When Flink & Pulsar Come Together
May 3, 2019 - Sijie Guo (@sijieg)The open source data technology frameworks Apache Flink and Apache Pulsar can integrate in different ways to provide elastic data processing at large scale. I recently gave a talk at Flink Forward San Francisco 2019 and presented some of the integrations between the two frameworks for batch and streaming applications. In this post, I will give a short introduction to Apache Pulsar and its differentiating elements from other messaging systems and describe the ways that Pulsar and Flink can work together to provide a seamless developer experience for elastic data processing at scale.
A brief introduction to Apache Pulsar #
Apache Pulsar is an open-source distributed pub-sub messaging system under the stewardship of the Apache Software Foundation. Pulsar is a multi-tenant, high-performance solution for server-to-server messaging including multiple features such as native support for multiple clusters in a Pulsar instance, with seamless geo-replication of messages across clusters, very low publish and end-to-end latency, seamless scalability to over a million topics, and guaranteed message delivery with persistent message storage provided by Apache BookKeeper among others. Let’s now discuss the primary differentiators between Pulsar and other pub-sub messaging frameworks:
The first differentiating factor stems from the fact that although Pulsar provides a flexible pub-sub messaging system it is also backed by durable log storage — hence combining both messaging and storage under one framework. Because of that layered architecture, Pulsar provides instant failure recovery, independent scalability and balance-free cluster expansion.
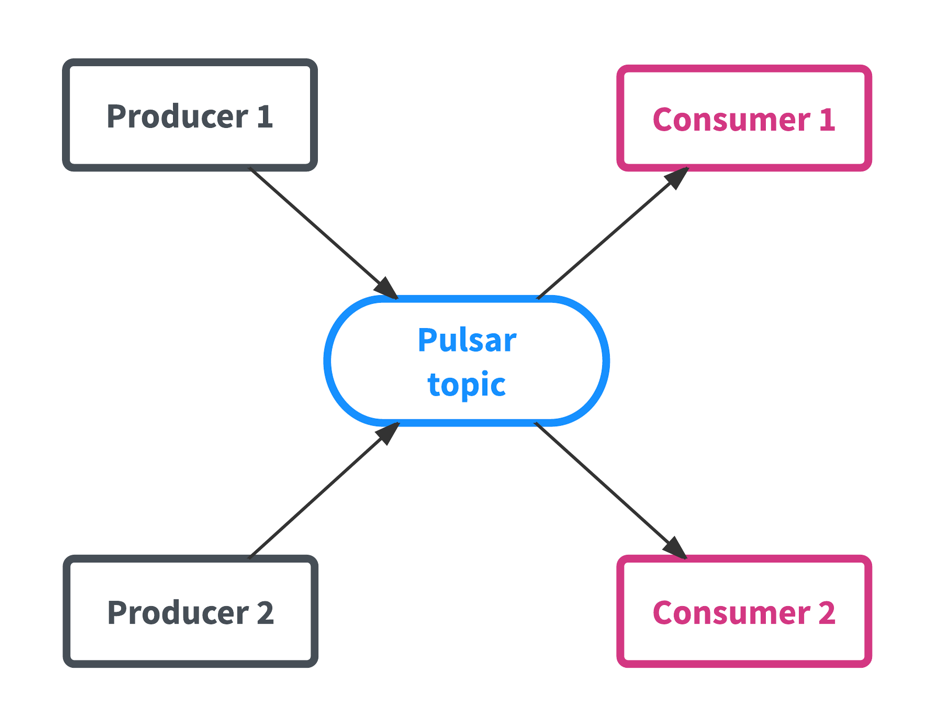
Pulsar’s architecture follows a similar pattern to other pub-sub systems as the framework is organized in topics as the main data entity, with producers sending data to, and consumers receiving data from a topic as shown in the diagram below.
