Improving speed and stability of checkpointing with generic log-based incremental checkpoints
May 30, 2022 - Roman Khachatryan Yuan MeiIntroduction #
One of the most important characteristics of stream processing systems is end-to-end latency, i.e. the time it takes for the results of processing an input record to reach the outputs. In the case of Flink, end-to-end latency mostly depends on the checkpointing mechanism, because processing results should only become visible after the state of the stream is persisted to non-volatile storage (this is assuming exactly-once mode; in other modes, results can be published immediately).
Furthermore, сheckpoint duration also defines the reasonable interval with which checkpoints are made. A shorter interval provides the following advantages:
- Lower latency for transactional sinks: Transactional sinks commit on checkpoints, so faster checkpoints mean more frequent commits.
- More predictable checkpoint intervals: Currently, the duration of a checkpoint depends on the size of the artifacts that need to be persisted in the checkpoint storage.
- Less work on recovery. The more frequently the checkpoint, the fewer events need to be re-processed after recovery.
Following are the main factors affecting checkpoint duration in Flink:
- Barrier travel time and alignment duration
- Time to take state snapshot and persist it onto the durable highly-available storage (such as S3)
Recent improvements such as Unaligned checkpoints and Buffer debloating try to address (1), especially in the presence of back-pressure. Previously, Incremental checkpoints were introduced to reduce the size of a snapshot, thereby reducing the time required to store it (2).
However, there are still some cases when this duration is high
Every checkpoint is delayed by at least one task with high parallelism #
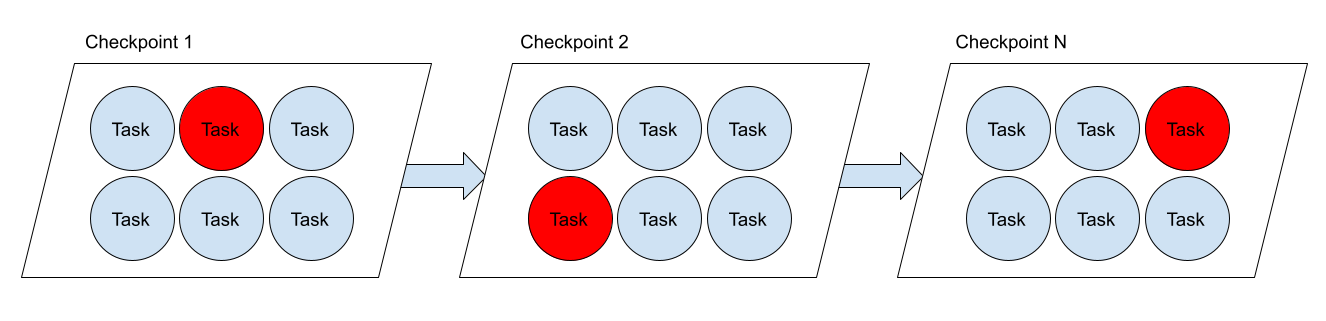
With the existing incremental checkpoint implementation of the RocksDB state backend, every subtask needs to periodically perform some form of compaction. That compaction results in new, relatively big files, which in turn increase the upload time (2). The probability of at least one node performing such compaction and thus slowing down the whole checkpoint grows proportionally to the number of nodes. In large deployments, almost every checkpoint becomes delayed by some node.
Unnecessary delay before uploading state snapshot #

State backends don’t start any snapshotting work until the task receives at least one checkpoint barrier, increasing the effective checkpoint duration. This is suboptimal if the upload time is comparable to the checkpoint interval; instead, a snapshot could be uploaded continuously throughout the interval.
This work discusses the mechanism introduced in Flink 1.15 to address the above cases by continuously persisting state changes on non-volatile storage while performing materialization in the background. The basic idea is described in the following section, and then important implementation details are highlighted. Subsequent sections discuss benchmarking results, limitations, and future work.
