FLIP-147: Support Checkpoints After Tasks Finished - Part Two
July 11, 2022 - Yun Gao Dawid Wysakowicz Daisy TsangIn the first part of this blog, we have briefly introduced the work to support checkpoints after tasks get finished and revised the process of finishing. In this part we will present more details on the implementation, including how we support checkpoints with finished tasks and the revised protocol of the finish process.
Implementation of support Checkpointing with Finished Tasks #
As described in part one, to support checkpoints after some tasks are finished, the core idea is to mark the finished operators in checkpoints and skip executing these operators after recovery. To implement this idea, we enhanced the checkpointing procedure to generate the flag and use the flag on recovery. This section presents more details on the process of taking checkpoints with finished tasks and recovery from such checkpoints.
Previously, checkpointing only worked when all tasks were running. As shown in the Figure 1, in this case the checkpoint coordinator first notify all the source tasks, and then the source tasks further notify the downstream tasks to take snapshots via barrier events. Similarly, if there are finished tasks, we need to find the new “source” tasks to initiate the checkpoint, namely those tasks that are still running but have no running precedent tasks. CheckpointCoordinator does the computation atomically at the JobManager side based on the latest states recorded in the execution graph.
There might be race conditions when triggering tasks: when the checkpoint coordinator decides to trigger one task and starts emitting the RPC, it is possible that the task is just finished and reporting the FINISHED status to JobManager. In this case, the RPC message would fail and the checkpoint would be aborted.
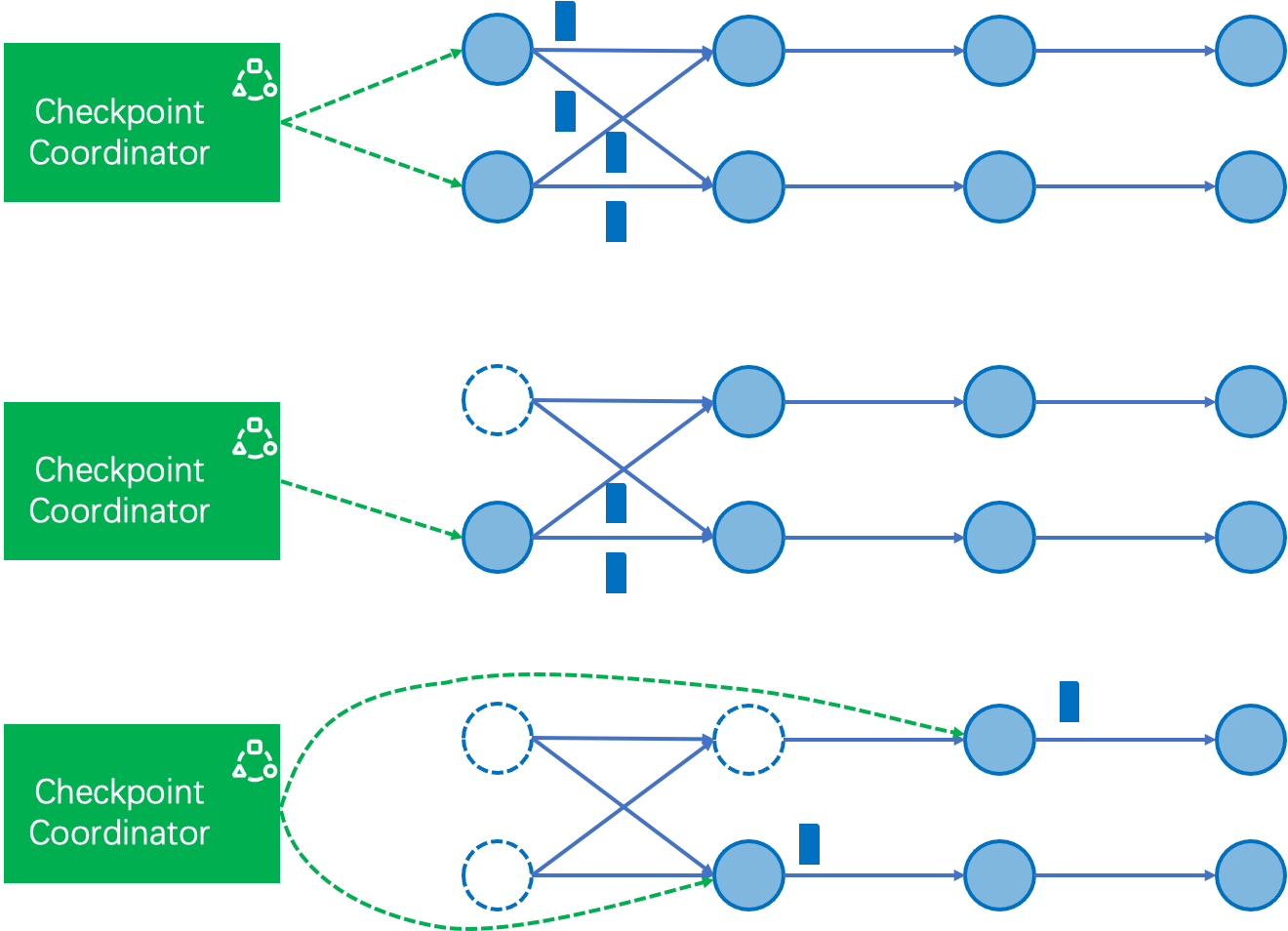
Figure 1. The tasks chosen as the new sources when taking checkpoint with finished tasks. The principle is to choose the running tasks whose precedent tasks are all finished.
