Apache Flink in 2016: Year in Review
December 19, 2016 -2016 was an exciting year for the Apache Flink® community, and the release of Flink 1.0 in March marked the first time in Flink’s history that the community guaranteed API backward compatibility for all versions in a series. This step forward for Flink was followed by many new and exciting production deployments in organizations of all shapes and sizes, all around the globe.
In this post, we’ll look back on the project’s progress over the course of 2016, and we’ll also preview what 2017 has in store.
{%toc%}
Community Growth #
Github #
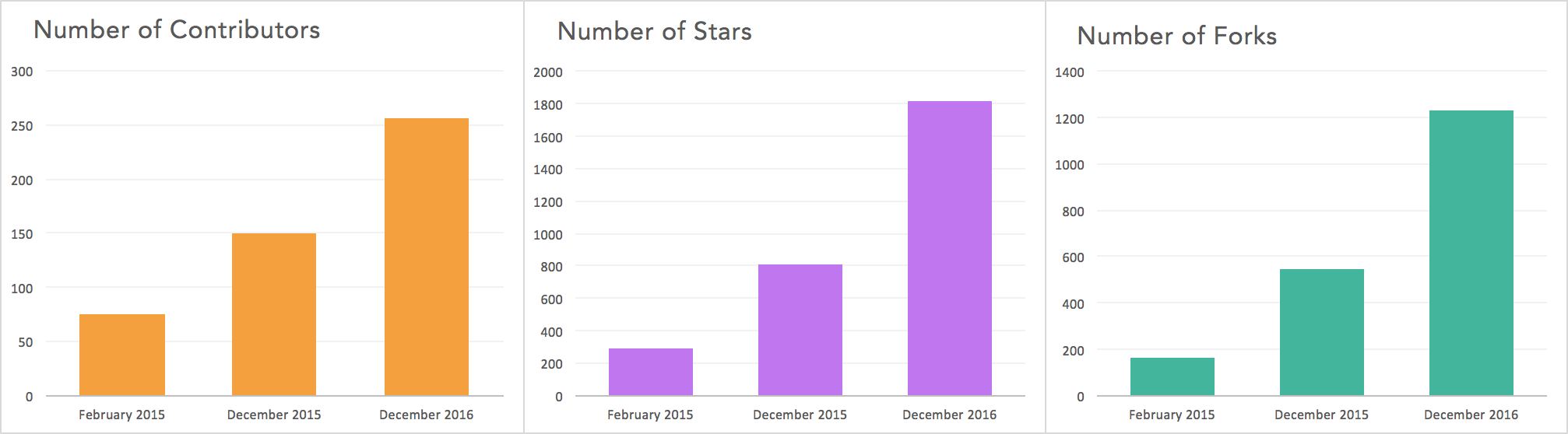
First, here’s a summary of community statistics from GitHub. At the time of writing:
- Contributors have increased from 150 in December 2015 to 258 in December 2016 (up 72%)
- Stars have increased from 813 in December 2015 to 1830 in December 2016 (up 125%)
- Forks have increased from 544 in December 2015 to 1255 in December 2016 (up 130%)
The community also welcomed 3 new committers in 2016: Chengxiang Li, Greg Hogan, and Tzu-Li (Gordon) Tai.
Next, let’s take a look at a few other project stats, starting with number of commits. If we run:
git log --pretty=oneline --after=12/31/2015 | wc -l
…inside the Flink repository, we’ll see a total of 1884 commits so far in 2016, bringing the all-time total commits to 10,015.
Now, let’s go a bit deeper. And here are instructions in case you’d like to take a look at this data yourself.
- Download gitstats from the project homepage. Or, on OS X with homebrew, type:
brew install --HEAD homebrew/head-only/gitstats
- Clone the Apache Flink git repository:
git clone git@github.com:apache/flink.git
- Generate the statistics
gitstats flink/ flink-stats/
- View all the statistics as an html page using your defaulf browser:
open flink-stats/index.html
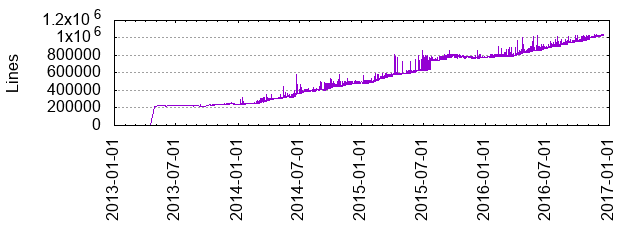
2016 is the year that Flink surpassed 1 million lines of code, now clocking in at 1,034,137 lines.