High-level Overview #
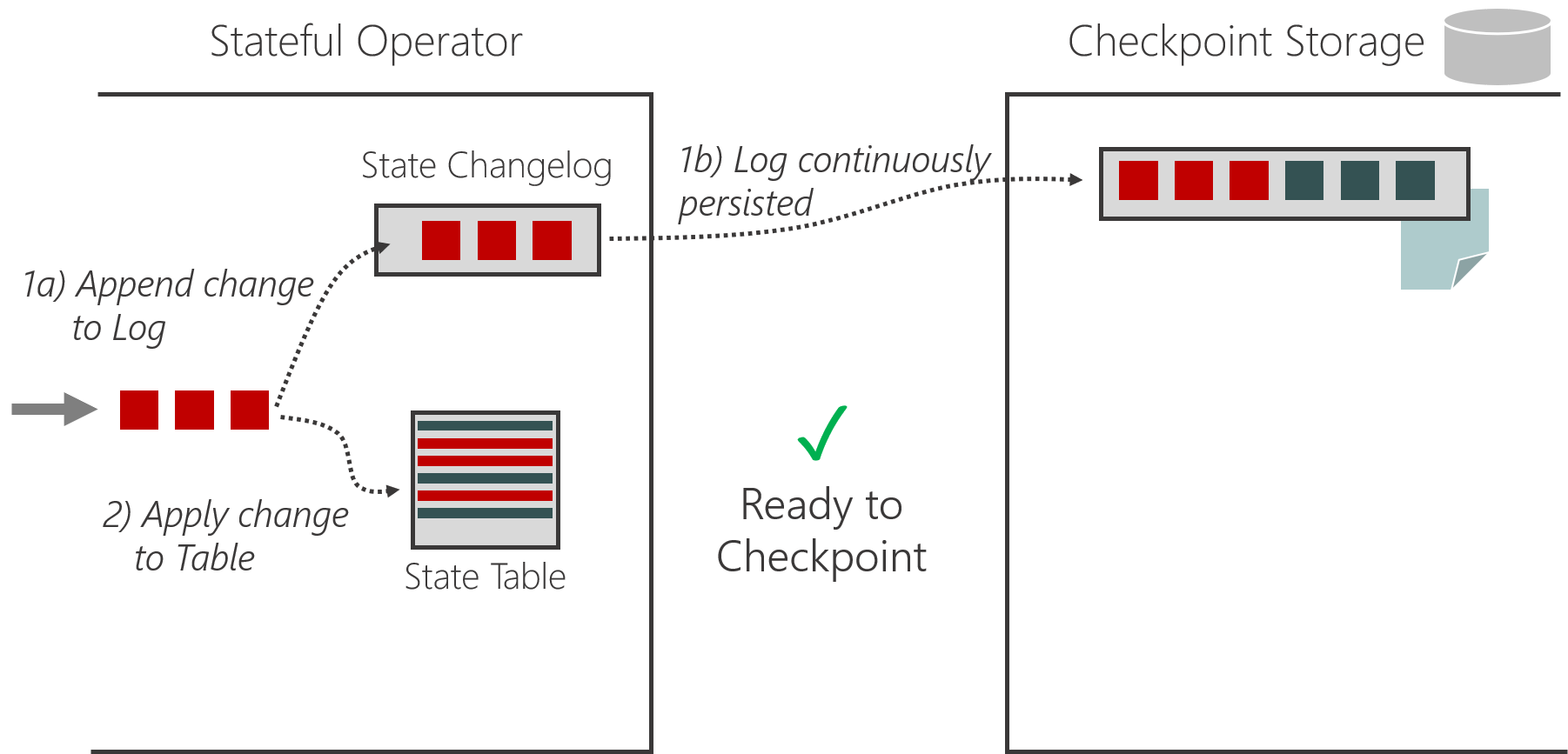
The core idea is to introduce a state changelog (a log that records state changes); this changelog allows operators to persist state changes in a very fine-grained manner, as described below:
- Stateful operators write the state changes to the state changelog, in addition to applying them to the state tables in RocksDB or the in-mem Hashtable.
- An operator can acknowledge a checkpoint as soon as the changes in the log have reached the durable checkpoint storage.