In order to keep track of the finish status of each operator, we need to extend the checkpoint format. A checkpoint consists of the states of all the stateful operators, and the state of one operator consists of the entries from all its parallel instances. Note that the concept of Task is not reflected in the checkpoint. Task is more of a physical execution container that drives the behavior of operators. It is not well-defined across multiple executions of the same job since job upgrades might modify the operators contained in one task. Therefore, the finished status should also be attached to the operators.
As shown in the Figure 2, operators could be classified into three types according to their finished status:
- Fully finished: If all the instances of an operator are finished, we could view the logic of the operators as fully executed and we should skip the execution of the operator after recovery. We need to store a special flag for this kind of operator.
- Partially finished: If only some instances of an operator are finished, then we still need to continue executing the remaining logic of this operator. As a whole we could view the state of the operator as the set of entries collected from all the running instances, which represents the remaining workload for this operator.
- No finished instances: In this case, the state of the operator is the same as the one taken when no tasks are finished.
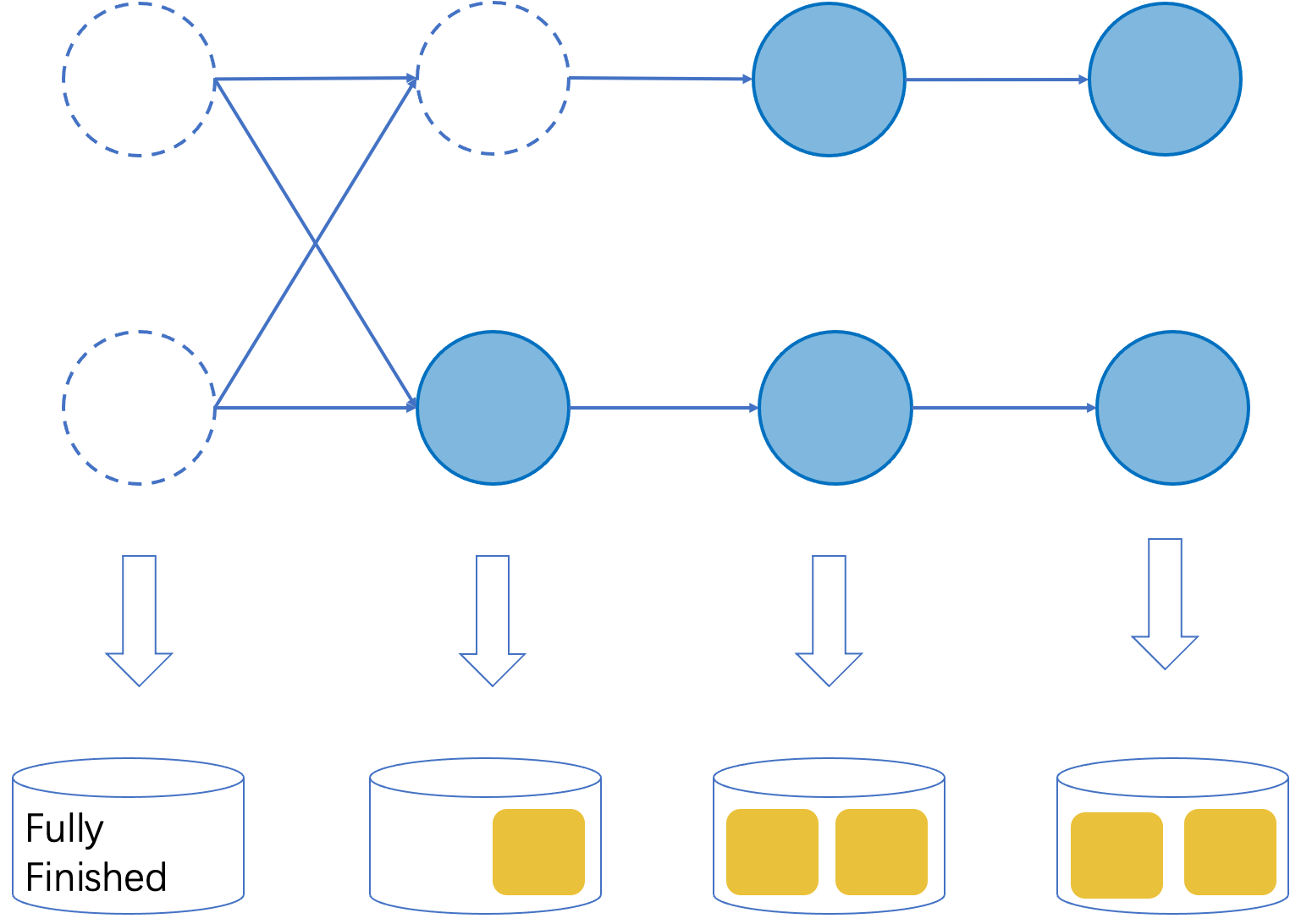
Figure 2. An illustration of the extended checkpoint format.
