Apache Flink Kubernetes Operator 1.4.0 Release Announcement
February 27, 2023 - Gyula Fora (@GyulaFora) Maximilian Michels (@stadtlegende) Matyas Orhidi (@matyasorhidi)We are proud to announce the latest stable release of the operator. In addition to the expected stability improvements and fixes, the 1.4.0 release introduces the first version of the long-awaited autoscaler module.
Flink Streaming Job Autoscaler #
A highly requested feature for Flink applications is the ability to scale the pipeline based on incoming data load and the utilization of the dataflow. While Flink has already provided some of the required building blocks, this feature has not yet been realized in the open source ecosystem.
With FLIP-271 the community set out to build such an autoscaler component as part of the Kubernetes Operator subproject. The Kubernetes Operator proved to be a great place for the autoscaler module as it already contains all the necessary bits for managing and upgrading production streaming applications.
Fast-forward to the 1.4.0 release, we now have the first fully functional autoscaler implementation in the operator, ready to be tested and used in production applications. For more, detailed information, please refer to the Autoscaler Documentation.
Overview #
The autoscaler uses Flink task metrics to effectively and independently scale the job vertices of the streaming pipeline. This removes backpressure from the job to ensure an optimal flow of data at the lowest possible resource usage. All kind of jobs, including SQL jobs, can be scaled with this method.
The approach is based on Three steps is all you need: fast, accurate, automatic scaling decisions for distributed streaming dataflows by Kalavri et al. Shoutout to our fellow Flink community member and committer Vasiliki Kalavri! The used metrics include: Source metrics:
- number of pending records (source only)
- number of partitions (source only)
- ingestion rate (source only)
- processing rate
- time spent processing (utilization) The algorithm starts from the sources and recursively computes the required processing capacity for each operator in the pipeline. At the source vertices, target data rate (processing capacity) is equal to the data rate in Kafka.
For other operators we compute it as the sum of the input (upstream) operators output data rate.
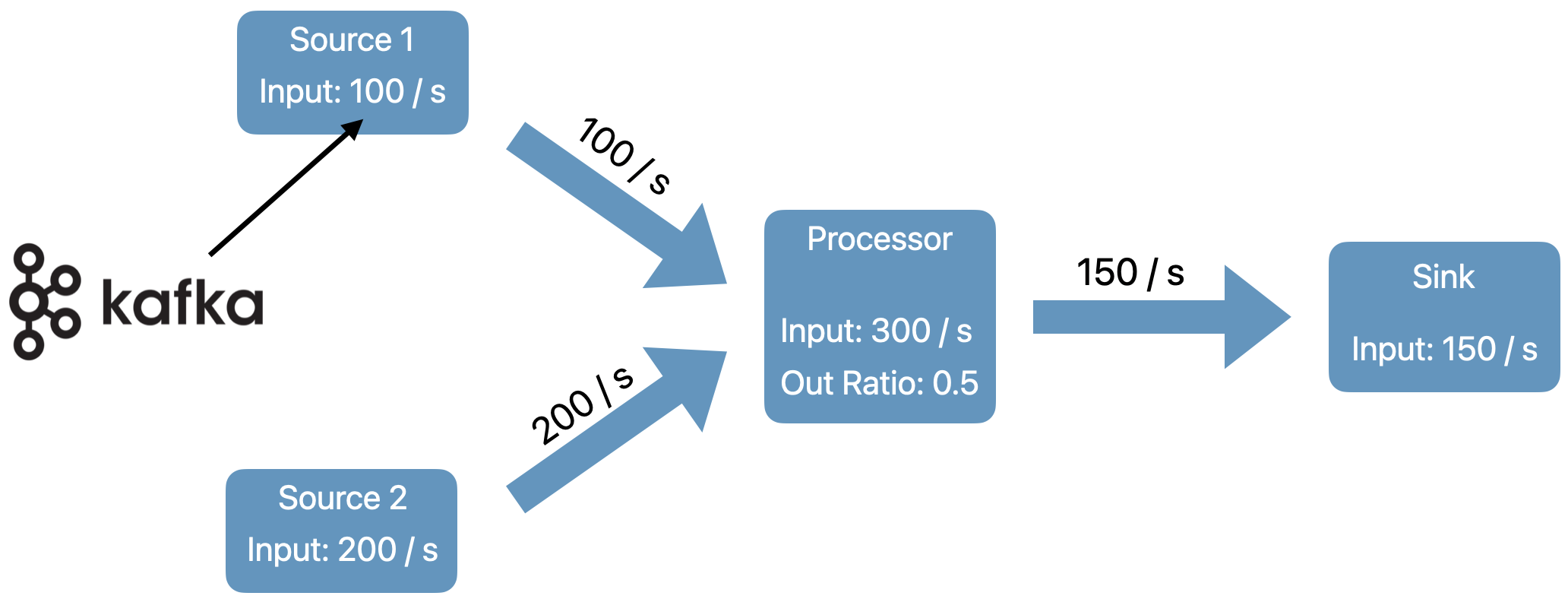
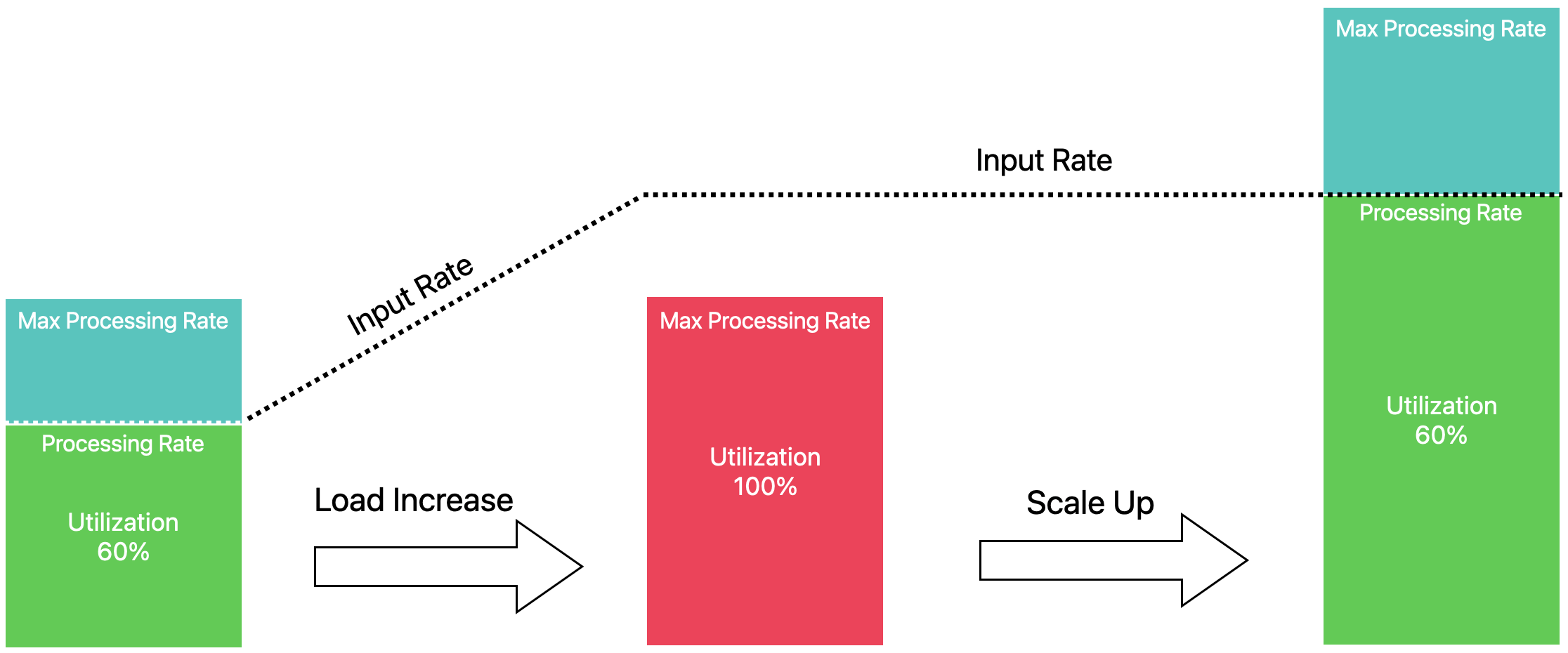
Users configure the target utilization percentage of the operators in the pipeline, e.g. keep the all operators between 60% - 80% busy. The autoscaler then finds a configuration such that the output rates of all operators match the input rates of all their downstream operators at the targeted utilization.
