Apache Flink 1.14.0 Release Announcement
September 29, 2021 - Stephan Ewen (@StephanEwen) Johannes Moser (@joemoeAT)The Apache Software Foundation recently released its annual report and Apache Flink once again made it on the list of the top 5 most active projects! This remarkable activity also shows in the new 1.14.0 release. Once again, more than 200 contributors worked on over 1,000 issues. We are proud of how this community is consistently moving the project forward.
This release brings many new features and improvements in areas such as the SQL API, more connector support, checkpointing, and PyFlink. A major area of changes in this release is the integrated streaming & batch experience. We believe that, in practice, unbounded stream processing goes hand-in-hand with bounded- and batch processing tasks, because many use cases require processing historic data from various sources alongside streaming data. Examples are data exploration when developing new applications, bootstrapping state for new applications, training models to be applied in a streaming application, or re-processing data after fixes/upgrades.
In Flink 1.14, we finally made it possible to mix bounded and unbounded streams in an application: Flink now supports taking checkpoints of applications that are partially running and partially finished (some operators reached the end of the bounded inputs). Additionally, bounded streams now take a final checkpoint when reaching their end to ensure smooth committing of results in sinks.
The batch execution mode now supports programs that use a mixture of the DataStream API and the SQL/Table API (previously only pure Table/SQL or DataStream programs).
The unified Source and Sink APIs have gotten an update, and we started consolidating the connector ecosystem around the unified APIs. We added a new hybrid source that can bridge between multiple storage systems. You can now do things like read old data from Amazon S3 and then switch over to Apache Kafka.
In addition, this release furthers our initiative in making Flink more self-tuning and easier to operate, without necessarily requiring a lot of Stream-Processor-specific knowledge. We started this initiative in the previous release with reactive scaling and are now adding automatic network memory tuning (a.k.a. Buffer Debloating). This feature speeds up checkpoints under high load while maintaining high throughput and without increasing checkpoint size. The mechanism continuously adjusts the network buffers to ensure the best throughput while having minimal in-flight data. See the Buffer Debloating section for more details.
There are many more improvements and new additions throughout various components, as we discuss below. We also had to say goodbye to some features that have been superceded by newer ones in recent releases, most prominently we are removing the old SQL execution engine and are removing the active integration with Apache Mesos.
We hope you like the new release and we’d be eager to learn about your experience with it, which yet unsolved problems it solves, what new use-cases it unlocks for you.
The Unified Batch and Stream Processing Experience #
One of Flink’s unique characteristics is how it integrates stream- and batch processing, using unified APIs and a runtime that supports multiple execution paradigms.
As motivated in the introduction, we believe that stream- and batch processing always go hand in hand. This quote from a report on Facebook’s streaming infrastructure echos this sentiment nicely.
Streaming versus batch processing is not an either/or decision. Originally, all data warehouse processing at Facebook was batch processing. We began developing Puma and Swift about five years ago. As we showed in Section […], using a mix of streaming and batch processing can speed up long pipelines by hours.
Having both the real-time and the historic computations in the same engine also ensures consistency between semantics and makes results well comparable. Here is an article by Alibaba about unifying business reporting with Apache Flink and getting consistent reports that way.
While unified streaming & batch are already possible in earlier versions, this release brings some features that unlock new use cases, as well as a series of quality-of-life improvements.
Checkpointing and Bounded Streams #
Flink’s checkpointing mechanism could originally only create checkpoints when all tasks in an application’s DAG were running. This meant that applications using both bounded and unbounded data sources were not really possible. In addition, applications on bounded inputs that were executed in a streaming way (not in a batch way) stopped checkpointing towards the end of the processing, when some tasks finished. Without checkpoints, the latest output data was not committed, resulting in lingering data for exactly-once sinks.
With FLIP-147 Flink now supports checkpoints after tasks are finished, and takes a final checkpoint at the end of a bounded stream, ensuring that all sink data is committed before the job ends (similar to how stop-with-savepoint behaves).
To activate this feature, add execution.checkpointing.checkpoints-after-tasks-finish.enabled: true
to your configuration. Keeping with the opt-in tradition for big and new features,
this is not activated by default in Flink 1.14. We expect it to become the default mode in the next release.