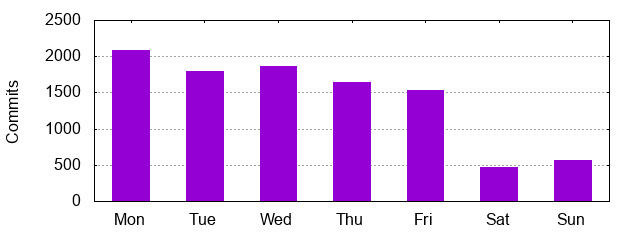
Monday remains the day of the week with the most commits over the project’s history:
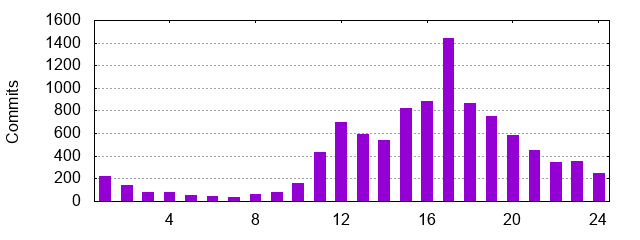
And 5pm is still solidly the preferred commit time:
Meetups #
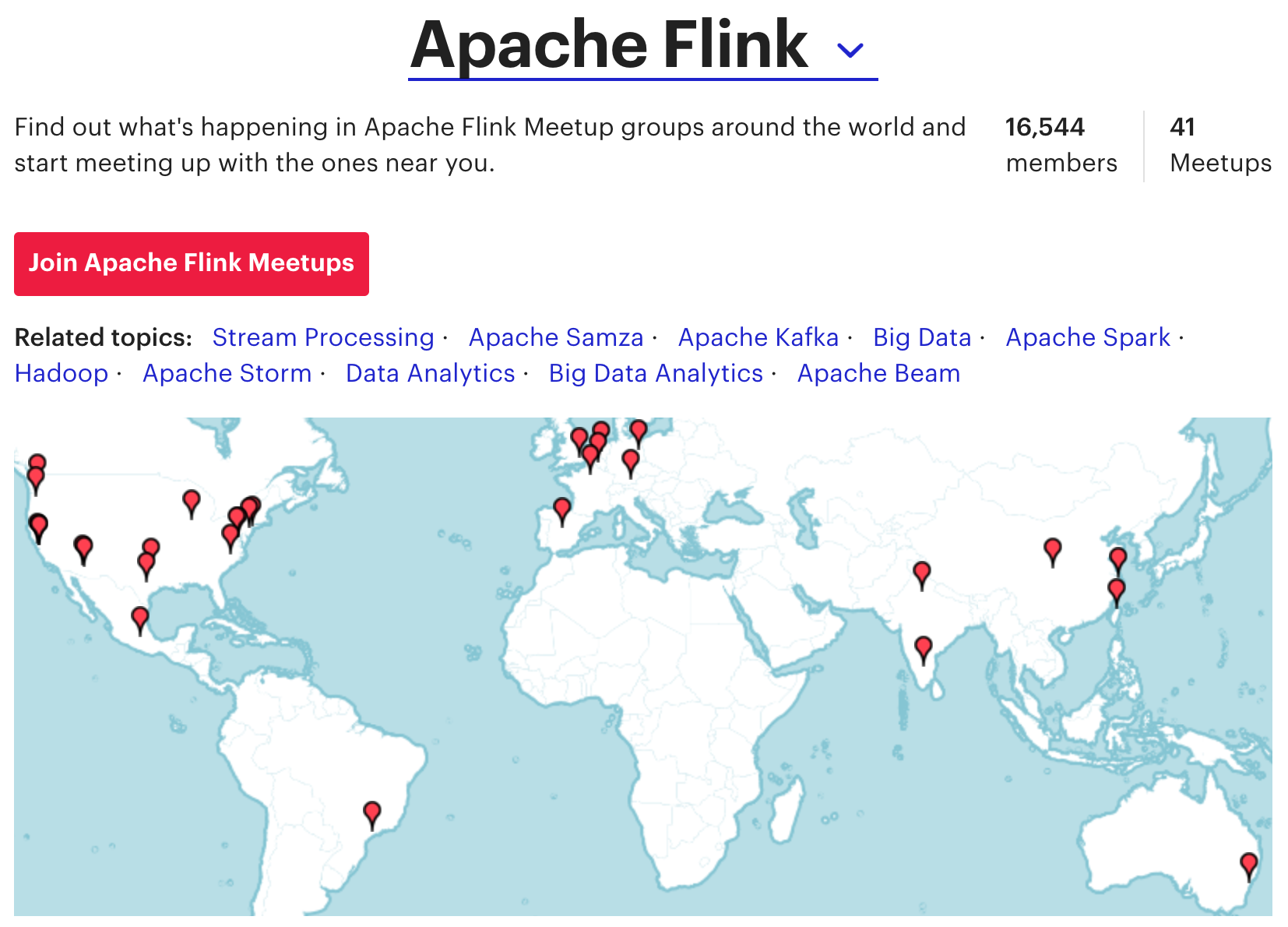
Apache Flink Meetup membership grew by 240% this year, and at the time of writing, there are 41 meetups comprised of 16,541 members listing Flink as a topic–up from 16 groups with 4,864 members in December 2015. The Flink community is proud to be truly global in nature.
Flink Forward 2016 #
The second annual Flink Forward conference took place in Berlin on September 12-14, and over 350 members of the Flink community came together for speaker sessions, training, and discussion about Flink. Slides and videos from speaker sessions are available online, and we encourage you to take a look if you’re interested in learning more about how Flink is used in production in a wide range of organizations.
Flink Forward will be expanding to San Francisco in April 2017, and the third-annual Berlin event is scheduled for September 2017.

Features and Ecosystem #
Flink Ecosystem Growth #
Flink was added to a selection of distributions during 2016, making it easier for an even larger base of users to start working with Flink:
In addition, the Apache Beam and Flink communities teamed up to build a Flink runner for Beam that, according to the Google team, is “sophisticated enough to be a compelling alternative to Cloud Dataflow when running on premise or on non-Google clouds”.
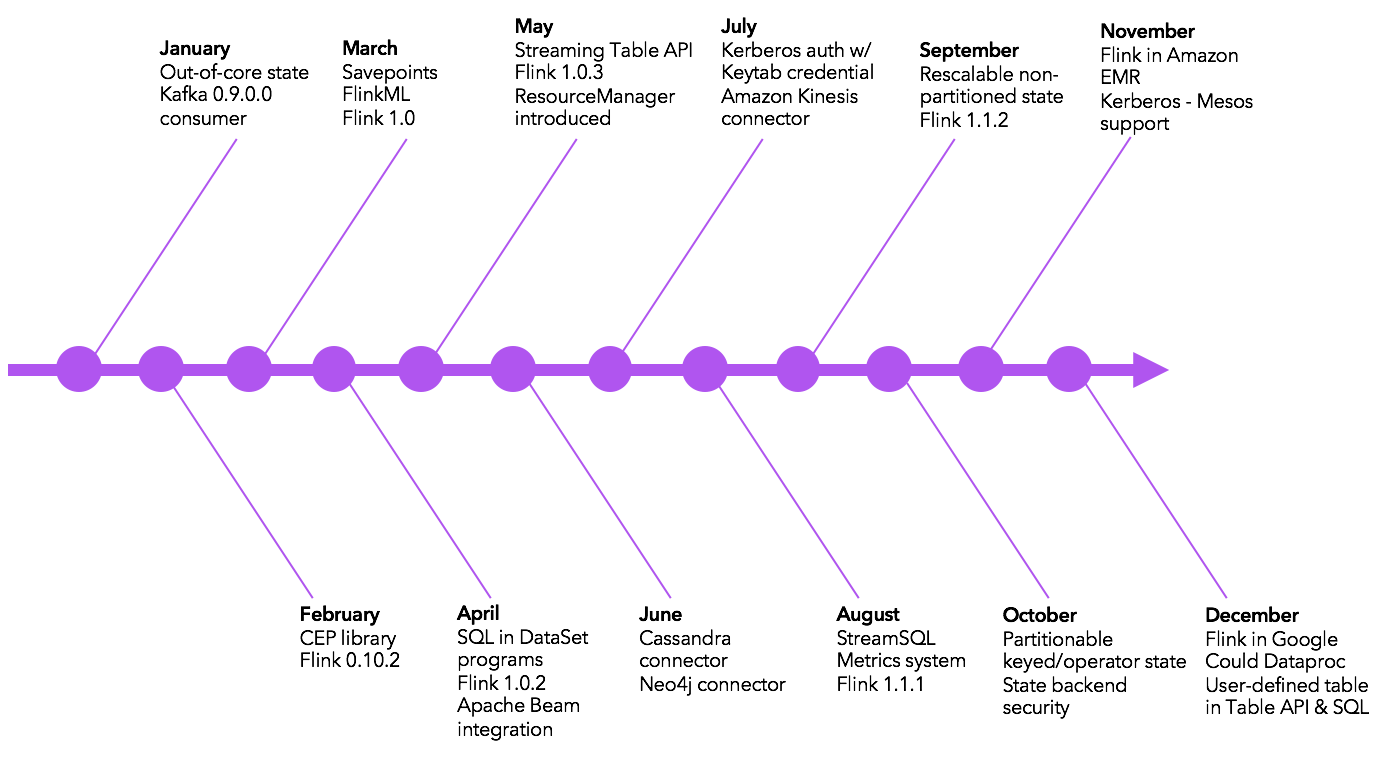
Feature Timeline in 2016 #
Here’s a selection of major features added to Flink over the course of 2016:
If you spend time in the Apache Flink JIRA project, you’ll see that the Flink community has addressed every single one of the roadmap items identified in 2015’s year in review post. Here’s to making that an annual tradition. :)
Looking ahead to 2017 #
A good source of information about the Flink community’s roadmap is the list of Flink Improvement Proposals (FLIPs) in the project wiki. Below, we’ll highlight a selection of FLIPs that have been accepted by the community as well as some that are still under discussion.
We should note that work is already underway on a number of these features, and some will even be included in Flink 1.2 at the beginning of 2017.
-
A new Flink deployment and process model, as described in FLIP-6. This work ensures that Flink supports a wide range of deployment types and cluster managers, making it possible to run Flink smoothly in any environment.
-
Dynamic scaling for both key-value state (as described in this PR) and non-partitioned state (as described in FLIP-8), ensuring that it’s always possible to split or merge state when scaling up or down, respectively.
-
Asynchronous I/O, as described in FLIP-12 , which makes I/O access a less time-consuming process without adding complexity or the need for extra checkpoint coordination.
-
Enhancements to the window evictor, as described in FLIP-4, to provide users with more control over how elements are evicted from a window.
-
Fined-grained recovery from task failures, as described in FLIP-1, to make it possible to restart only what needs to be restarted during recovery, building on cached intermediate results.
-
Unified checkpoints and savepoints, as described in FLIP-10, to allow savepoints to be triggered automatically–important for program updates for the sake of error handling because savepoints allow the user to modify both the job and Flink version whereas checkpoints can only be recovered with the same job.
-
Table API window aggregations, as described in FLIP-11, to support group-window and row-window aggregates on streaming and batch tables.
-
Side inputs, as described in this design document, to enable the joining of a main, high-throughput stream with one more more inputs with static or slowly-changing data.
If you’re interested in getting involved with Flink, we encourage you to take a look at the FLIPs and to join the discussion via the Flink mailing lists.
Lastly, we’d like to extend a sincere thank you to all of the Flink community for making 2016 a great year!