What's New in the Pulsar Flink Connector 2.7.0
January 7, 2021 - Jianyun Zhao (@yihy8023) Jennifer Huang (@Jennife06125739)About the Pulsar Flink Connector #
In order for companies to access real-time data insights, they need unified batch and streaming capabilities. Apache Flink unifies batch and stream processing into one single computing engine with “streams” as the unified data representation. Although developers have done extensive work at the computing and API layers, very little work has been done at the data messaging and storage layers. In reality, data is segregated into data silos, created by various storage and messaging technologies. As a result, there is still no single source-of-truth and the overall operation for the developer teams poses significant challenges. To address such operational challenges, we need to store data in streams. Apache Pulsar (together with Apache BookKeeper) perfectly meets the criteria: data is stored as one copy (source-of-truth) and can be accessed in streams (via pub-sub interfaces) and segments (for batch processing). When Flink and Pulsar come together, the two open source technologies create a unified data architecture for real-time, data-driven businesses.
The Pulsar Flink connector provides elastic data processing with Apache Pulsar and Apache Flink, allowing Apache Flink to read/write data from/to Apache Pulsar. The Pulsar Flink Connector enables you to concentrate on your business logic without worrying about the storage details.
Challenges #
When we first developed the Pulsar Flink Connector, it received wide adoption from both the Flink and Pulsar communities. Leveraging the Pulsar Flink connector, Hewlett Packard Enterprise (HPE) built a real-time computing platform, BIGO built a real-time message processing system, and Zhihu is in the process of assessing the Connector’s fit for a real-time computing system.
With more users adopting the Pulsar Flink Connector, it became clear that one of the common issues was evolving around data formats and specifically performing serialization and deserialization. While the Pulsar Flink connector leverages the Pulsar serialization, the previous connector versions did not support the Flink data format. As a result, users had to manually configure their setup in order to use the connector for real-time computing scenarios.
To improve the user experience and make the Pulsar Flink connector easier-to-use, we built the capabilities to fully support the Flink data format, so users of the connector do not spend time on manual tuning and configuration.
What’s New in the Pulsar Flink Connector 2.7.0? #
The Pulsar Flink Connector 2.7.0 supports features in Apache Pulsar 2.7.0 and Apache Flink 1.12 and is fully compatible with the Flink connector and Flink message format. With the latest version, you can use important features in Flink, such as exactly-once sink, upsert Pulsar mechanism, Data Definition Language (DDL) computed columns, watermarks, and metadata. You can also leverage the Key-Shared subscription in Pulsar, and conduct serialization and deserialization without much configuration. Additionally, you can easily customize the configuration based on your business requirements.
Below, we provide more details about the key features in the Pulsar Flink Connector 2.7.0.
Ordered message queue with high-performance #
When users needed to strictly guarantee the ordering of messages, only one consumer was allowed to consume them. This had a severe impact on throughput. To address this, we designed a Key_Shared subscription model in Pulsar that guarantees the ordering of messages and improves throughput by adding a Key to each message and routes messages with the same Key Hash to one consumer.