Background: While the batch execution mode is often the preferrable way to run applications over bounded streams, there are various reasons to use streaming execution mode over bounded streams. For example, the sink being used might only support streaming execution (i.e. Kafka sink) or you may want to exploit the streaming-inherent quasi-ordering-by-time in your application, such as motivated by the Kappa+ Architecture.
Batch Execution for mixed DataStream and Table/SQL Applications #
SQL and the Table API are becoming the default starting points for new projects. The declarative nature and richness of built-in types and operations make it easy to develop applications fast. It is not uncommon, however, for developers to eventually hit the limit of SQL’s expressiveness for certain types of event-driven business logic (or hit the point when it becomes grotesque to express that logic in SQL).
At that point, the natural step is to blend in a piece of stateful DataStream API logic, before switching back to SQL again.
In Flink 1.14, bounded batch-executed SQL/Table programs can convert their intermediate Tables to a DataStream, apply some DataSteam API operations, and convert it back to a Table. Under the hood, Flink builds a dataflow DAG mixing declarative optimized SQL execution with batch-executed DataStream logic. Check out the documentation for details.
Hybrid Source #
The new Hybrid Source produces a combined stream from multiple sources, by reading those sources one after the other, seamlessly switching over from one source to the other.
The motivating use case for the Hybrid Source was to read streams from tiered storage setups as if there was one stream that spans all tiers. For example, new data may land in Kafka and is eventually migrated to S3 (typically in compressed columnar format, for cost efficiency and performance). The Hybrid Source can read this as one contiguous logical stream, starting with the historic data on S3 and transitioning over to the more recent data in Kafka.
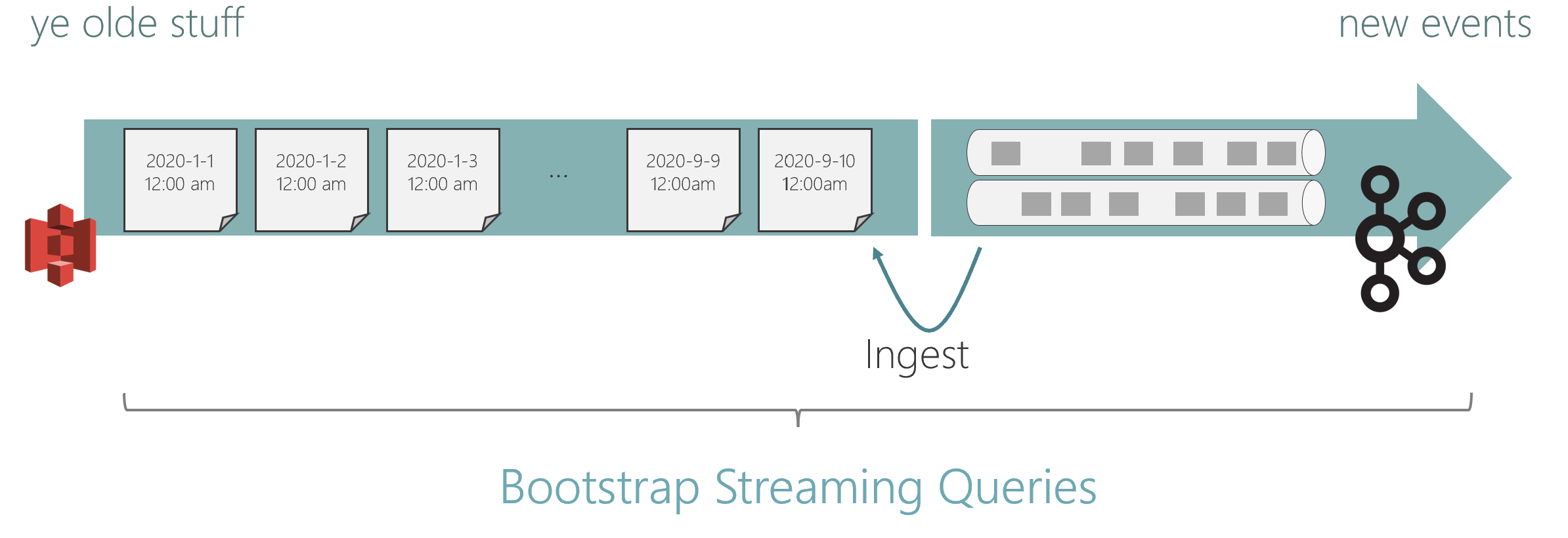
We believe that this is an exciting step in realizing the full promise of logs and the Kappa Architecture. Even if older parts of an event log are physically migrated to different storage (for reasons such as cost, better compression, faster reads) you can still treat and process it as one contiguous log.
