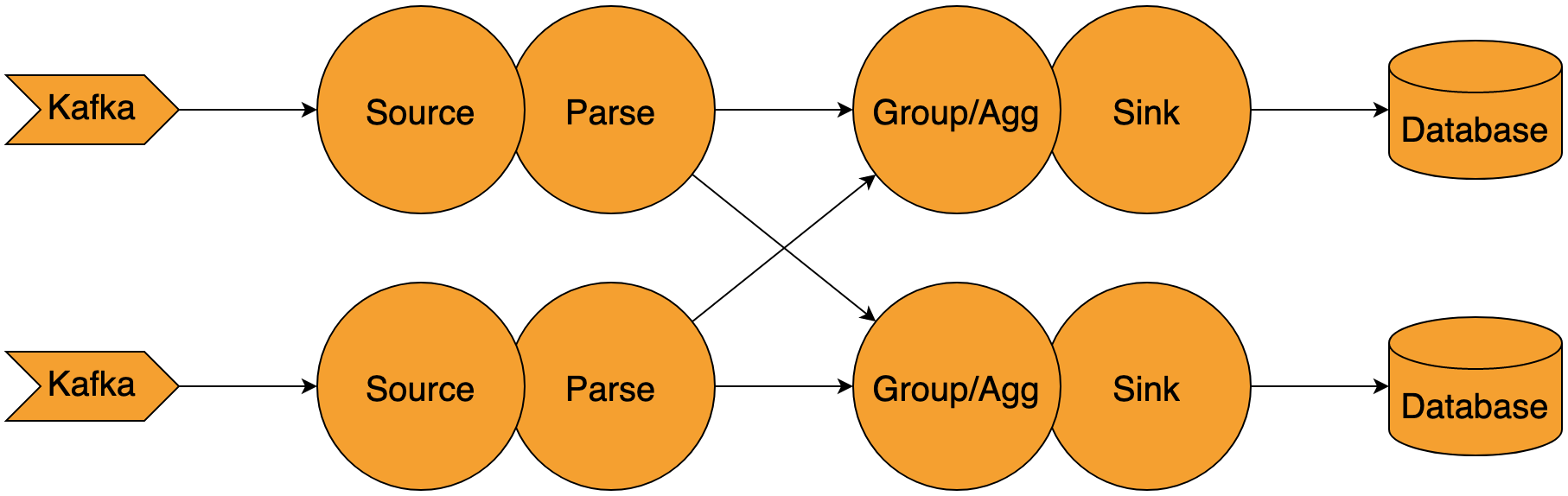
Let’s assume we use a non-backpressure approach, like writing the data to a log/MQ for the data re-grouping over the network (the approach used by Kafka Streams). If the sink is now slower than the remaining parts of the streaming application (which can easily happen), the first stage (source and parse) will still work as fast as possible to pull data out of the source, parse it, and put it into the log for the shuffle. That intermediate log will accumulate a lot of data, meaning it needs significant capacity, so that in a worst case scenario can hold a full copy of the input data or otherwise result in data loss (when the drift is greater than the retention time).
With backpressure, the source/parse stage slows down to match the speed of the sink, keeping both parts of the application closer together in their progress through the data, and avoiding the need to provision a lot of intermediate storage capacity.
We’d like to thank Marta Paes Moreira and Markos Sfikas for the wonderful review process.