Announcing the Release of Apache Flink 1.19
March 18, 2024 - Lincoln Lee (@lincoln_86xy)The Apache Flink PMC is pleased to announce the release of Apache Flink 1.19.0. As usual, we are looking at a packed release with a wide variety of improvements and new features. Overall, 162 people contributed to this release completing 33 FLIPs and 600+ issues. Thank you!
Let’s dive into the highlights.
Flink SQL Improvements #
Custom Parallelism for Table/SQL Sources #
Now in Flink 1.19, you can set a custom parallelism for performance tuning via the scan.parallelism
option. The first available connector is DataGen (Kafka connector is on the way). Here is an example
using SQL Client:
-- set parallelism within the ddl
CREATE TABLE Orders (
order_number BIGINT,
price DECIMAL(32,2),
buyer ROW<first_name STRING, last_name STRING>,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'scan.parallelism' = '4'
);
-- or set parallelism via dynamic table option
SELECT * FROM Orders /*+ OPTIONS('scan.parallelism'='4') */;
More Information
Configurable SQL Gateway Java Options #
A new option env.java.opts.sql-gateway for specifying the Java options is introduced in Flink 1.19,
so you can fine-tune the memory settings, garbage collection behavior, and other relevant Java
parameters for SQL Gateway.
More Information
Configure Different State TTLs Using SQL Hint #
Starting from Flink 1.18, Table API and SQL users can set state time-to-live (TTL) individually for
stateful operators via the SQL compiled plan. In Flink 1.19, users have a more flexible way to
specify custom TTL values for regular joins and group aggregations directly within their queries by utilizing the STATE_TTL hint.
This improvement means that you no longer need to alter your compiled plan to set specific TTLs for
these frequently used operators. With the introduction of STATE_TTL hints, you can streamline your workflow and
dynamically adjust the TTL based on your operational requirements.
Here is an example:
-- set state ttl for join
SELECT /*+ STATE_TTL('Orders'= '1d', 'Customers' = '20d') */ *
FROM Orders LEFT OUTER JOIN Customers
ON Orders.o_custkey = Customers.c_custkey;
-- set state ttl for aggregation
SELECT /*+ STATE_TTL('o' = '1d') */ o_orderkey, SUM(o_totalprice) AS revenue
FROM Orders AS o
GROUP BY o_orderkey;
More Information
Named Parameters for Functions and Procedures #
Named parameters now can be used when calling a function or stored procedure. With named parameters, users do not need to strictly specify the parameter position, just specify the parameter name and its corresponding value. At the same time, if non-essential parameters are not specified, they will default to being filled with null.
Here’s an example of defining a function with one mandatory parameter and two optional parameters using named parameters:
public static class NamedArgumentsTableFunction extends TableFunction<Object> {
@FunctionHint(
output = @DataTypeHint("STRING"),
arguments = {
@ArgumentHint(name = "in1", isOptional = false, type = @DataTypeHint("STRING")),
@ArgumentHint(name = "in2", isOptional = true, type = @DataTypeHint("STRING")),
@ArgumentHint(name = "in3", isOptional = true, type = @DataTypeHint("STRING"))})
public void eval(String arg1, String arg2, String arg3) {
collect(arg1 + ", " + arg2 + "," + arg3);
}
}
When calling the function in SQL, parameters can be specified by name, for example:
SELECT * FROM TABLE(myFunction(in1 => 'v1', in3 => 'v3', in2 => 'v2'));
Also the optional parameters can be omitted:
SELECT * FROM TABLE(myFunction(in1 => 'v1'));
More Information
Window TVF Aggregation Features #
- Supports SESSION Window TVF in Streaming Mode
Now users can use SESSION Window TVF in streaming mode. A simple example is as follows:
-- session window with partition keys
SELECT * FROM TABLE(
SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES));
-- apply aggregation on the session windowed table with partition keys
SELECT window_start, window_end, item, SUM(price) AS total_price
FROM TABLE(
SESSION(TABLE Bid PARTITION BY item, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES))
GROUP BY item, window_start, window_end;
- Supports Changelog Inputs for Window TVF Aggregation
Window aggregation operators (generated based on Window TVF Function) can now handle changelog streams (e.g., CDC data sources, etc.). Users are recommended to migrate from legacy window aggregation to the new syntax for more complete feature support.