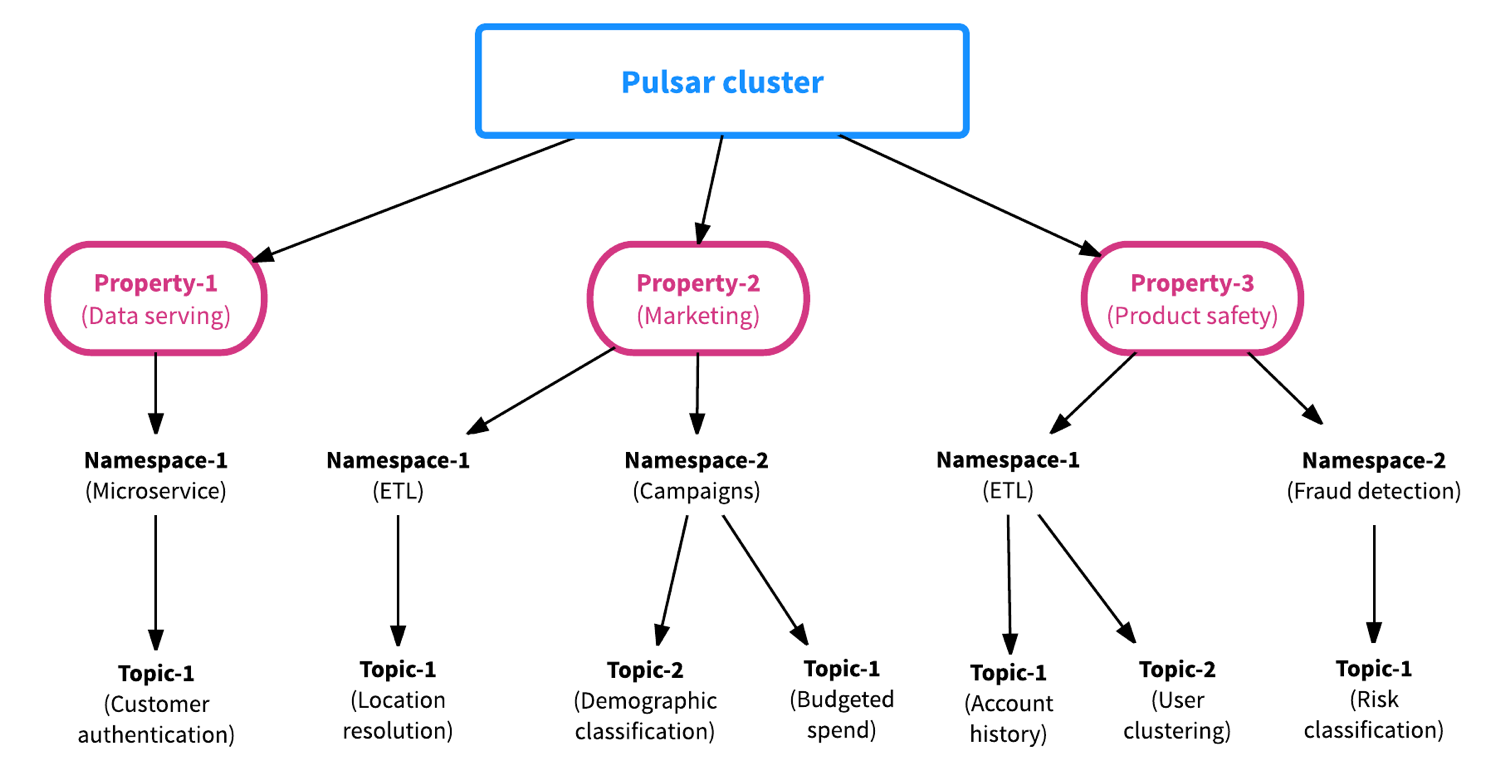
The second differentiator of Pulsar is that the framework is built from the get-go with multi-tenancy in mind. What that means is that each Pulsar topic has a hierarchical management structure making the allocation of resources as well as the resource management and coordination between teams efficient and easy. With Pulsar’s multi-tenancy structure, data platform maintainers can onboard new teams with no friction as Pulsar provides resource isolation at the property (tenant), namespace or topic level, while at the same time data can be shared across the cluster for easy collaboration and coordination.