If the job is later restored from a checkpoint taken with finished tasks, we would skip executing all the logic for fully finished operators, and execute normally for the operators with no finished instances.
However, this would be a bit complex for the partially finished operators. The state of partially finished operators would be redistributed to all the instances, similar to rescaling when the parallelism is changed. Among all the types of states that Flink offers, the keyed state and operator state with even-split redistribution would work normally, but the broadcast state and operator state with union redistribution would be affected for the following reasons:
- The broadcast state always replicates the state of the first subtask to the other subtasks. If the first subtask is finished, an empty state would be distributed and the operator would run from scratch, which is not correct.
- The operator state with union distribution merges the states of all the subtasks and then sends the merged state to all the subtasks. Based on this behavior, some operators may choose one subtask to store a shared value and after restarting this value will be distributed to all the subtasks. However, if this chosen task is finished, the state would be lost.
These two issues would not occur when rescaling since there would be no finished tasks in that scenario. To address these issues, we chose one of the running subtasks instead to acquire the current state for the broadcast state. For the operator state with union redistribution, we have to collect the states of all the subtasks to maintain the semantics. Thus, currently we abort the checkpoint if parts of subtasks finished for operators using this kind of state.
In principle, you should be able to modify your job (which changes the dataflow graph) and restore from a previous checkpoint. That said, there are certain graph modifications that are not supported. These kinds of changes include adding a new operator as the precedent of a fully finished one. Flink would check for such modifications and throw exceptions while restoring.
The Revised Process of Finishing #
As described in the part one, based on the ability to take checkpoints with finished tasks, we revised the process of finishing so that we could always commit all the data for two-phase-commit sinks. We’ll show the detailed protocol of the finished process in this section.
How did Jobs in Flink Finish Before? #
A job might finish in two ways: all sources finish or users execute
stop-with-savepoint [--drain].
Let’s first have a look at the detailed process of finishing before FLIP-147.
When sources finish #
If all the sources are bounded, The job will finish after all the input records are processed and all the result are
committed to external systems. In this case, the sources would first
emit a MAX_WATERMARK (Long.MAX_VALUE) and then start to terminate the task. On termination, a task would call endOfInput(),
close() and dispose() for all the operators, then emit an EndOfPartitionEvent to the downstream tasks. The intermediate tasks
would start terminating after receiving an EndOfPartitionEvent from all the input channels, and this process will continue
until the last task is finished.
1. Source operators emit MAX_WATERMARK
2. On received MAX_WATERMARK for non-source operators
a. Trigger all the event-time timers
b. Emit MAX_WATERMARK
3. Source tasks finished
a. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
4. On received EndOfPartitionEvent for non-source tasks
a. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
When users execute stop-with-savepoint [–drain] #
Users could execute the command stop-with-savepoint [–drain] for both bounded and unbounded jobs to trigger jobs to finish. In this case, Flink first triggers a synchronous savepoint and all the tasks would stall after seeing the synchronous savepoint. If the savepoint succeeds, all the source operators would finish actively and the job would finish the same as the above scenario.
1. Trigger a savepoint
2. Sources received savepoint trigger RPC
a. If with –-drain
i. source operators emit MAX_WATERMARK
b. Source emits savepoint barrier
3. On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
4. On received savepoint barrier for non-source operators
a. The task blocks till the savepoint succeed
5. Finish the source tasks actively
a. If with –-drain
ii. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
6. On received EndOfPartitionEvent for non-source tasks
a. If with –-drain
i. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
A parameter –-drain is supported with stop-with-savepoint: if not specified, the job is expected to resume from this savepoint,
otherwise the job is expected to terminate permanently. Thus we only emit MAX_WATERMARK to trigger all the event timers and call
endInput() in the latter case.