More Information
New UDF Type: AsyncScalarFunction #
The common UDF type ScalarFunction works well for CPU-intensive operations, but less well for IO
bound or otherwise long-running computations. In Flink 1.19, we have a new AsyncScalarFunction
which is a user-defined asynchronous ScalarFunction allows for issuing concurrent function calls
asynchronously.
More Information
Tuning: MiniBatch Optimization for Regular Joins #
The record amplification is a pain point when performing cascading joins in Flink, now in Flink 1.19, the new mini-batch optimization can be used for regular join to reduce intermediate result in such cascading join scenarios.
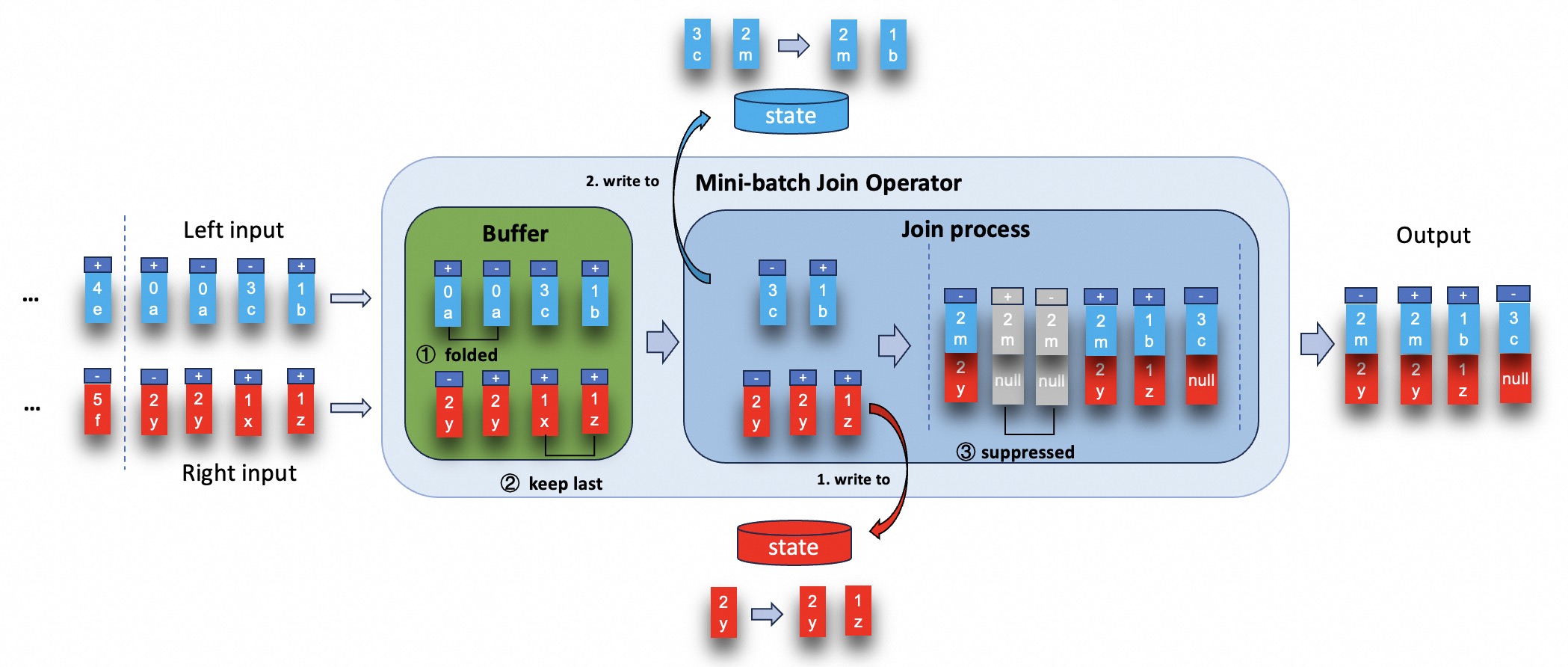
More Information
Runtime & Coordination Improvements #
Dynamic Source Parallelism Inference for Batch Jobs #
In Flink 1.19, we have supported dynamic source parallelism inference for batch jobs, which allows
source connectors to dynamically infer the parallelism based on the actual amount of data to consume.
This feature is a significant improvement over previous versions, which only assigned a fixed default
parallelism to source vertices.
Source connectors need to implement the inference interface to enable dynamic parallelism inference.