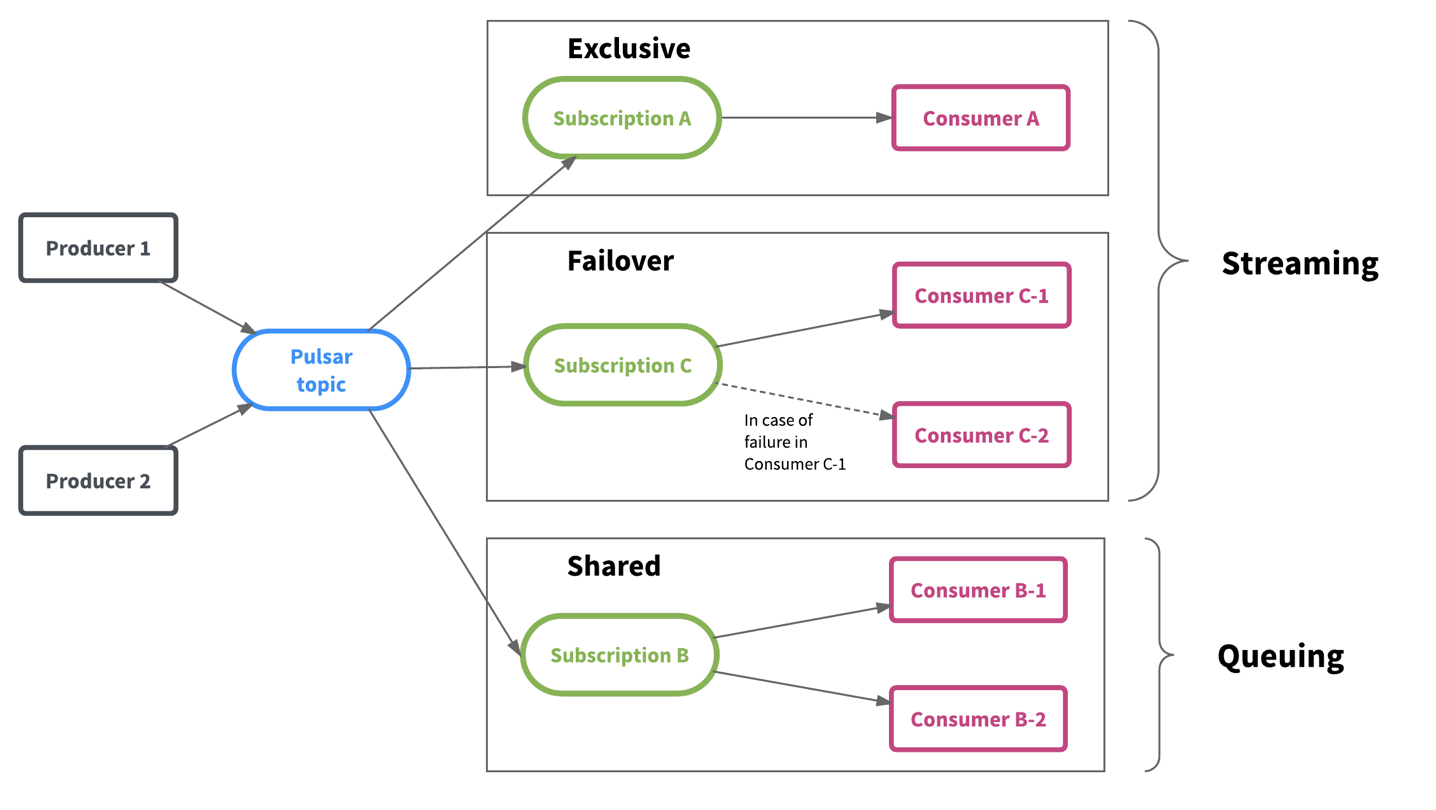
Finally, Pulsar’s flexible messaging framework unifies the streaming and queuing data consumption models and provides greater flexibility. As shown in the below diagram, Pulsar holds the data in the topic while multiple teams can consume the data independently depending on their workloads and data consumption patterns.