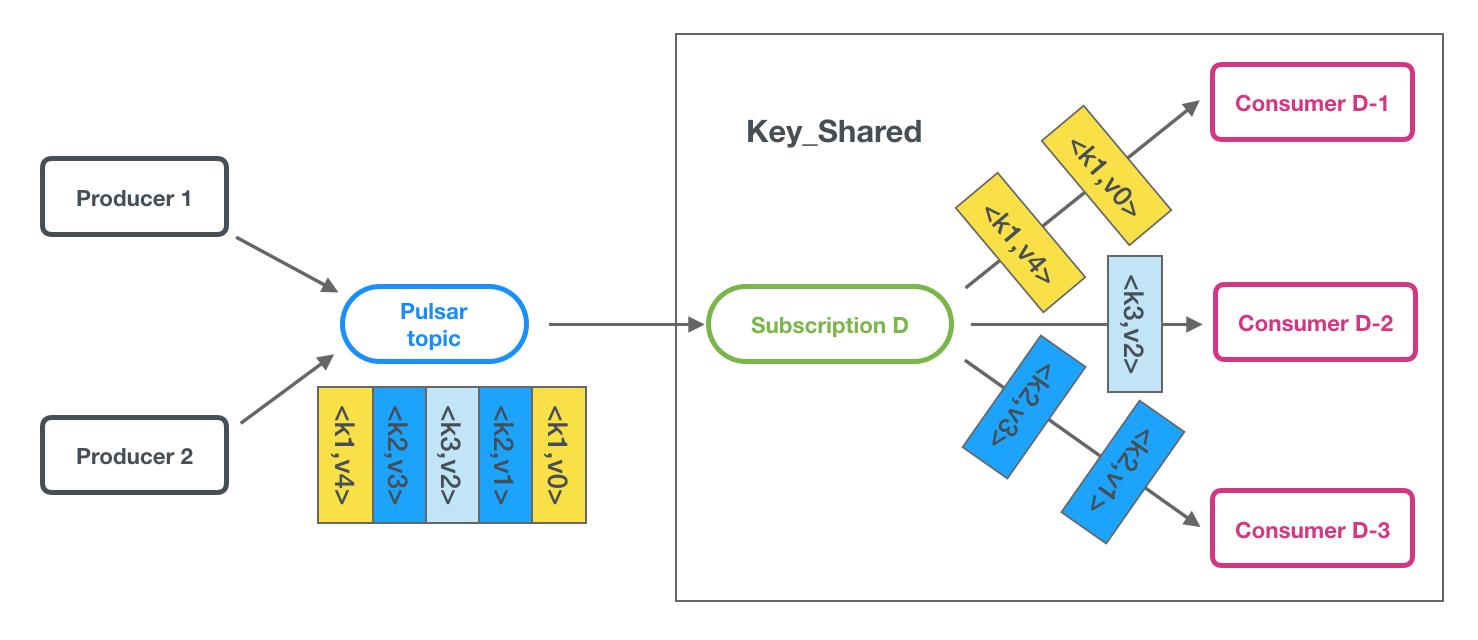
Pulsar Flink Connector 2.7.0 supports the Key_Shared subscription model. You can enable this feature by setting enable-key-hash-range to true. The Key Hash range processed by each consumer is decided by the parallelism of tasks.
Introducing exactly-once semantics for Pulsar sink (based on the Pulsar transaction) #
In previous versions, sink operators only supported at-least-once semantics, which could not fully meet requirements for end-to-end consistency. To deduplicate messages, users had to do some dirty work, which was not user-friendly.
Transactions are supported in Pulsar 2.7.0, which greatly improves the fault tolerance capability of the Flink sink. In the Pulsar Flink Connector 2.7.0, we designed exactly-once semantics for sink operators based on Pulsar transactions. Flink uses the two-phase commit protocol to implement TwoPhaseCommitSinkFunction. The main life cycle methods are beginTransaction(), preCommit(), commit(), abort(), recoverAndCommit(), recoverAndAbort().
You can flexibly select semantics when creating a sink operator while the internal logic changes are transparent. Pulsar transactions are similar to the two-phase commit protocol in Flink, which greatly improves the reliability of the Connector Sink.
It’s easy to implement beginTransaction and preCommit. You only need to start a Pulsar transaction and persist the TID of the transaction after the checkpoint. In the preCommit phase, you need to ensure that all messages are flushed to Pulsar, while any pre-committed messages will be committed eventually.
We focus on recoverAndCommit and recoverAndAbort in implementation. Limited by Kafka features, Kafka connector adopts hack styles for recoverAndCommit. Pulsar transactions do not rely on the specific Producer, so it’s easy for you to commit and abort transactions based on TID.
Pulsar transactions are highly efficient and flexible. Taking advantages of Pulsar and Flink, the Pulsar Flink connector is even more powerful. We will continue to improve transactional sink in the Pulsar Flink connector.
Introducing upsert-pulsar connector #
Users in the Flink community expressed their needs for the upsert Pulsar. After looking through mailing lists and issues, we’ve summarized the following three reasons.
- Interpret Pulsar topic as a changelog stream that interprets records with keys as upsert (aka insert/update) events.
- As a part of the real time pipeline, join multiple streams for enrichment and store results into a Pulsar topic for further calculation later. However, the result may contain update events.
- As a part of the real time pipeline, aggregate on data streams and store results into a Pulsar topic for further calculation later. However, the result may contain update events.
Based on the requirements, we add support for Upsert Pulsar. The upsert-pulsar connector allows for reading data from and writing data to Pulsar topics in the upsert fashion.
-
As a source, the upsert-pulsar connector produces a changelog stream, where each data record represents an update or delete event. More precisely, the value in a data record is interpreted as an UPDATE of the last value for the same key, if any (if a corresponding key does not exist yet, the update will be considered an INSERT). Using the table analogy, a data record in a changelog stream is interpreted as an UPSERT (aka INSERT/UPDATE) because any existing row with the same key is overwritten. Also, null values are interpreted in a special way: a record with a null value represents a “DELETE”.
