Introducing the new Amazon Kinesis Data Stream and Amazon DynamoDB Stream sources
November 25, 2024 - Hong Liang TeohWe are pleased to introduce updated versions of the Amazon Kinesis Data Stream and Amazon DynamoDB Stream sources. Built on the FLIP-27 source interface, these newer connectors introduce 7 new features and are compatible with Flink 2.0.
The new KinesisStreamsSource replaces the legacy FlinkKinesisConsumer; and the new DynamoDbStreamsSource replaces the legacy FlinkDynamoDBStreamsConsumer. The new connectors are available for Flink 1.19 onwards, and AWS Connector version 5.0.0 onwards. For more information, see the section on Dependencies.
In this blogpost, we will dive into the motivation for the new source connectors, the improvements introduced, and provide migration guidance for users.
Dependencies #
| Connector | API | Dependency | Usage |
|---|---|---|---|
| Amazon Kinesis Data Streams source | DataStream Table API |
Use the flink-connector-aws-kinesis-streams artifact. See
Flink Kinesis connector documentation for details.
|
Use the fluent KinesisStreamsSourceBuilder to create the source. Look at the migration guidance section for more details. |
| Amazon Kinesis Data Streams source | SQL | Use the flink-sql-connector-aws-kinesis-streams artifact. See
Flink SQL Kinesis connector documentation for details.
|
Use the table identifier kinesis. See the
Flink SQL Kinesis connector documentation for configuration and usage details.
|
| Amazon DynamoDB Streams source | DataStream | Use the flink-connector-dynamodb artifact. See
Flink DynamoDB connector documentation for details.
|
Use the fluent DynamoDbStreamsSourceBuilder to create the source. Look at the migration guidance section for more details. |
Why did we need new source connectors? #
We implemented new source connectors because the FlinkKinesisConsumer and FlinkDynamoDBStreamsConsumer use the deprecated SourceFunction interface, which is removed in Flink 2.x. From Flink 2.x onwards, only KinesisStreamsSource and DynamoDbStreamsSource, which use the new Source interface will be supported.
In addition, the new Source interface introduces new features and standardisation across various Flink sources, such as unified metrics, native watermark handling, and support for coordination via a SourceEnumerator component running on the JobManager.
New features #
The updated KinesisStreamsSource and DynamoDbStreamsSource connectors offer the following new features:
- Native Flink watermark integration. On the new
Sourceinterface, watermark generation is abstracted away to the Flink framework, and no longer a responsibility of the source. This means the new source has support for watermark alignment, and idle watermark handling out-of-the-box. - Standardised Flink Source metrics. The new
Sourceframework also introduces standardised Source metrics. This enables users to track record throughput and lag across sources in a standardised manner. - Records are read in-order even after a resharding operation on the stream. The new
Sourceensures that parent shards are read completely before reading children shards. This allows record ordering to be maintained even after a resharding operation. See explanation of record ordering in Kinesis Data Streams for more information. - Migrate away from AWS SDK v1 to AWS SDK v2. This SDK update aligns with best practices.
- Migrate away from custom retry strategies to use the AWS SDK native retry strategies. This allows us to benefit from AWS error classification in the retry algorithm.
- Reduce jar size by >99%, from ~60MB to ~200KB. In the new source, we no longer shade the AWS SDK and no longer need to package the Kinesis Producer Library (needed for legacy sink). This will lead to smaller Flink application jars. Note that users will still need to shade the AWS SDK into the final Flink application jar. However, only one copy of the AWS SDK will be needed.
- Improve defaults. The
UniformShardAssigneris now the default shard assigner. This change results in a uniform shard distribution across Flink subtasks and can reduce unexpected processing skew.
Breaking changes #
During the implementation of the source Table API, we had to introduce some breaking changes around the table identifier of kinesis. This necessitated a major version bump from 4.x to 5.x. In Table API / SQL, for version 4.x and below, kinesis refers to the old FlinkKinesisConsumer. However, from 5.x onwards, kinesis now refers to the new KinesisStreamSource. To use the old FlinkKinesisConsumer with 5.x, you can use the table identifier of kinesis-legacy. See Kinesis Table API documentation for more details.
Migration guidance #
There is no state compatibility between the legacy sources (FlinkKinesisConsumer and FlinkDynamoDBStreamsConsumer), and the new sources (KinesisStreamsSource and DynamoDbStreamsSource). This means that in order to migrate from the legacy source to the new source, users must drop the state of the source operator and start from a specified starting position, to prevent any data loss.