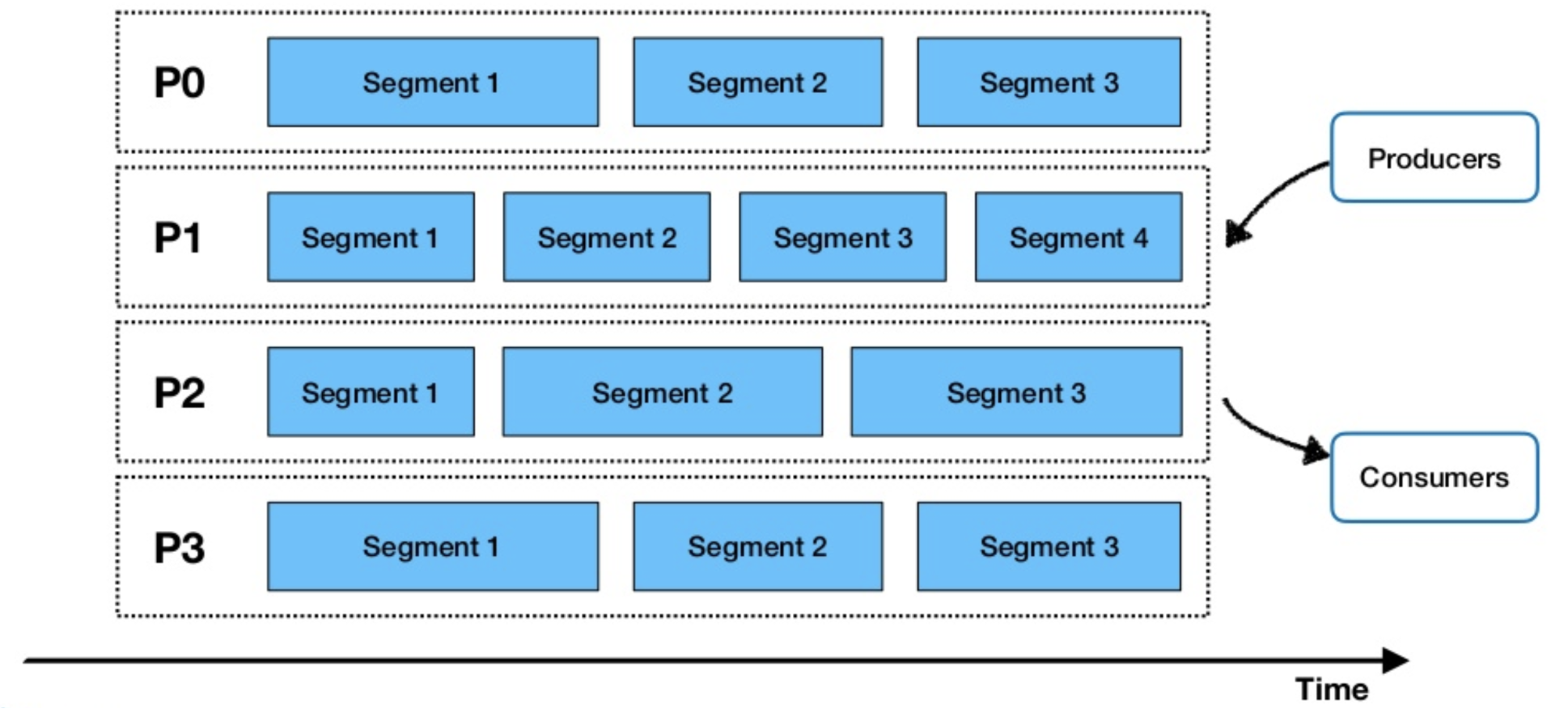
Pulsar’s view on data: Segmented data streams #
Apache Flink is a streaming-first computation framework that perceives batch processing as a special case of streaming. Flink’s view on data streams distinguishes batch and stream processing between bounded and unbounded data streams, assuming that for batch workloads the data stream is finite, with a beginning and an end.