-
As a sink, the upsert-pulsar connector can consume a changelog stream. It will write INSERT/UPDATE_AFTER data as normal Pulsar message values and write DELETE data as Pulsar message with null values (indicate tombstone for the key). Flink will guarantee the message ordering on the primary key by partitioning data on the values of the primary key columns, so the update/deletion messages on the same key will fall into the same partition.
Support new source interface and Table API introduced in FLIP-27 and FLIP-95 #
This feature unifies the source of the batch stream and optimizes the mechanism for task discovery and data reading. It is also the cornerstone of our implementation of Pulsar batch and streaming unification. The new Table API supports DDL computed columns, watermarks and metadata.
Support SQL read and write metadata as described in FLIP-107 #
FLIP-107 enables users to access connector metadata as a metadata column in table definitions. In real-time computing, users normally need additional information, such as eventTime, or customized fields. The Pulsar Flink connector supports SQL read and write metadata, so it is flexible and easy for users to manage metadata of Pulsar messages in the Pulsar Flink Connector 2.7.0. For details on the configuration, refer to Pulsar Message metadata manipulation.
Add Flink format type atomic to support Pulsar primitive types
#
In the Pulsar Flink Connector 2.7.0, we add Flink format type atomic to support Pulsar primitive types. When processing with Flink requires a Pulsar primitive type, you can use atomic as the connector format. You can find more information on Pulsar primitive types here.
Migration #
If you’re using the previous Pulsar Flink Connector version, you need to adjust your SQL and API parameters accordingly. Below we provide details on each.
SQL #
In SQL, we’ve changed the Pulsar configuration parameters in the DDL declaration. The name of some parameters are changed, but the values are not.
- Remove the
connector.prefix from the parameter names. - Change the name of the
connector.typeparameter intoconnector. - Change the startup mode parameter name from
connector.startup-modeintoscan.startup.mode. - Adjust Pulsar properties as
properties.pulsar.reader.readername=testReaderName.
If you use SQL in the Pulsar Flink Connector, you need to adjust your SQL configuration accordingly when migrating to Pulsar Flink Connector 2.7.0. The following sample shows the differences between previous versions and the 2.7.0 version for SQL.
SQL in previous versions:
create table topic1(
`rip` VARCHAR,
`rtime` VARCHAR,
`uid` bigint,
`client_ip` VARCHAR,
`day` as TO_DATE(rtime),
`hour` as date_format(rtime,'HH')
) with (
'connector.type' ='pulsar',
'connector.version' = '1',
'connector.topic' ='persistent://public/default/test_flink_sql',
'connector.service-url' ='pulsar://xxx',
'connector.admin-url' ='http://xxx',
'connector.startup-mode' ='earliest',
'connector.properties.0.key' ='pulsar.reader.readerName',
'connector.properties.0.value' ='testReaderName',
'format.type' ='json',
'update-mode' ='append'
);
SQL in Pulsar Flink Connector 2.7.0:
create table topic1(
`rip` VARCHAR,
`rtime` VARCHAR,
`uid` bigint,
`client_ip` VARCHAR,
`day` as TO_DATE(rtime),
`hour` as date_format(rtime,'HH')
) with (
'connector' ='pulsar',
'topic' ='persistent://public/default/test_flink_sql',
'service-url' ='pulsar://xxx',
'admin-url' ='http://xxx',
'scan.startup.mode' ='earliest',
'properties.pulsar.reader.readername' = 'testReaderName',
'format' ='json'
);
API #
From an API perspective, we adjusted some classes and enabled easier customization.
- To solve serialization issues, we changed the signature of the construction method
FlinkPulsarSink, and addedPulsarSerializationSchema. - We removed inappropriate classes related to row, such as
FlinkPulsarRowSink,FlinkPulsarRowSource. If you need to deal with Row formats, you can use Apache Flink’s Row related serialization components.
You can build PulsarSerializationSchema by using PulsarSerializationSchemaWrapper.Builder. TopicKeyExtractor is moved into PulsarSerializationSchemaWrapper. When you adjust your API, you can take the following sample as reference.
new PulsarSerializationSchemaWrapper.Builder<>(new SimpleStringSchema())
.setTopicExtractor(str -> getTopic(str))
.build();
Future Plan #
Future plans involve the design of a batch and stream solution integrated with Pulsar Source, based on the new Flink Source API (FLIP-27). The new solution will overcome the limitations of the current streaming source interface (SourceFunction) and simultaneously unify the source interfaces between the batch and streaming APIs.
Pulsar offers a hierarchical architecture where data is divided into streaming, batch, and cold data, which enables Pulsar to provide infinite capacity. This makes Pulsar an ideal solution for unified batch and streaming.
The batch and stream solution based on the new Flink Source API is divided into two simple parts: SplitEnumerator and Reader. SplitEnumerator discovers and assigns partitions, and Reader reads data from the partition.