Flink 1.14 adds the core functionality of the Hybrid Source. Over the next releases, we expect to add more utilities and patterns for typical switching strategies.
Consolidating Sources and Sink #
With the new unified (streaming/batch) source and sink APIs now being stable, we started the big effort to consolidate all connectors around those APIs. At the same time, we are better aligning connectors between DataStream and SQL/Table API. First are the Kafka and File Soures and Sinks for the DataStream API.
The result of this effort (that we expect to span at least 1-2 futher releases) will be a much smoother and more consistent experience for Flink users when connecting to external systems.
Improvements to Operations #
Buffer debloating #
Buffer Debloating is a new technology in Flink that minimizes checkpoint latency and cost. It does so by automatically tuning the usage of network memory to ensure high throughput, while minimizing the amount of in-flight data.
Apache Flink buffers a certain amount of data in its network stack to be able to utilize the bandwidth of fast networks. A Flink application running with high throughput uses some (or all) of that memory. Aligned checkpoints flow with the data through the network buffers in milliseconds.
During (temporary) backpressure from a resource bottleneck such as an external system, data skew, or (temporarily) increased load, Flink was buffering a lot more data inside its network buffers than necessary to utilize enough network bandwidth for the application’s current – backpressured – throughput. This actually has an adverse effect because more buffered data means that the checkpoints need to do more work. Aligned checkpoint barriers need to wait for more data to be processed, unaligned checkpoints need to persist more in-flight data.
This is where Buffer Debloating comes into play: It changes the network stack from keeping up to X bytes of data to keeping data that is worth X milliseconds of receiver computing time. With the default setting of 1000 milliseconds, that means the network stack will buffer as much data as the receiving task can process in 1000 milliseconds. These values are constantly measured and adjusted, so the system keeps this characteristic even under varying conditions. As a result, Flink can now provide stable and predictable alignment times for aligned checkpoints under backpressure, and can vastly reduce the amount of in-flight data stored in unaliged checkpoints under backpressure.

Buffer Debloating acts as a complementary feature, or even alternative, to unaligned checkpoints. Checkout the documentation to see how to activate this feature.
Fine-grained Resource Management #
Fine-grained resource management is an advanced new feature that increases the resource utilization of large shared clusters.
Flink clusters execute various data processing workloads. Different data processing steps typically need
different resources such as compute resources and memory. For example, most map() functions are fairly
lightweight, but large windows with long retention can benefit from lots of memory.
By default, Flink manages resources in coarse-grained units called slots, which are slices
of a TaskManager’s resources. Streaming pipelines fill a slot with one parallel
subtask of each operator, so each slot holds a pipeline of subtasks.
Through ‘slot sharing groups’, users can influence how subtasks are assigned to slots.
With fine-grained resource management, TaskManager slots can now be dynamically sized. Transformations and operators specify what resource profiles they would like (CPU size, memory pools, disk space) and Flink’s Resource Manager and TaskManagers slice off that specific part of a TaskManager’s total resources. You can think of it as a minimal lightweight resource orchestration layer within Flink. The figure below illustrates the difference between the current default mode of shared fixed-size slots and the new fine-grained resource management feature.

You may be wondering why we implement such a feature in Flink, when we also integrate with full-fledged resource orchestration frameworks like Kubernetes or YARN. There are several situations where the additional resource management layer within Flink significantly increases the resource utilization:
- For many small slots, the overhead of dedicated TaskManagers is very high (JVM overhead, Flink control data structures). Slot-sharing implicitly works around this by sharing the slots between all operator types, which means sharing resources between lightweight operators (which need small slots) and heavyweight operators (which need large slots). However, this only works well when all operators share the same parallelism, which is not aways optimal. Furthermore, certain operators work better when run in isolation (for example ML training operators that need dedicated GPU resources).