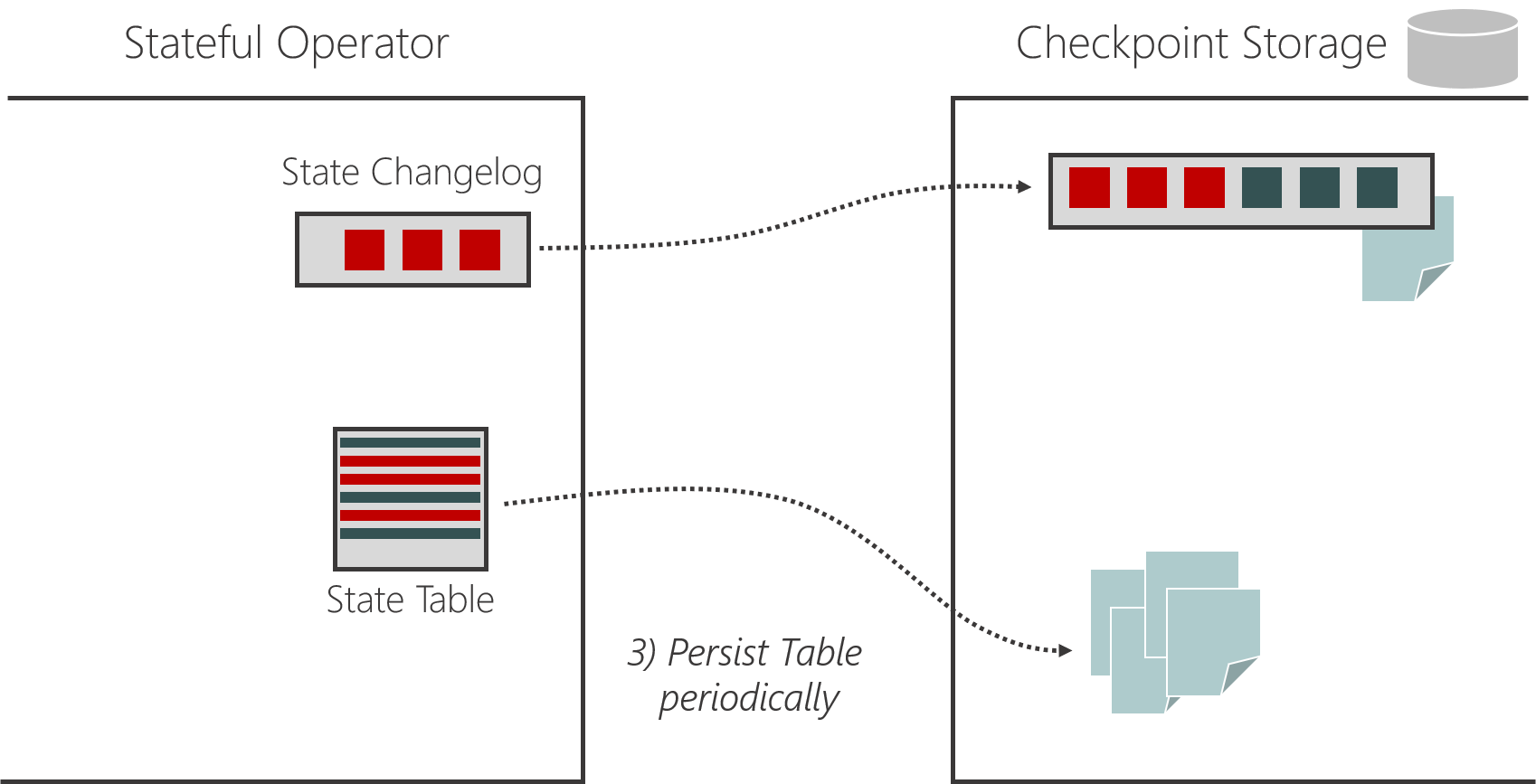
- The state tables are persisted periodically as well, independent of the checkpoints. We call this procedure the materialization of the state on the durable checkpoint storage.