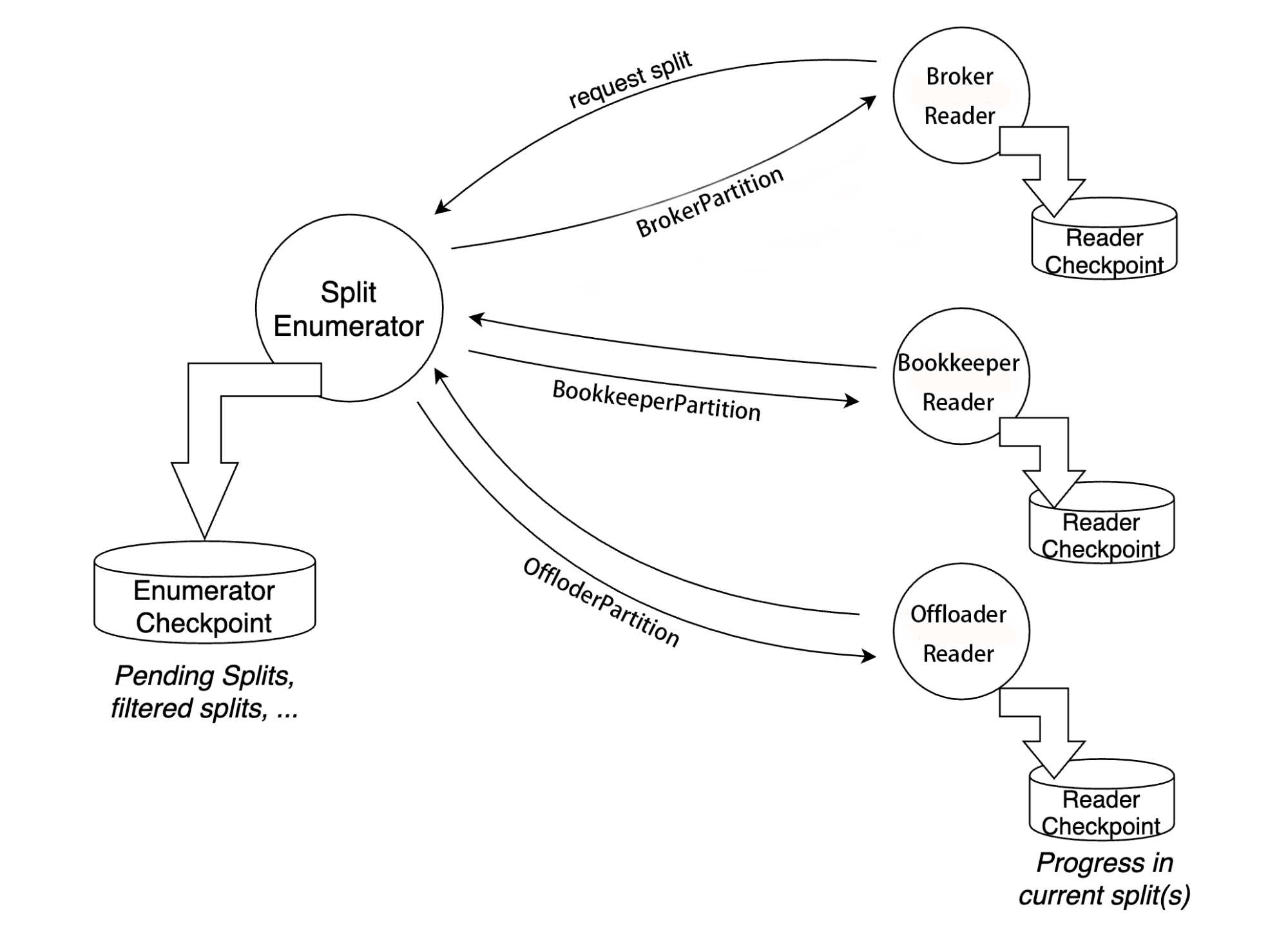
Apache Pulsar stores messages in the ledger block for users to locate the ledgers through Pulsar admin, and then provide broker partition, BookKeeper partition, Offloader partition, and other information through different partitioning policies. For more details, you can refer here.
Conclusion #
The latest version of the Pulsar Flink Connector is now available and we encourage everyone to use/upgrade to the Pulsar Flink Connector 2.7.0. The new version provides significant user enhancements, enabled by various features in Pulsar 2.7 and Flink 1.12. We will be contributing the Pulsar Flink Connector 2.7.0 to the Apache Flink repository soon. If you have any questions or concerns about the Pulsar Flink Connector, feel free to open issues in this repository.