Sort-Based Blocking Shuffle Implementation in Flink - Part Two
October 26, 2021 - Yingjie Cao (Kevin) Daisy TsangPart one of this blog post explained the motivation behind introducing sort-based blocking shuffle, presented benchmark results, and provided guidelines on how to use this new feature.
Like sort-merge shuffle implemented by other distributed data processing frameworks, the whole sort-based shuffle process in Flink consists of several important stages, including collecting data in memory, sorting the collected data in memory, spilling the sorted data to files, and reading the shuffle data from these spilled files. However, Flink’s implementation has some core differences, including the multiple data region file structure, the removal of file merge, and IO scheduling.
In part two of this blog post, we will give you insight into some core design considerations and implementation details of the sort-based blocking shuffle in Flink and list several ideas for future improvement.
Design considerations #
There are several core objectives we want to achieve for the new sort-based blocking shuffle to be implemented Flink:
Produce fewer (small) files #
As discussed above, the hash-based blocking shuffle would produce too many small files for large-scale batch jobs. Producing fewer files can help to improve both stability and performance. The sort-merge approach has been widely adopted to solve this problem. By first writing to the in-memory buffer and then sorting and spilling the data into a file after the in-memory buffer is full, the number of output files can be reduced, which becomes (total data size) / (in-memory buffer size). Then by merging the produced files together, the number of files can be further reduced and larger data blocks can provide better sequential reads.
Flink’s sort-based blocking shuffle adopts a similar logic. A core difference is that data spilling will always append data to the same file so only one file will be spilled for each output, which means fewer files are produced.
Open fewer files concurrently #
The hash-based implementation will open all partition files when writing and reading data which will consume resources like file descriptors and native memory. Exhaustion of file descriptors will lead to stability issues like “too many open files”.
By always writing/reading only one file per data result partition and sharing the same opened file channel among all the concurrent data reads from the downstream consumer tasks, Flink’s sort-based blocking shuffle implementation can greatly reduce the number of concurrently opened files.
Create more sequential disk IO #
Although the hash-based implementation writes and reads each output file sequentially, the large amount of writing and reading can cause random IO because of the large number of files being processed concurrently, which means that reducing the number of files can also achieve more sequential IO.
In addition to producing larger files, there are some other optimizations implemented by Flink. In the data writing phase, by merging small output data together into larger batches and writing through the writev system call, more writing sequential IO can be achieved. In the data reading phase, more sequential data reading IO is achieved by IO scheduling. In short, Flink tries to always read data in file offset order which maximizes sequential reads. Please refer to the IO scheduling section for more information.
Have less disk IO amplification #
The sort-merge approach can reduce the number of files and produce larger data blocks by merging the spilled data files together. One down side of this approach is that it writes and reads the same data multiple times because of the data merging and, theoretically, it may also take up more storage space than the total size of shuffle data.
Flink’s implementation eliminates the data merging phase by spilling all data of one data result partition together into one file. As a result, the total amount of disk IO can be reduced, as well as the storage space. Though without the data merging, the data blocks are not merged into larger ones. With the IO scheduling technique, Flink can still achieve good sequential reading and high disk IO throughput. The benchmark results from the first part shows that.
Decouple memory consumption from parallelism #
Similar to the sort-merge implementation in other distributed data processing systems, Flink’s implementation uses a piece of fixed size (configurable) in-memory buffer for data sorting and the buffer does not necessarily need to be extended after the task parallelism is changed, though increasing the size may lead to better performance for large-scale batch jobs.
Note: This only decouples the memory consumption from the parallelism at the data producer side. On the data consumer side, there is an improvement which works for both streaming and batch jobs (see FLINK-16428).