Apache Pulsar has a similar perspective to that of Apache Flink with regards to the data layer. The framework also uses streams as a unified view on all data, while its layered architecture allows traditional pub-sub messaging for streaming workloads and continuous data processing or usage of Segmented Streams and bounded data stream for batch and static workloads.
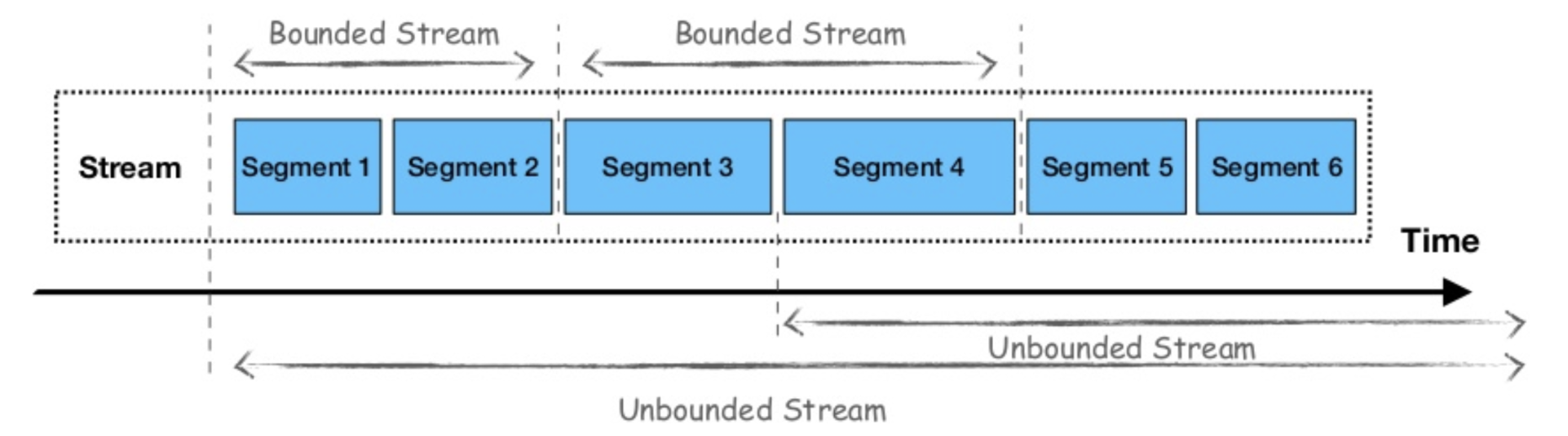
With Pulsar, once a producer sends data to a topic, it is partitioned depending on the data traffic and then further segmented under those partitions — using Apache Bookkeeper as segment store — to allow for parallel data processing as illustrated in the diagram below. This allows a combination of traditional pub-sub messaging and distributed parallel computations in one framework.
When Flink + Pulsar come together #
Apache Flink and Apache Pulsar integrate in multiple ways already. In the following sections, I will present some potential future integrations between the frameworks and share examples of existing ways in which you can utilize the frameworks together.
Potential Integrations #
Pulsar can integrate with Apache Flink in different ways. Some potential integrations include providing support for streaming workloads with the use of Streaming Connectors and support for batch workloads with the use of Batch Source Connectors. Pulsar also comes with native support for schema that can integrate with Flink and provide structured access to the data, for example by using Flink SQL as a way of querying data in Pulsar. Finally, an alternative way of integrating the technologies could include using Pulsar as a state backend with Flink. Since Pulsar has a layered architecture (Streams and Segmented Streams, powered by Apache Bookkeeper), it becomes natural to use Pulsar as a storage layer and store Flink state.