Revise the Finishing Steps #
As described in part one, after revising the process of finishing, we have decoupled the process of “finishing operator logic”
and “finishing task” by introducing a new EndOfData event. After the revision each task will first
notify the descendants with an EndOfData event after executing all the logic
so that the descendants also have chances to finish executing the operator logic, then
all the tasks could wait for the next checkpoint or the specified savepoint concurrently to commit all the remaining data.
This section will present the detailed protocol of the revised process. Since we have renamed
close() /dispose() to finish() / close(), we’ll stick to the new terminologies in the following description.
The revised process of finishing is shown as follows:
1. Source tasks finished due to no more records or stop-with-savepoint.
a. if no more records or stop-with-savepoint –-drain
i. source operators emit MAX_WATERMARK
ii. endInput(inputId) for all the operators
iii. finish() for all the operators
iv. emit EndOfData[isDrain = true] event
b. else if stop-with-savepoint
i. emit EndOfData[isDrain = false] event
c. Wait for the next checkpoint / the savepoint after operator finished complete
d. close() for all the operators
e. Emit EndOfPartitionEvent
f. Task cleanup
2. On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
3. On received EndOfData for non-source tasks
a. If isDrain
i. endInput(int inputId) for all the operators
ii. finish() for all the operators
b. Emit EndOfData[isDrain = the flag value of the received event]
4. On received EndOfPartitionEvent for non-source tasks
a. Wait for the next checkpoint / the savepoint after operator finished complete
b. close() for all the operators
c. Emit EndOfPartitionEvent
d. Task cleanup
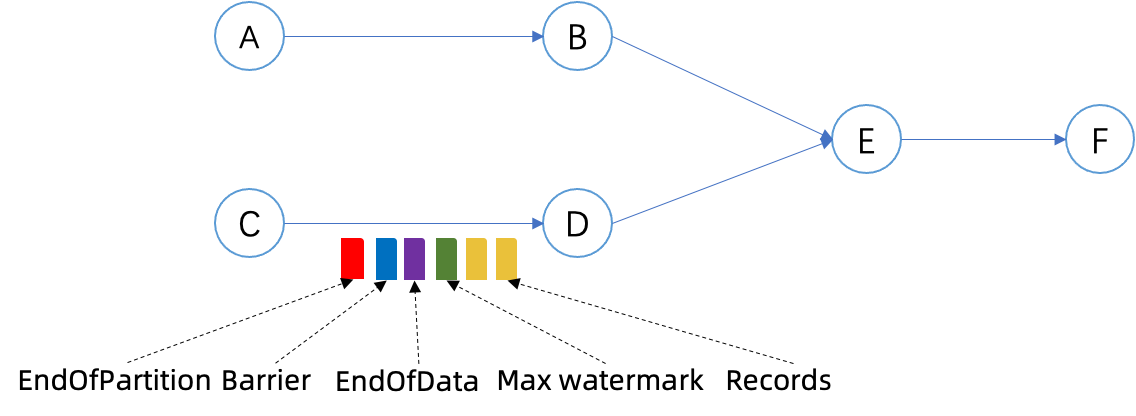
Figure 3. An example job of the revised process of finishing.
An example of the process of job finishing is shown in Figure 3.
Let’s first have a look at the example that all the source tasks are bounded.
If Task C finishes after processing all the records, it first emits the max-watermark, then finishes the operators and emits
the EndOfData event. After that, it waits for the next checkpoint to complete and then emits the EndOfPartitionEvent.
Task D finishes all the operators right after receiving the EndOfData event. Since any checkpoints taken after operators finish
can commit all the pending records and be the final checkpoint, Task D’s final checkpoint would be the same as Task C’s since
the barrier must be emitted after the EndOfData event.
Task E is a bit different in that it has two inputs. Task A might continue to run for a while and, thus, Task E needs to wait
until it receives an EndOfData event also from the other input before finishing operators and its final checkpoint might be different.
On the other hand, when using stop-with-savepoint [--drain], the process is similar except that all the tasks need to wait for the exact
savepoint before finishing instead of just any checkpoints. Moreover, since both Task C and Task A would finish at the same time,
Task E would also be able to wait for this particular savepoint before finishing.
Conclusion #
In this part we have presented more details of how the checkpoints are taken with finished tasks and the revised process of finishing. We hope the details could provide more insights of the thoughts and implementations for this part of work. Still, if you have any questions, please feel free to start a discussion or report an issue in the dev or user mailing list.