Implementation details #
Here are several core components and algorithms implemented in Flink’s sort-based blocking shuffle:
In-memory sort #
In the sort-spill phase, data records are serialized to the in-memory sort buffer first. When the sort buffer is full or all output has been finished, the data in the sort buffer will be copied and spilled into the target data file in the specific order. The following is the sort buffer interface in Flink:
public interface SortBuffer {
/** Appends data of the specified channel to this SortBuffer. */
boolean append(ByteBuffer source, int targetChannel, Buffer.DataType dataType) throws IOException;
/** Copies data in this SortBuffer to the target MemorySegment. */
BufferWithChannel copyIntoSegment(MemorySegment target);
long numRecords();
long numBytes();
boolean hasRemaining();
void finish();
boolean isFinished();
void release();
boolean isReleased();
}
Currently, Flink does not need to sort records by key on the data producer side, so the default implementation of sort buffer only sorts data by subpartition index, which is achieved by binary bucket sort. More specifically, each data record will be serialized and attached a 16 bytes binary header. Among the 16 bytes, 4 bytes is for the record length, 4 bytes is for the data type (event or data buffer) and 8 bytes is for pointers to the next records belonging to the same subpartition to be consumed by the same downstream data consumer. When reading data from the sort buffer, all records of the same subpartition will be copied one by one following the pointer in the record header, which guarantees that for each subpartition, the order of record reading/spilling is the same order as when the record is emitted by the producer task. The following picture shows the internal structure of the in-memory binary sort buffer:

Storage structure #
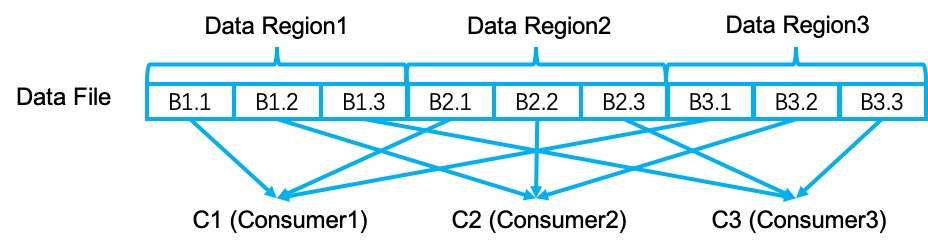
The data of each blocking result partition is stored as a physical data file on the disk. The data file consists of multiple data regions, one data spilling produces one data region. In each data region, the data is clustered by the subpartition ID (index) and each subpartition is corresponding to one data consumer.
The following picture shows the structure of a simple data file. This data file has three data regions (R1, R2, R3) and three consumers (C1, C2, C3). Data blocks B1.1, B2.1 and B3.1 will be consumed by C1, data blocks B1.2, B2.2 and B3.2 will be consumed by C2, and data blocks B1.3, B2.3 and B3.3 will be consumed by C3.
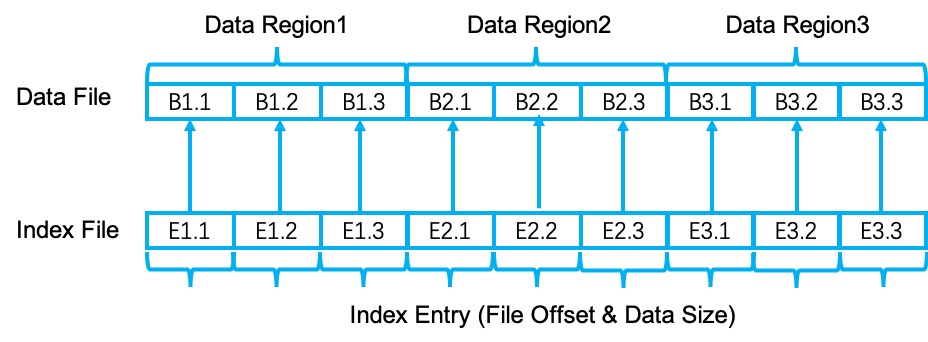
In addition to the data file, for each result partition, there is also an index file which contains pointers to the data file. The index file has the same number of regions as the data file. In each region, there are n (equals to the number of subpartitions) index entries. Each index entry consists of two parts: one is the file offset of the target data in the data file, the other is the data size. To reduce the disk IO caused by index data file access, Flink caches the index data using unmanaged heap memory if the index data file size is less than 4M. The following picture illustrates the relationship between index file and data file:
IO scheduling #
Based on the storage structure described above, we introduced the IO scheduling technique to achieve more sequential reads for the sort-based blocking shuffle in Flink. The core idea behind IO scheduling is pretty simple. Just like the elevator algorithm for disk scheduling, the IO scheduling for sort-based blocking shuffle always tries to serve data read requests in the file offset order. More formally, we have n data regions indexed from 0 to n-1 in a result partition file. In each data region, there are m data subpartitions to be consumed by m downstream data consumers. These data consumers read data concurrently.