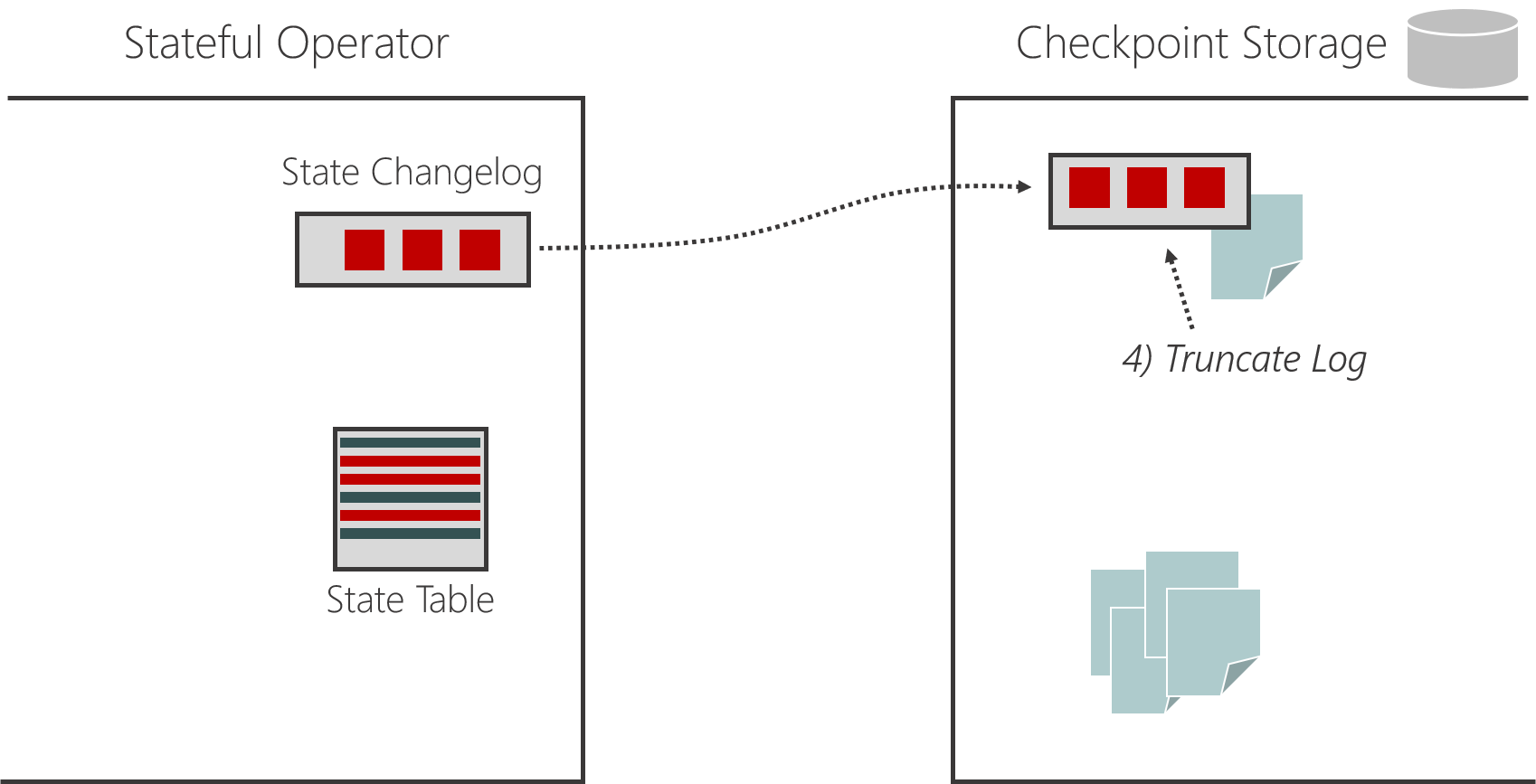
- Once the state is materialized on the checkpoint storage, the state changelog can be truncated to the point where the state is materialized.
This can be illustrated as follows:
<br/>
This approach mirrors what database systems do, adjusted to distributed checkpoints:
- Changes (inserts/updates/deletes) are written to the transaction log, and the transaction is considered durable once the log is synced to disk (or other durable storage).
- The changes are also materialized in the tables (so the database system can efficiently query the table). The tables are usually persisted asynchronously.
Once all relevant parts of the changed tables have been persisted, the transaction log can be truncated, which is similar to the materialization procedure in our approach.
Such a design makes a number of trade-offs:
- Increased use of network IO and remote storage space for changelog
- Increased memory usage to buffer state changes
- Increased time to replay state changes during the recovery process
The last one, may or may not be compensated by more frequent checkpoints. More frequent checkpoints mean less re-processing is needed after recovery.