Example migrating FlinkKinesisConsumer to KinesisStreamsSource
#
Here we show a simple example to migrate from FlinkKinesisConsumer to KinesisStreamsSource. See Flink Kinesis connector documentation for more details.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Old FlinkKinesisConsumer to read from stream test-stream from TRIM_HORIZON
Properties consumerConfig = new Properties();
consumerConfig.put(AWSConfigConstants.AWS_REGION, "us-east-1");
consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "TRIM_HORIZON");
FlinkKinesisConsumer<String> oldKinesisConsumer =
new FlinkKinesisConsumer<>("test-stream", new SimpleStringSchema(), consumerConfig);
DataStream<String> kinesisRecordsFromOldKinesisConsumer = env.addSource(oldKinesisConsumer)
.uid("custom-uid")
.assignTimestampsAndWatermarks(
WatermarkStrategy.<String>forMonotonousTimestamps().withIdleness(Duration.ofSeconds(1)))
// New KinesisStreamsSource to read from stream test-stream from TRIM_HORIZON
Configuration sourceConfig = new Configuration();
sourceConfig.set(KinesisSourceConfigOptions.STREAM_INITIAL_POSITION, KinesisSourceConfigOptions.InitialPosition.TRIM_HORIZON);
KinesisStreamsSource<String> newKdsSource =
KinesisStreamsSource.<String>builder()
.setStreamArn("arn:aws:kinesis:us-east-1:123456789012:stream/test-stream")
.setSourceConfig(sourceConfig)
.setDeserializationSchema(new SimpleStringSchema())
.build();
DataStream<String> kinesisRecordsWithEventTimeWatermarks = env.fromSource(
kdsSource,
WatermarkStrategy.<String>forMonotonousTimestamps().withIdleness(Duration.ofSeconds(1)),
"Kinesis source")
.returns(TypeInformation.of(String.class))
.uid("custom-uid");
Example migrating FlinkDynamoDBStreamsConsumer to DynamoDbStreamsSource
#
Here we show a simple example to migrate from FlinkDynamoDBStreamsConsumer to DynamoDbStreamsSource. See Flink DynamoDB connector documentation for more details.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Old FlinkDynamoDBStreamsConsumer to read from stream test stream from TRIM_HORIZON
Properties consumerConfig = new Properties();
consumerConfig.put(AWSConfigConstants.AWS_REGION, "us-east-1");
consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "TRIM_HORIZON");
FlinkDynamoDBStreamsConsumer<String> oldDynamodbStreamsConsumer =
new FlinkDynamoDBStreamsConsumer<>("arn:aws:dynamodb:us-east-1:1231231230:table/test/stream/2024-04-11T07:14:19.380", new SimpleStringSchema(), consumerConfig);
DataStream<String> dynamodbRecordsFromOldDynamodbStreamsConsumer = env.addSource(oldDynamodbStreamsConsumer)
.uid("custom-uid")
.assignTimestampsAndWatermarks(
WatermarkStrategy.<String>forMonotonousTimestamps().withIdleness(Duration.ofSeconds(1)))
// New DynamoDbStreamsSource to read from stream test stream from TRIM_HORIZON
Configuration sourceConfig = new Configuration();
sourceConfig.set(DynamodbStreamsSourceConfigConstants.STREAM_INITIAL_POSITION, DynamodbStreamsSourceConfigConstants.InitialPosition.TRIM_HORIZON);
KinesisStreamsSource<String> newDynamoDbStreamsSource =
DynamoDbStreamsSource.<String>builder()
.setStreamArn("arn:aws:dynamodb:us-east-1:1231231230:table/test/stream/2024-04-11T07:14:19.380")
.setSourceConfig(sourceConfig)
// User must implement their own deserialization schema to translate change data capture events into custom data types
.setDeserializationSchema(dynamodbDeserializationSchema)
.build();
DataStream<String> dynamodbRecordsWithEventTimeWatermarks = env.fromSource(
newDynamoDbStreamsSource,
WatermarkStrategy.<String>forMonotonousTimestamps().withIdleness(Duration.ofSeconds(1)),
"DynamoDB Streams source")
.returns(TypeInformation.of(String.class))
.uid("custom-uid");
Summary #
In this blog, we have covered the motivation behind creating the new KinesisStreamsSource and DynamoDbStreamsSource connectors, highlighting their new features and migration guidance. Feel free to reach out on the Flink mailing list (dev@flink.apache.org) or Flink Slack to discuss any further improvements.