Currently, the FileSource connector has already been developed with this functionality in place.
Additionally, the configuration execution.batch.adaptive.auto-parallelism.default-source-parallelism
will be used as the upper bound of source parallelism inference. And now it will not default to 1.
Instead, if it is not set, the upper bound of allowed parallelism set via
execution.batch.adaptive.auto-parallelism.max-parallelism will be used. If that configuration is
also not set, the default parallelism set via parallelism.default or StreamExecutionEnvironment#setParallelism()
will be used instead.
More Information
Standard YAML for Flink Configuration #
Starting with Flink 1.19, Flink has officially introduced full support for the standard YAML 1.2
syntax. The default configuration file has been changed to config.yaml and placed in the conf/
directory. Users should directly modify this file to configure Flink.
If users want to use the legacy configuration file flink-conf.yaml, users just need to copy this
file into the conf/ directory. Once the legacy configuration file flink-conf.yaml is detected,
Flink will prioritize using it as the configuration file. And in the upcoming Flink 2.0, the
flink-conf.yaml configuration file will no longer work.
More Information
Profiling JobManager/TaskManager on Flink Web #
In Flink 1.19, we support triggering profiling at the JobManager/TaskManager level, allowing users to create a profiling instance with arbitrary intervals and event modes (supported by async-profiler). Users can easily submit profiles and export results in the Flink Web UI.
For example, users can simply submit a profiling instance with a specified period and mode by “Creating a Profiling Instance” after identifying a candidate TaskManager/JobManager with a performance bottleneck:
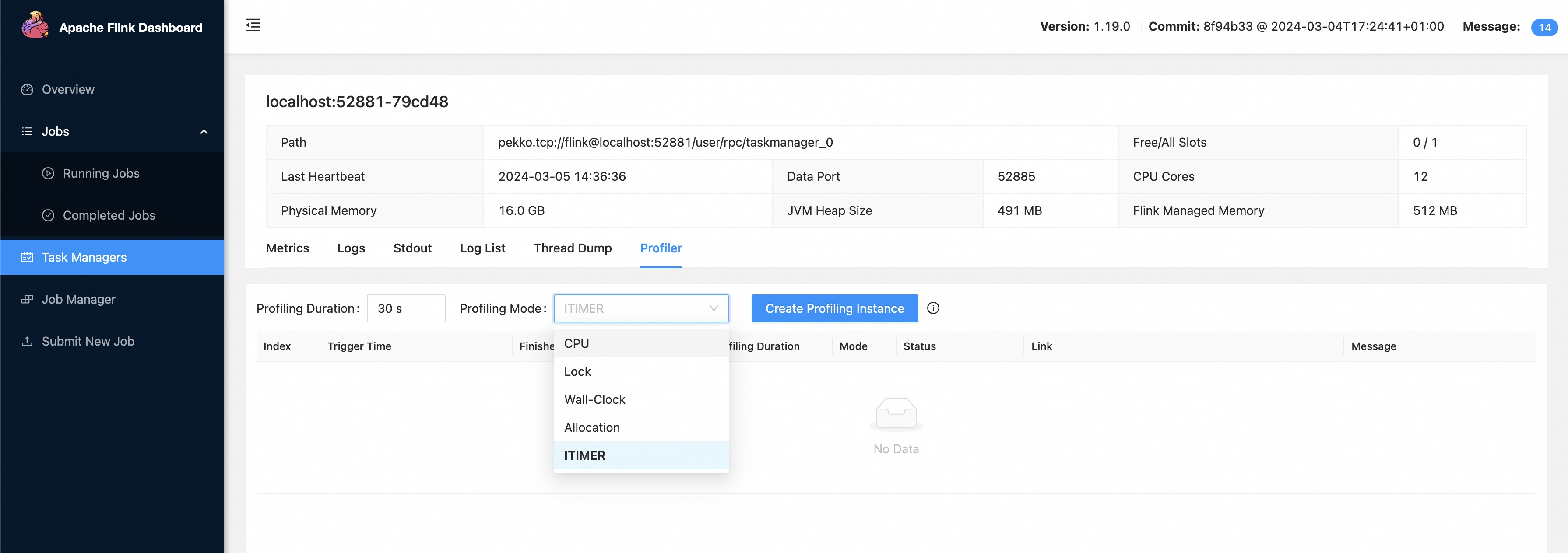
then easily download the interactive HTML file after the profiling instance is complete:

More Information
New Config Options for Administrator JVM Options #
A set of administrator JVM options are available, which prepend the user-set extra JVM options for platform-wide JVM tuning.