- Kubernetes and YARN often take quite some time to fulfill requests, especially on loaded clusters. For many batch jobs, efficiency gets lost while waiting for the requests to be fulfilled.
So when should you use this feature? For most streaming and batch jobs the default resource management mechanism are perfectly suitable. Fine-grained resourced management can help you increase resource efficiency if you have either long-running streaming jobs, or fast batch jobs, where different stages have different resource requirements, and you may have already tuned the parallelism of different operators to different values.
Alibaba’s internal Flink-based platform has used this mechanism for some time now and the resource utilization of the cluster has improved significantly.
Please refer to the Fine-grained Resource Management documentation for details on how to use this feature.
Connectors #
Connector Metrics #
Metrics for connectors have been standardized in this release (see FLIP-33). The community will gradually pull metrics through all connectors, as we rework them onto the new unified APIs over the next releases. In Flink 1.14, we cover the Kafka connector and (partially) the FileSystem connectors.
Connectors are the entry and exit points for data in a Flink job. If a job is not running as expected, the connector telemetry is among the first parts to be checked. We believe this will become a nice improvement when operating Flink applications in production.
Pulsar Connector #
In this release, Flink added the Apache Pulsar connector. The Pulsar connector reads data from Pulsar topics and supports both streaming and batch execution modes. With the support of the transaction functionality (introduced in Pulsar 2.8.0), the Pulsar connector provides exactly-once delivery semantic to ensure that a message is delivered exactly once to a consumer, even if a producer retries sending that message.
To support the different message-ordering and scaling requirements of different use cases, the Pulsar source connector exposes four subscription types:
The connector currently supports the DataStream API. Table API/SQL bindings are expected to be contributed in a future release. For details about how to use the Pulsar connector, see Apache Pulsar Connector.
PyFlink #
Performance Improvements through Chaining #
Similar to how the Java APIs chain transformation functions/operators within a task to avoid serialization overhead, PyFlink now chains Python functions. In PyFlink’s case, the chaining not only eliminates serialization overhead, but also reduces RPC round trips between the Java and Python processes. This provides a significant boost to PyFlink’s overall performance.
Python function chaining was already available for Python UDFs used in the Table API & SQL. In Flink 1.14, chaining is also exploited for the cPython functions in Python DataStream API.
Loopback Mode for Debugging #
Python functions are normally executed in a separate Python process next to Flink’s JVM. This architecture makes it difficult to debug Python code.
PyFlink 1.14 introduces a loopback mode, which is activated by default for local deployments. In this mode, user-defined Python functions will be executed in the Python process of the client, which is the entry point process that starts the PyFlink program and contains the DataStream API and Table API code that builds the dataflow DAG. Users can now easily debug their Python functions by setting breakpoints in their IDEs when launching a PyFlink job locally.
Miscellaneous Improvements #
There are also many other improvements to PyFlink, such as support for executing jobs in YARN application mode and support for compressed tgz files as Python archives. Check out the Python API documentation for more details.
Goodbye Legacy SQL Engine and Mesos Support #
Maintaining an open source project also means sometimes saying good-bye to some beloved features.
When we added the Blink SQL Engine to Flink more than two years ago, it was clear that it would eventually replace the previous SQL engine. Blink was faster and more feature-complete. For a year now, Blink has been the default SQL engine. With Flink 1.14 we finally remove all code from the previous SQL engine. This allowed us to drop many outdated interfaces and reduce confusion for users about which interfaces to use when implementing custom connectors or functions. It will also help us in the future to make faster changes to the SQL engine.
The active integration with Apache Mesos was also removed, because we saw little interest by users in this feature and we could not gather enough contributors willing to help maintaining this part of the system. Flink 1.14 can no longer run on Mesos without the help of projects like Marathon, and the Flink Resource Manager can no longer request and release resources from Mesos for workloads with changing resource requirements.
Upgrade Notes #
While we aim to make upgrades as smooth as possible, some of the changes require users to adjust some parts of the program when upgrading to Apache Flink 1.14. Please take a look at the release notes for a list of adjustments to make and issues to check during upgrades.