To get started with the connectors, follow one of the guides below!
Further work #
Support for the below additional features are also in progress:
- Support for Table API and SQL for the DynamoDB Streams Source.
- Datastream Python integration for both sources are not implemented yet, but we recognize their importance to users.
List of Contributors #
Abhi Gupta, Aleksandr Pilipenko, Burak Ozakinci, Elphas Toringepi, Lorenzo Nicora, Danny Cranmer, Hong Teoh
Appendix: Detailed explanation of record ordering #
As a scalable streaming data store, the data records belonging to a Kinesis Data Stream are segregated across multiple shards, based on the partition key specified when writing the data record. Record ordering is maintained only within the same shard. Since records with the same partition key are written to the same shard, record ordering is maintained for a given partition key.
The situation gets complicated when the stream is resharded to scale the stream read/write capacity. During the resharding of a stream, shards go through split and merge operations. A split operation splits one parent shard into two smaller child shards. A merge operation merges two parent shards into one larger child shard.
An example of resharding a stream from 2 open shards to 3 open shards is shown below.
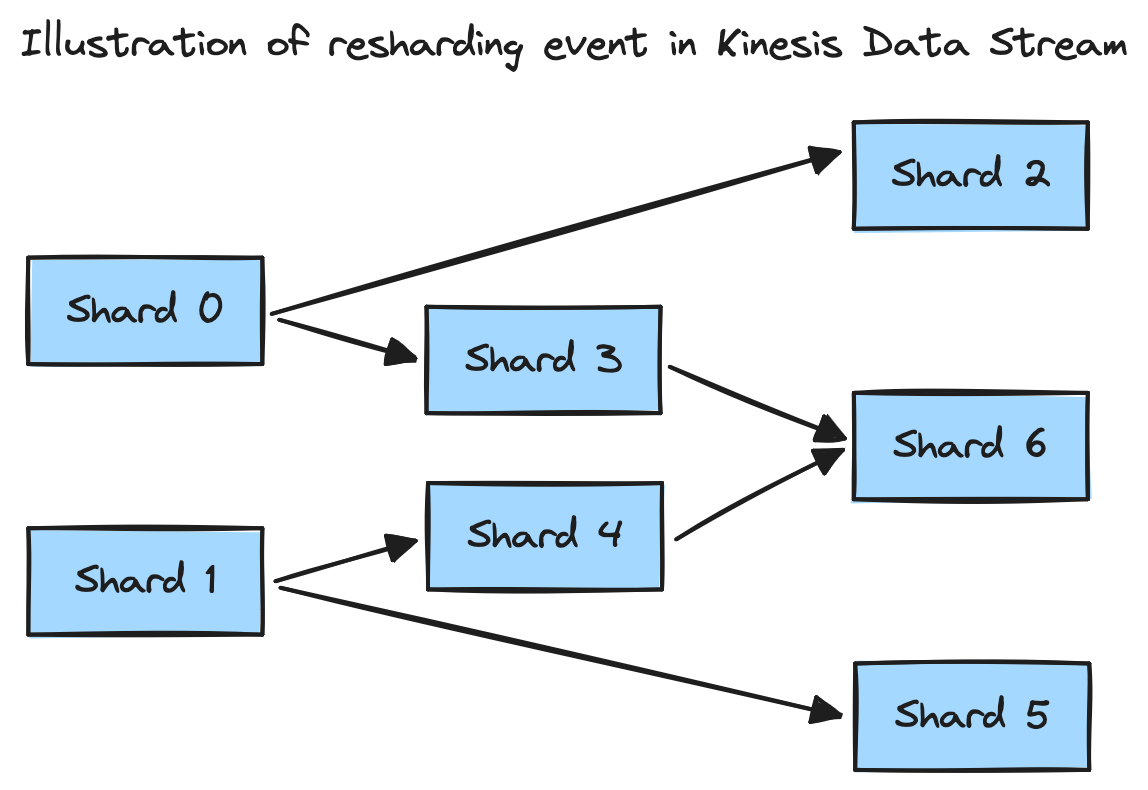
Fig. 1 - Illustration of uniform resharding event in Kinesis Data Stream from 2 shards to 3 shards.
In the diagram, the stream goes from having 2 open shards (0, 1) to having 3 open shards (2, 5, 6) and 4 closed shards (0, 1, 3, 4). Closed shards can contain records, but will no longer receive any new records, whereas open shards can still receive new records. The reason for multiple split/merge operations during this resharding is to prevent record skew across shards.