// let data_regions as the data region list indexed from 0 to n - 1
// let data_readers as the concurrent downstream data readers queue indexed from 0 to m - 1
for (data_region in data_regions) {
data_reader = poll_reader_of_the_smallest_file_offset(data_readers);
if (data_reader == null)
break;
reading_buffers = request_reading_buffers();
if (reading_buffers.isEmpty())
break;
read_data(data_region, data_reader, reading_buffers);
}
Broadcast optimization #
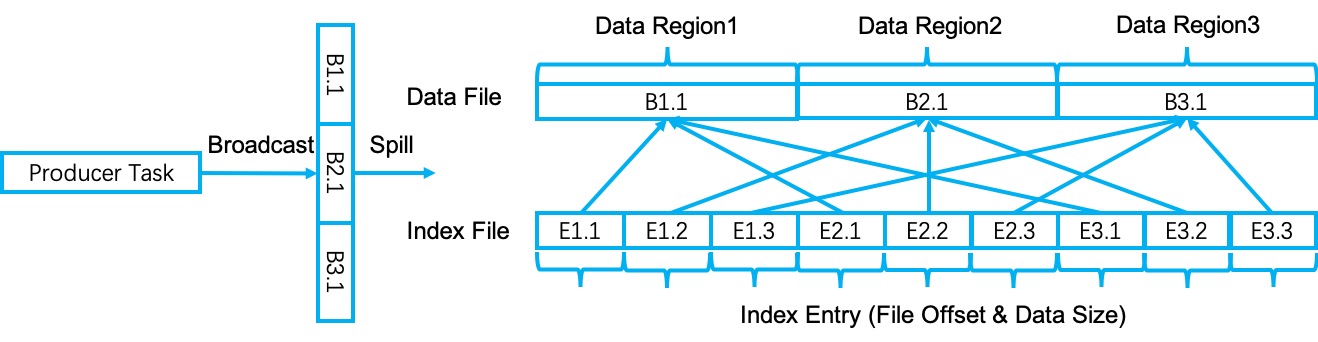
Shuffle data broadcast in Flink refers to sending the same collection of data to all the downstream data consumers. Instead of copying and writing the same data multiple times, Flink optimizes this process by copying and spilling the broadcast data only once, which improves the data broadcast performance.
More specifically, when broadcasting a data record to the sort buffer, the record will be copied and stored once. A similar thing happens when spilling the broadcast data into files. For index data, the only difference is that all the index entries for different downstream consumers point to the same data in the data file.
Data compression #
Data compression is a simple but really useful technique to improve blocking shuffle performance. Similar to the data compression implementation of the hash-based blocking shuffle, data is compressed per buffer after it is copied from the in-memory sort buffer and before it is spilled to disk. If the data size becomes even larger after compression, the original uncompressed data buffer will be kept. Then the corresponding downstream data consumers are responsible for decompressing the received shuffle data when processing it. In fact, the sort-based blocking shuffle reuses those building blocks implemented for the hash-based blocking shuffle directly. The following picture illustrates the shuffle data compression process:

Future improvements #
-
TCP Connection Reuse: This improvement is also useful for streaming applications which can improve the network stability. There are already tickets opened for it: FLINK-22643 and FLINK-15455.
-
Multi-Disks Load Balance: Multi-Disks Load Balance: In production environments, there are usually multiple disks per node, better load balance can lead to better performance, the relevant issues are FLINK-21790 and FLINK-21789.
-
External/Remote Shuffle Service: Implementing an external/remote shuffle service can further improve the shuffle io performance because as a centralized service, it can collect more information leading to more optimized decisions. For example, further merging of data to the same downstream task, better node-level load balance, handling of stragglers, shared resources and so on. There are several relevant issues: FLINK-13247, FLINK-22672, FLINK-19551 and FLINK-10653.
-
Enable the Choice of SSD/HDD: In production environments, there are usually both SSD and HDD storage. Some jobs may prefer SSD for the faster speed, some jobs may prefer HDD for larger space and cheaper price. Enabling the choice of SSD/HDD can improve the usability of Flink’s blocking shuffle.