Apache Flink 1.9.0 Release Announcement
August 22, 2019 -The Apache Flink community is proud to announce the release of Apache Flink 1.9.0.
The Apache Flink project’s goal is to develop a stream processing system to unify and power many forms of real-time and offline data processing applications as well as event-driven applications. In this release, we have made a huge step forward in that effort, by integrating Flink’s stream and batch processing capabilities under a single, unified runtime.
Significant features on this path are batch-style recovery for batch jobs and a preview of the new Blink-based query engine for Table API and SQL queries. We are also excited to announce the availability of the State Processor API, which is one of the most frequently requested features and enables users to read and write savepoints with Flink DataSet jobs. Finally, Flink 1.9 includes a reworked WebUI and previews of Flink’s new Python Table API and its integration with the Apache Hive ecosystem.
This blog post describes all major new features and improvements, important changes to be aware of and what to expect moving forward. For more details, check the complete release changelog.
The binary distribution and source artifacts for this release are now
available via the Downloads page of
the Flink project, along with the updated
documentation.
Flink 1.9 is API-compatible with previous 1.x releases for APIs annotated with
the @Public annotation.
Please feel encouraged to download the release and share your thoughts with the community through the Flink mailing lists or JIRA. As always, feedback is very much appreciated!
New Features and Improvements #
Fine-grained Batch Recovery (FLIP-1) #
The time to recover a batch (DataSet, Table API and SQL) job from a task
failure was significantly reduced. Until Flink 1.9, task failures in batch
jobs were recovered by canceling all tasks and restarting the whole job, i.e,
the job was started from scratch and all progress was voided. With this
release, Flink can be configured to limit the recovery to only those tasks
that are in the same failover region. A failover region is the set of
tasks that are connected via pipelined data exchanges. Hence, the
batch-shuffle connections of a job define the boundaries of its failover
regions. More details are available in
FLIP-1.

To use this new failover strategy, you need to do the following settings:
- Make sure you have the entry
jobmanager.execution.failover-strategy: regionin yourflink-conf.yaml.
Note: The configuration of the 1.9 distribution has that entry by default, but when reusing a configuration file from previous setups, you have to add it manually.
Moreover, you need to set the ExecutionMode of batch jobs in the
ExecutionConfig to BATCH to configure that data shuffles are not pipelined
and jobs have more than one failover region.
The “Region” failover strategy also improves the recovery of “embarrassingly parallel” streaming jobs, i.e., jobs without any shuffle like keyBy() or rebalance. When such a job is recovered, only the tasks of the affected pipeline (failover region) are restarted. For all other streaming jobs, the recovery behavior is the same as in prior Flink versions.
State Processor API (FLIP-43) #
Up to Flink 1.9, accessing the state of a job from the outside was limited to the (still) experimental Queryable State. This release introduces a new, powerful library to read, write and modify state snapshots using the batch DataSet API. In practice, this means:
- Flink job state can be bootstrapped by reading data from external systems, such as external databases, and converting it into a savepoint.
- State in savepoints can be queried using any of Flink’s batch APIs (DataSet, Table, SQL), for example to analyze relevant state patterns or check for discrepancies in state that can support application auditing or troubleshooting.
- The schema of state in savepoints can be migrated offline, compared to the previous approach requiring online migration on schema access.
- Invalid data in savepoints can be identified and corrected.
The new State Processor API covers all variations of snapshots: savepoints, full checkpoints and incremental checkpoints. More details are available in FLIP-43
Stop-with-Savepoint (FLIP-34) #
Cancelling with a
savepoint
is a common operation for stopping/restarting, forking or updating Flink jobs.
However, the existing implementation did not guarantee output persistence to
external storage systems for exactly-once sinks. To improve the end-to-end
semantics when stopping a job, Flink 1.9 introduces a new SUSPEND mode to
stop a job with a savepoint that is consistent with the emitted data.