From an architecture point of view, we can imagine the integration between the two frameworks as one that uses Apache Pulsar for a unified view of the data layer and Apache Flink as a unified computation and data processing framework and API.
Existing Integrations #
Integration between the two frameworks is ongoing and developers can already use Pulsar with Flink in multiple ways. For example, Pulsar can be used as a streaming source and streaming sink in Flink DataStream applications. Developers can ingest data from Pulsar into a Flink job that makes computations and processes real-time data, to then send the data back to a Pulsar topic as a streaming sink. Such an example is shown below:
// create and configure Pulsar consumer
PulsarSourceBuilder<String>builder = PulsarSourceBuilder
.builder(new SimpleStringSchema())
.serviceUrl(serviceUrl)
.topic(inputTopic)
.subscriptionName(subscription);
SourceFunction<String> src = builder.build();
// ingest DataStream with Pulsar consumer
DataStream<String> words = env.addSource(src);
// perform computation on DataStream (here a simple WordCount)
DataStream<WordWithCount> wc = words
.flatMap((FlatMapFunction<String, WordWithCount>) (word, collector) -> {
collector.collect(new WordWithCount(word, 1));
})
.returns(WordWithCount.class)
.keyBy("word")
.timeWindow(Time.seconds(5))
.reduce((ReduceFunction<WordWithCount>) (c1, c2) ->
new WordWithCount(c1.word, c1.count + c2.count));
// emit result via Pulsar producer
wc.addSink(new FlinkPulsarProducer<>(
serviceUrl,
outputTopic,
new AuthenticationDisabled(),
wordWithCount -> wordWithCount.toString().getBytes(UTF_8),
wordWithCount -> wordWithCount.word)
);
Another integration between the two frameworks that developers can take advantage of includes using Pulsar as both a streaming source and a streaming table sink for Flink SQL or Table API queries as shown in the example below:
// obtain a DataStream with words
DataStream<String> words = ...
// register DataStream as Table "words" with two attributes ("word", "ts").
// "ts" is an event-time timestamp.
tableEnvironment.registerDataStream("words", words, "word, ts.rowtime");
// create a TableSink that produces to Pulsar
TableSink sink = new PulsarJsonTableSink(
serviceUrl,
outputTopic,
new AuthenticationDisabled(),
ROUTING_KEY);
// register Pulsar TableSink as table "wc"
tableEnvironment.registerTableSink(
"wc",
sink.configure(
new String[]{"word", "cnt"},
new TypeInformation[]{Types.STRING, Types.LONG}));
// count words per 5 seconds and write result to table "wc"
tableEnvironment.sqlUpdate(
"INSERT INTO wc " +
"SELECT word, COUNT(*) AS cnt " +
"FROM words " +
"GROUP BY word, TUMBLE(ts, INTERVAL '5' SECOND)");
Finally, Flink integrates with Pulsar for batch workloads as a batch sink where all results get pushed to Pulsar after Apache Flink has completed the computation in a static data set. Such an example is shown below:
// obtain DataSet from arbitrary computation
DataSet<WordWithCount> wc = ...
// create PulsarOutputFormat instance
OutputFormat pulsarOutputFormat = new PulsarOutputFormat(
serviceUrl,
topic,
new AuthenticationDisabled(),
wordWithCount -> wordWithCount.toString().getBytes());
// write DataSet to Pulsar
wc.output(pulsarOutputFormat);
Conclusion #
Both Pulsar and Flink share a similar view on how the data and the computation level of an application can be “streaming-first” with batch as a special case streaming. With Pulsar’s Segmented Streams approach and Flink’s steps to unify batch and stream processing workloads under one framework, there are numerous ways of integrating the two technologies together to provide elastic data processing at massive scale. Subscribe to the Apache Flink and Apache Pulsar mailing lists to stay up-to-date with the latest developments in this space or share your thoughts and recommendations with both communities.