The diagram below illustrates what could happen when records with a given ordering within the same partition key are written to the stream.
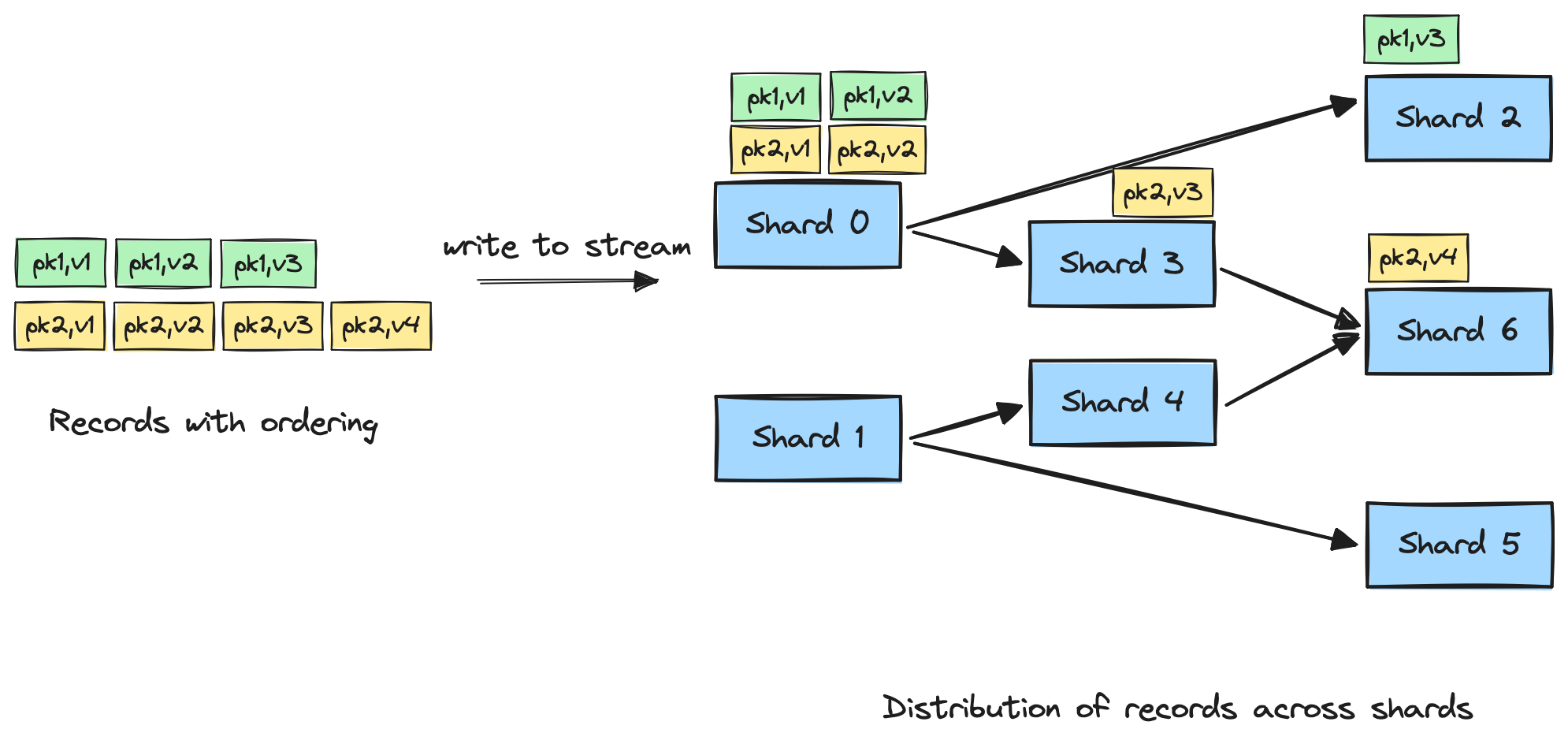
Fig. 2 - Illustration of record distribution within a Kinesis Data Stream after a resharding operation.
As we can see, to ensure that records from the pk2 are read in order, we need to ensure that the shards are read in order of Shard 0, then Shard 3, then Shard 6. This can be more easily understood as: All parent shards must be fully read before children shards can be read.
The new KinesisStreamsSource ensures that parent shards are read completely before reading children shards, and so ensures that record ordering is maintained even after a resharding operation on the stream.