In this example we see an upscale operation:
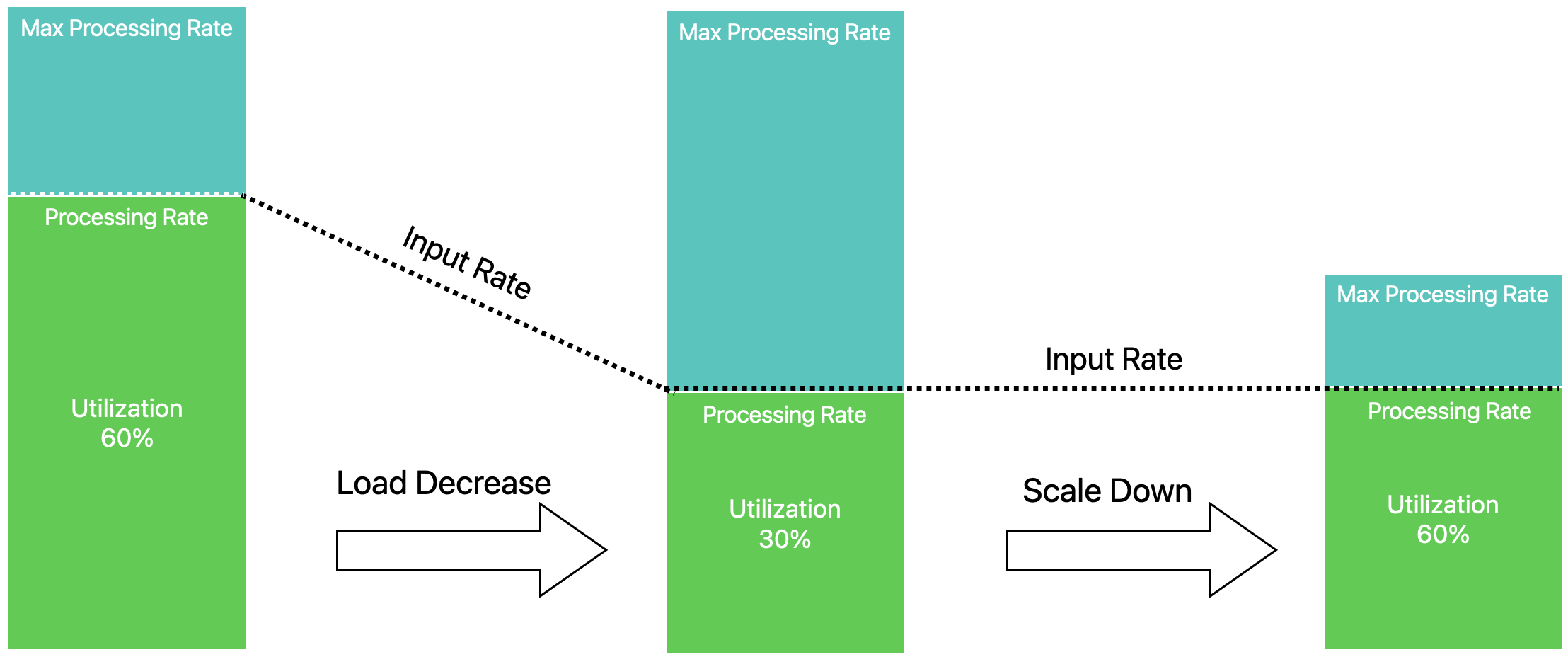
Similarly as load decreases, the autoscaler adjusts individual operator parallelism levels to match the current rate over time.
The operator reports detailed JobVertex level metrics about the evaluated Flink job metrics that are collected and used in the scaling decision. This includes:
- Utilization, input rate, target rate metrics
- Scaling thresholds
- Parallelism and max parallelism changes over time
These metrics are reported under the Kubernetes Operator Resource metric group:
[resource_prefix].Autoscaler.[jobVertexID].[ScalingMetric].Current/Average
Limitations #
While we are very happy with the progress we have made in the last few months, the autoscaler is still in an early stage of development. We rely on users to share feedback so we can improve and make this a very robust component.
- The autoscaler currently requires Flink 1.17
- Source scaling requires the standard connector metrics, currently works best with Kafka sources
ZooKeeper HA Support #
Until now the operator only integrated with the Flink Kubernetes HA mechanism for last-state and other types of application upgrades. 1.4.0 adds support for the ZooKeeper HA storage as well.
While ZooKeeper is a slightly older solution, many users are still using it for HA metadata even in the Kubernetes world.
Release Resources #
The source artifacts and helm chart are available on the Downloads page of the Flink website. You can easily try out the new features shipped in the official 1.4.0 release by adding the Helm chart to your own local registry:
$ helm repo add flink-kubernetes-operator-1.4.0 https://archive.apache.org/dist/flink/flink-kubernetes-operator-1.4.0/
$ helm install flink-kubernetes-operator flink-kubernetes-operator-1.4.0/flink-kubernetes-operator --set webhook.create=false
You can also find official Kubernetes Operator Docker images of the new version on Dockerhub.
For more details, check the updated documentation and the release notes. We encourage you to download the release and share your feedback with the community through the Flink mailing lists or JIRA.
List of Contributors #
Anton Ippolitov, FabioWanner, Gabor Somogyi, Gyula Fora, James Busche, Kyle Ahn, Matyas Orhidi, Maximilian Michels, Mohemmad Zaid Khan, Márton Balassi, Navaneesh Kumar, Ottomata, Peter Huang, Rodrigo, Shang Yuanchun, Shipeng Xie, Swathi Chandrashekar, Tony Garrard, Usamah Jassat, Vincent Chenal, Zsombor Chikan, Peter Vary