More Information
Beta Support for Java 21 #
Apache Flink was made ready to compile and run with Java 21. This feature is still in beta mode. Issues should be reported in Flink’s bug tracker.
More Information
Checkpoints Improvements #
Using Larger Checkpointing Interval When Source is Processing Backlog #
IsProcessingBacklog is introduced to indicate whether a record should be processed with low latency
or high throughput. Connector developers can update the Source implementation to utilize the
SplitEnumeratorContext#setIsProcessingBacklog method to report whether the records are backlog records.
Users can set the execution.checkpointing.interval-during-backlog to use a larger checkpoint interval
to enhance the throughput while the job is processing backlog if the source is backlog-aware.
More Information
CheckpointsCleaner Clean Individual Checkpoint States in Parallel #
Now when disposing of no longer needed checkpoints, every state handle/state file will be disposed
in parallel by the ioExecutor, vastly improving the disposing speed of a single checkpoint (for
large checkpoints the disposal time can be improved from 10 minutes to < 1 minute) . The old
behavior can be restored by setting state.checkpoint.cleaner.parallel-mode to false.
More Information
Trigger Checkpoints through Command Line Client #
The command line interface supports triggering a checkpoint manually. Usage:
./bin/flink checkpoint $JOB_ID [-full]
By specifying the ‘-full’ option, a full checkpoint is triggered. Otherwise an incremental checkpoint is triggered if the job is configured to take incremental ones periodically.
More Information
Connector API Improvements #
New Interfaces to SinkV2 That Are Consistent with Source API #
In Flink 1.19, the SinkV2 API made some changes to align with Source API.
The following interfaces are deprecated: TwoPhaseCommittingSink, StatefulSink, WithPreWriteTopology, WithPreCommitTopology, WithPostCommitTopology.
The following new interfaces have been introduced: CommitterInitContext, CommittingSinkWriter, WriterInitContext, StatefulSinkWriter.
The following interface method’s parameter has been changed: Sink#createWriter.
The original interfaces will remain available during the 1.19 release line, but they will be removed
in consecutive releases.
More Information
New Committer Metrics to Track the Status of Committables #
The TwoPhaseCommittingSink#createCommitter method parameterization has been changed, a new
CommitterInitContext parameter has been added. The original method will remain available during
the 1.19 release line, but they will be removed in consecutive releases.
More Information
- FLINK-25857
- FLIP-371: Provide initialization context for Committer creation in TwoPhaseCommittingSink
Important Deprecations #
In preparation for the release of Flink 2.0 later this year, the community has decided to officially deprecate multiple APIs that were approaching end of life for a while.
- Flink’s
org.apache.flink.api.common.time.Timeis now officially deprecated and will be dropped in Flink 2.0 Please migrate it to Java’s ownDurationclass. Methods supporting theDurationclass that replace the deprecatedTime-based methods were introduced. org.apache.flink.runtime.jobgraph.RestoreMode#LEGACYis deprecated. Please useRestoreMode#CLAIMorRestoreMode#NO_CLAIMmode instead to get a clear state file ownership when restoring.- The old method of resolving schema compatibility has been deprecated, please migrate to the new method following Migrating from deprecated
TypeSerializerSnapshot#resolveSchemaCompatibility(TypeSerializer newSerializer)before Flink 1.19. - Configuring serialization behavior through hard codes is deprecated, e.g.,
ExecutionConfig#enableForceKryo(). Please use the optionspipeline.serialization-config,pipeline.force-avro,pipeline.force-kryo, andpipeline.generic-types. Registration of instance-level serializers is deprecated, using class-level serializers instead. - We have deprecated all
setXxxandgetXxxmethods exceptgetString(String key, String defaultValue)andsetString(String key, String value), such as:setInteger,setLong,getIntegerandgetLongetc. Users and developers are recommend to use get and set methods withConfigOptioninstead of string as key. - The non-
ConfigOptionobjects in theStreamExecutionEnvironment,CheckpointConfig, andExecutionConfigand their corresponding getter/setter interfaces are now be deprecated. These objects and methods are planned to be removed in Flink 2.0. The deprecated interfaces include the getter and setter methods ofRestartStrategy,CheckpointStorage, andStateBackend. org.apache.flink.api.common.functions.RuntimeContext#getExecutionConfigis now officially deprecated and will be dropped in Flink 2.0. Please migrate all related usages to the new getter method:
MigrateTypeInformation#createSerializertoRuntimeContext#createTypeSerializer
MigrateRuntimeContext#getExecutionConfig.getGlobalJobParameterstoRuntimeContext#getGlobalJobParameters
MigrateRuntimeContext#getExecutionConfig.isObjectReuseEnabled()toRuntimeContext#isObjectReuseEnabledorg.apache.flink.api.common.functions.RichFunction#open(Configuration parameters)method has been deprecated and will be removed in future versions. Users are encouraged to migrate to the newRichFunction#open(OpenContext openContext).org.apache.flink.configuration.AkkaOptionsis deprecated and replaced withRpcOptions.