System architecture #
Changelog storage (DSTL) #
The component that is responsible for actually storing state changes has the following requirements.
Durability #
Changelog constitutes a part of a checkpoint, and therefore the same durability guarantees as for checkpoints must be provided. However, the duration for which the changelog is stored is expected to be short (until the changes are materialized).
Workload #
The workload is write-heavy: changelog is written continuously, and it is only read in case of failure. Once written, data can not be modified.
Latency #
We target checkpoint duration of 1s in the Flink 1.15 MVP for 99% of checkpoints. Therefore, an individual write request must complete within that duration or less (if parallelism is 100, then 99.99% of write requests must complete within 1s).
Consistency #
Once a change is persisted (and acknowledged to JM), it must be available for replay to enable recovery (this can be achieved by using a single machine, quorum, or synchronous replication).
Concurrency #
Each task writes to its own changelog, which prevents concurrency issues across multiple tasks. However, when a task is restarted, it needs to write to the same log, which may cause concurrency issues. This is addressed by:
- Using unique log segment identifiers while writing
- Fencing previous execution attempts on JM when handling checkpoint acknowledgments
- After closing the log, treating it as Flink state, which is read-only and is discarded by a single JM (leader)
To emphasize the difference in durability requirements and usage compared to other systems (durable, short-lived, append-only), the component is called “Durable Short-term Log” (DSTL).
DSTL can be implemented in many ways, such as Distributed Log, Distributed File System* (DFS), or even a database. In the MVP version in Flink 1.15, we chose DFS because of the following reasons:
- No additional external dependency; DFS is readily available in most environments and is already used to store checkpoints
- No additional stateful components to manage; using any other persistence medium would incur additional operational overhead
- DFS natively provides durability and consistency guarantees which need to be taken care of when implementing a new customized distributed log storage (in particular, when implementing replication)
On the other hand, the DFS approach has the following disadvantages:
- has higher latency than for example Distributed Log writing to the local disks
- its scalability is limited by DFS (most Storage Providers start rate-limiting at some point)
However, after some initial experimentation, we think the performance of popular DFS could satisfy 80% of the use cases, and more results will be illustrated with the MVP version in a later section. DFS here makes no distinction between DFS and object stores.
Using RocksDB as an example, this approach can be illustrated at the high level as follows. State updates are replicated to both RocksDB and DSTL by the Changelog State Backend. DSTL continuously writes state changes to DFS and flushes them periodically and on checkpoint. That way, checkpoint time only depends on the time to flush a small amount of data. RocksDB on the other hand is still used for querying the state. Furthermore, its SSTables are periodically uploaded to DFS, which is called “materialization”. That upload is independent of and is much less frequent than checkpointing procedure, with 10 minutes as the default interval.