List of Contributors #
The Apache Flink community would like to thank each one of the contributors that have made this release possible:
adavis9592, Ada Wong, aidenma, Aitozi, Ankush Khanna, anton, Anton Kalashnikov, Arvid Heise, Ashwin Kolhatkar, Authuir, bgeng777, Brian Zhou, camile.sing, caoyingjie, Cemre Mengu, chennuo, Chesnay Schepler, chuixue, CodeCooker17, comsir, Daisy T, Danny Cranmer, David Anderson, David Moravek, Dawid Wysakowicz, dbgp2021, Dian Fu, Dong Lin, Edmondsky, Elphas Toringepi, Emre Kartoglu, ericliuk, Eron Wright, est08zw, Etienne Chauchot, Fabian Paul, fangliang, fangyue1, fengli, Francesco Guardiani, FuyaoLi2017, fuyli, Gabor Somogyi, gaoyajun02, Gen Luo, gentlewangyu, GitHub, godfrey he, godfreyhe, gongzhongqiang, Guokuai Huang, GuoWei Ma, Gyula Fora, hackergin, hameizi, Hang Ruan, Han Wei, hapihu, hehuiyuan, hstdream, Huachao Mao, HuangXiao, huangxingbo, huxixiang, Ingo Bürk, Jacklee, Jan Brusch, Jane, Jane Chan, Jark Wu, JasonLee, Jiajie Zhong, Jiangjie (Becket) Qin, Jianzhang Chen, Jiayi Liao, Jing, Jingsong Lee, JingsongLi, Jing Zhang, jinxing64, junfan.zhang, Jun Qin, Jun Zhang, kanata163, Kevin Bohinski, kevin.cyj, Kevin Fan, Kurt Young, kylewang, Lars Bachmann, lbb, LB Yu, LB-Yu, LeeJiangchuan, Leeviiii, leiyanfei, Leonard Xu, LightGHLi, Lijie Wang, liliwei, lincoln lee, Linyu, liuyanpunk, lixiaobao14, luoyuxia, Lyn Zhang, lys0716, MaChengLong, mans2singh, Marios Trivyzas, martijnvisser, Matthias Pohl, Mayi, mayue.fight, Michael Li, Michal Ciesielczyk, Mika, Mika Naylor, MikuSugar, movesan, Mulan, Nico Kruber, Nicolas Raga, Nicolaus Weidner, paul8263, Paul Lin, pierre xiong, Piotr Nowojski, Qingsheng Ren, Rainie Li, Robert Metzger, Roc Marshal, Roman, Roman Khachatryan, Rui Li, sammieliu, sasukerui, Senbin Lin, Senhong Liu, Serhat Soydan, Seth Wiesman, sharkdtu, Shengkai, Shen Zhu, shizhengchao, Shuo Cheng, shuo.cs, simenliuxing, sjwiesman, Srinivasulu Punuru, Stefan Gloutnikov, SteNicholas, Stephan Ewen, sujun, sv3ndk, Svend Vanderveken, syhily, Tartarus0zm, Terry Wang, Thesharing, Thomas Weise, tiegen, Till Rohrmann, Timo Walther, tison, Tony Wei, trushev, tsreaper, TsReaper, Tzu-Li (Gordon) Tai, wangfeifan, wangwei1025, wangxianghu, wangyang0918, weizheng92, Wenhao Ji, Wenlong Lyu, wenqiao, WilliamSong11, wuren, wysstartgo, Xintong Song, yanchenyun, yangminghua, yangqu, Yang Wang, Yangyang ZHANG, Yangze Guo, Yao Zhang, yfhanfei, yiksanchan, Yik San Chan, Yi Tang, yljee, Youngwoo Kim, Yuan Mei, Yubin Li, Yufan Sheng, yulei0824, Yun Gao, Yun Tang, yuxia Luo, Zakelly, zhang chaoming, zhangjunfan, zhangmang, zhangzhengqi3, zhao_wei_nan, zhaown, zhaoxing, ZhiJie Yang, Zhilong Hong, Zhiwen Sun, Zhu Zhu, zlzhang0122, zoran, Zor X. LIU, zoucao, Zsombor Chikan, 子扬, 莫辞