Upgrade Notes #
The Flink community tries to ensure that upgrades are as seamless as possible. However, certain changes may require users to make adjustments to certain parts of the program when upgrading to version 1.19. Please refer to the release notes for a comprehensive list of adjustments to make and issues to check during the upgrading process.
List of Contributors #
The Apache Flink community would like to express gratitude to all the contributors who made this release possible:
Adi Polak, Ahmed Hamdy, Akira Ajisaka, Alan Sheinberg, Aleksandr Pilipenko, Alex Wu, Alexander Fedulov, Archit Goyal, Asha Boyapati, Benchao Li, Bo Cui, Cheena Budhiraja, Chesnay Schepler, Dale Lane, Danny Cranmer, David Moravek, Dawid Wysakowicz, Deepyaman Datta, Dian Fu, Dmitriy Linevich, Elkhan Dadashov, Eric Brzezenski, Etienne Chauchot, Fang Yong, Feng Jiajie, Feng Jin, Ferenc Csaky, Gabor Somogyi, Gyula Fora, Hang Ruan, Hangxiang Yu, Hanyu Zheng, Hjw, Hong Liang Teoh, Hongshun Wang, HuangXingBo, Jack, Jacky Lau, James Hughes, Jane Chan, Jerome Gagnon, Jeyhun Karimov, Jiabao Sun, JiangXin, Jiangjie (Becket) Qin, Jim Hughes, Jing Ge, Jinzhong Li, JunRuiLee, Laffery, Leonard Xu, Lijie Wang, Martijn Visser, Marton Balassi, Matt Wang, Matthias Pohl, Matthias Schwalbe, Matyas Orhidi, Maximilian Michels, Mingliang Liu, Máté Czagány, Panagiotis Garefalakis, ParyshevSergey, Patrick Lucas, Peter Huang, Peter Vary, Piotr Nowojski, Prabhu Joseph, Pranav Sharma, Qingsheng Ren, Robin Moffatt, Roc Marshal, Rodrigo Meneses, Roman, Roman Khachatryan, Ron, Rui Fan, Ruibin Xing, Ryan Skraba, Samrat002, Sergey Nuyanzin, Shammon FY, Shengkai, Stefan Richter, SuDewei, TBCCC, Tartarus0zm, Thomas Weise, Timo Walther, Varun, Venkata krishnan Sowrirajan, Vladimir Matveev, Wang FeiFan, Weihua Hu, Weijie Guo, Wencong Liu, Xiangyu Feng, Xianxun Ye, Xiaogang Zhou, Xintong Song, XuShuai, Xuyang, Yanfei Lei, Yangze Guo, Yi Zhang, Yu Chen, Yuan Mei, Yubin Li, Yuepeng Pan, Yun Gao, Yun Tang, Yuxin Tan, Zakelly, Zhanghao Chen, Zhu Zhu, archzi, bvarghese1, caicancai, caodizhou, dongwoo6kim, duanyc, eason.qin, fengjiajie, fengli, gongzhongqiang, gyang94, hejufang, jiangxin, jiaoqingbo, jingge, lijingwei.5018, lincoln lee, liuyongvs, luoyuxia, mimaomao, murong00, polaris6, pvary, sharath1709, simplejason, sunxia, sxnan, tzy123-123, wangfeifan, wangzzu, xiangyu0xf, xiarui, xingbo, xuyang, yeming, yhx, yinhan.yh, yunfan123, yunfengzhou-hub, yunhong, yuxia Luo, yuxiang, zoudan, 周仁祥, 曹帝胄, 朱通通, 马越