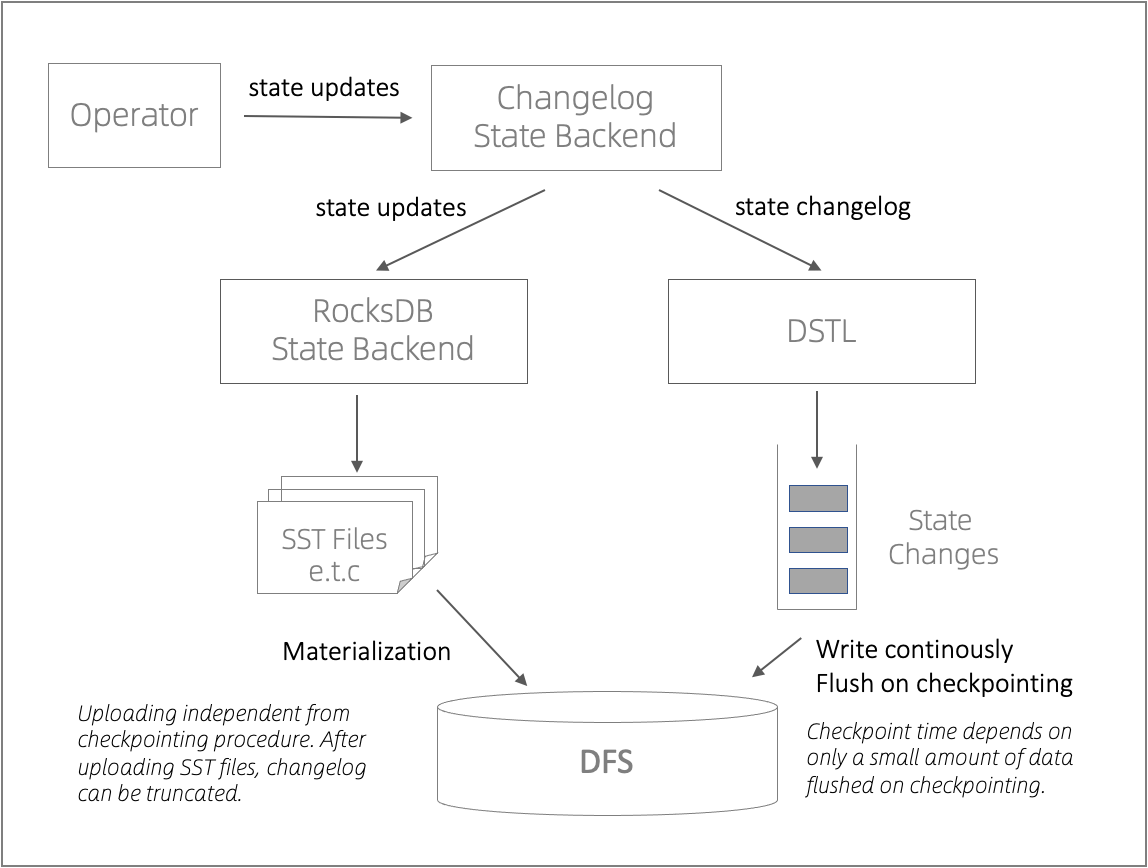
There are a few more issues worth highlighting here:
State cleanup #
State changelog needs to be truncated once the corresponding changes are materialized. It becomes more complicated with re-scaling and sharing the underlying files across multiple operators. However, Flink already provides a mechanism called SharedStateRegistry similar to file system reference counting. Log fragments can be viewed as shared state objects, and therefore can be tracked by this SharedStateRegistry (please see this article for more information on how SharedStateRegistry was used previously).
DFS-specific issues #
Small files problem #
One issue with using DFS is that much more and likely smaller files are created for each checkpoint. And with the increased checkpoint frequency, there are more checkpoints. To mitigate this, state changes related to the same job on a TM are grouped into a single file.
High tail latency #
DFS are known for high tail latencies, although this has been improving in recent years. To address the high-tail-latency problem, write requests are retried when they fail to complete within a timeout, which is 1 second by default (but can be configured manually).
Benchmark results #
The improvement of checkpoint stability and speed after enabling Changelog highly depends on the factors below:
- The difference between the changelog diff size and the full state size (or incremental state size, if comparing changelog to incremental checkpoints).
- The ability to upload the updates continuously during the checkpoint (e.g. an operator might maintain state in memory and only update Flink state objects on checkpoint - in this case, changelog wouldn’t help much).
- The ability to group updates from multiple tasks (multiple tasks must be deployed on a single TM). Grouping the updates leads to fewer files being created thereby reducing the load on DFS, which improves the stability.
- The ability of the underlying backend to accumulate updates to the same key before flushing (This makes state change log potentially contain more updates compared to just the final value, leading to a larger incremental changelog state size)
- The speed of the underlying durable storage (the faster it is, the less significant the improvement)
The following setup was used in the experiment:
- Parallelism: 50
- Running time: 21h
- State backend: RocksDB (incremental checkpoint enabled)
- Storage: S3 (Presto plugin)
- Machine type: AWS m5.xlarge (4 slots per TM)
- Checkpoint interval: 10ms
- State Table materialization interval: 3m
- Input rate: 50K events per second
ValueState workload #
A workload updating mostly the new keys each time would benefit the most.
| Changelog Disabled | Changelog Enabled | |
|---|---|---|
| Records processed | 3,808,629,616 | 3,810,508,130 |
| Checkpoints made | 10,023 | 108,649 |
| Checkpoint duration, 90% | 6s | 664ms |
| Checkpoint duration, 99.9% | 10s | 1s |
| Full checkpoint size *, 99% | 19.6GB | 25.6GB |
| Recovery time (local recovery disabled) | 20-21s | 35-65s (depending on the checkpoint) |
As can be seen from the above table, checkpoint duration is reduced 10 times for 99.9% of checkpoints, while space usage increases by 30%, and recovery time increases by 66%-225%.
More details about the checkpoints (Changelog Enabled / Changelog Disabled):
| Percentile | End to End Duration | Checkpointed Data Size * | Full Checkpoint Data Size * |
|---|---|---|---|
| 50% | 311ms / 5s | 14.8MB / 3.05GB | 24.2GB / 18.5GB |
| 90% | 664ms / 6s | 23.5MB / 4.52GB | 25.2GB / 19.3GB |
| 99% | 1s / 7s | 36.6MB / 5.19GB | 25.6GB / 19.6GB |
| 99.9% | 1s / 10s | 52.8MB / 6.49GB | 25.7GB / 19.8GB |
* Checkpointed Data Size is the size of data persisted after receiving the necessary number of checkpoint barriers, during a so-called synchronous and then asynchronous checkpoint phases. Most of the data is persisted pre-emptively (i.e. after the previous checkpoint and before the current one), and that’s why this size is much lower when the Changelog is enabled.
* Full checkpoint size is the total size of all the files comprising the checkpoint, including any files reused from the previous checkpoints. Compared to a normal checkpoint, the one with a changelog is less compact, keeping all the historical values since the last materialization, and therefore consumes much more space
Window workload #
This workload used Processing Time Sliding Window. As can be seen below, checkpoints are still faster, resulting in 3 times shorter durations; but storage amplification is much higher in this case (45 times more space consumed):
Checkpoint Statistics for Window Workload with Changelog Enabled / Changelog Disabled
| Percentile | End to End Duration | Checkpointed Data Size | Full Checkpoint Data Size |
|---|---|---|---|
| 50% | 791ms / 1s | 269MB / 1.18GB | 85.5GB / 1.99GB |
| 90% | 1s / 1s | 292MB / 1.36GB | 97.4GB / 2.16GB |
| 99% | 1s / 6s | 310MB / 1.67GB | 103GB / 2.26GB |
| 99.9% | 2s / 6s | 324MB / 1.87GB | 104GB / 2.30GB |
The increase in space consumption (Full Checkpoint Data Size) can be attributed to:
- Assigning each element to multiple sliding windows (and persisting the state changelog for each). While RocksDB and Heap have the same issue, with changelog the impact is multiplied even further.
- As mentioned above, if the underlying state backend (i.e. RocksDB) is able to accumulate multiple state updates for the same key without flushing, the snapshot will be smaller in size than the changelog. In this particular case of sliding window, the updates to its contents are eventually followed by purging that window. If those updates and purge happen during the same checkpoint, then it’s quite likely that the window is not included in the snapshot. This also implies that the faster the window is purged, the smaller the size of the snapshot is.
Conclusion and future work #
Generic log-based incremental checkpoints is released as MVP version in Flink 1.15. This version demonstrates that solutions based on modern DFS can provide good enough latency. Furthermore, checkpointing time and stability are improved significantly by using the Changelog. However, some trade-offs must be made before using it (in particular, space amplification).
In the next releases, we plan to enable more use cases for Changelog, e.g., by reducing recovery time via local recovery and improving compatibility.
Another direction is further reducing latency. This can be achieved by using faster storage, such as Apache Bookkeeper or Apache Kafka.
Besides that, we are investigating other applications of Changelog, such as WAL for sinks and queryable states.
We encourage you to try out this feature and assess the pros and cons of using it in your setup. The simplest way to do this it is to add the following to your flink-conf.yaml:
state.backend.changelog.enabled: true
state.backend.changelog.storage: filesystem
dstl.dfs.base-path: <location similar to state.checkpoints.dir>
Please see the full documentation here.
Acknowledgments #
We thank Stephan Ewen for the initial idea of the project, and many other engineers including Piotr Nowojski, Yu Li and Yun Tang for design discussions and code reviews.