You can suspend a job with Flink’s CLI client as follows:
bin/flink stop -p [:targetDirectory] :jobId
The final job state is set to FINISHED on success, allowing
users to detect failures of the requested operation.
More details are available in FLIP-34
Flink WebUI Rework #
After a discussion about modernizing the internals of Flink’s WebUI, this component was reconstructed using the latest stable version of Angular — basically, a bump from Angular 1.x to 7.x. The redesigned version is the default in 1.9.0, however there is a link to switch to the old WebUI.
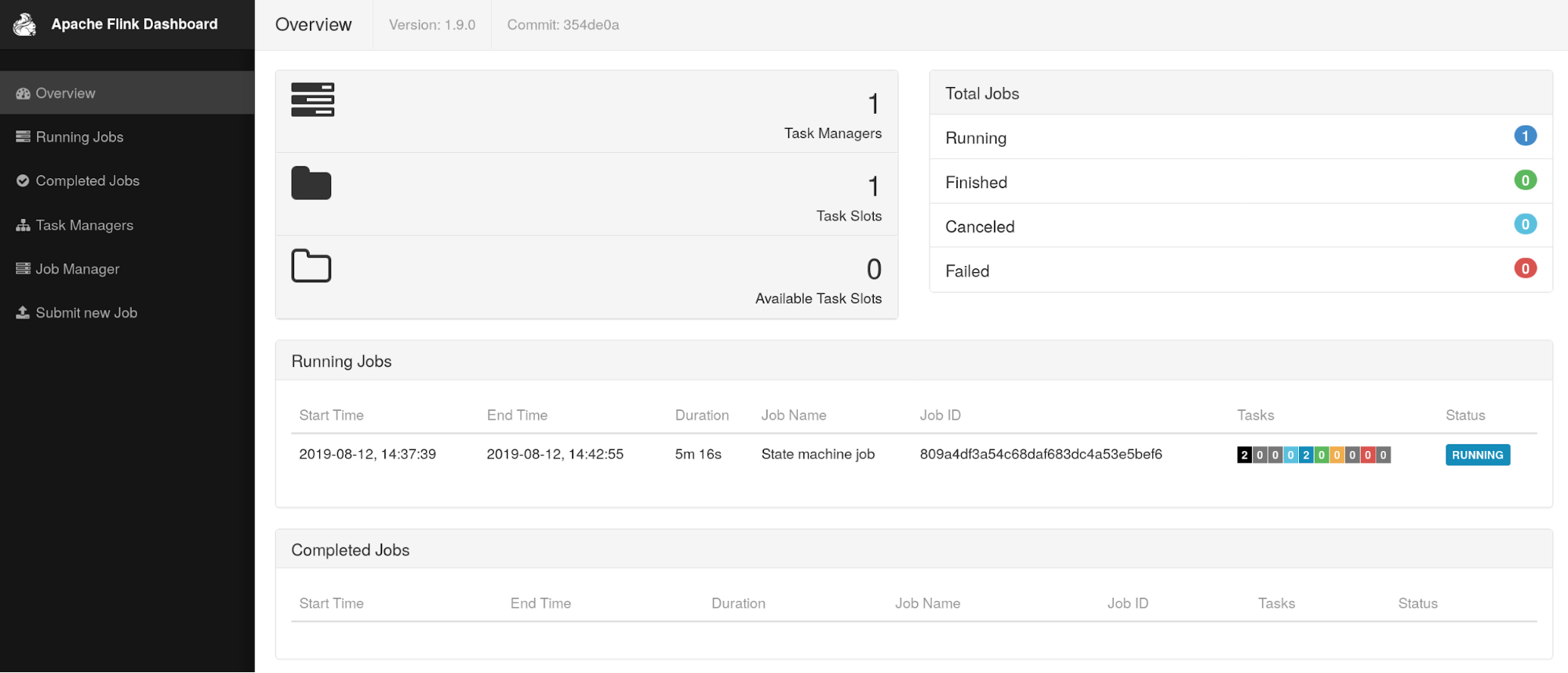
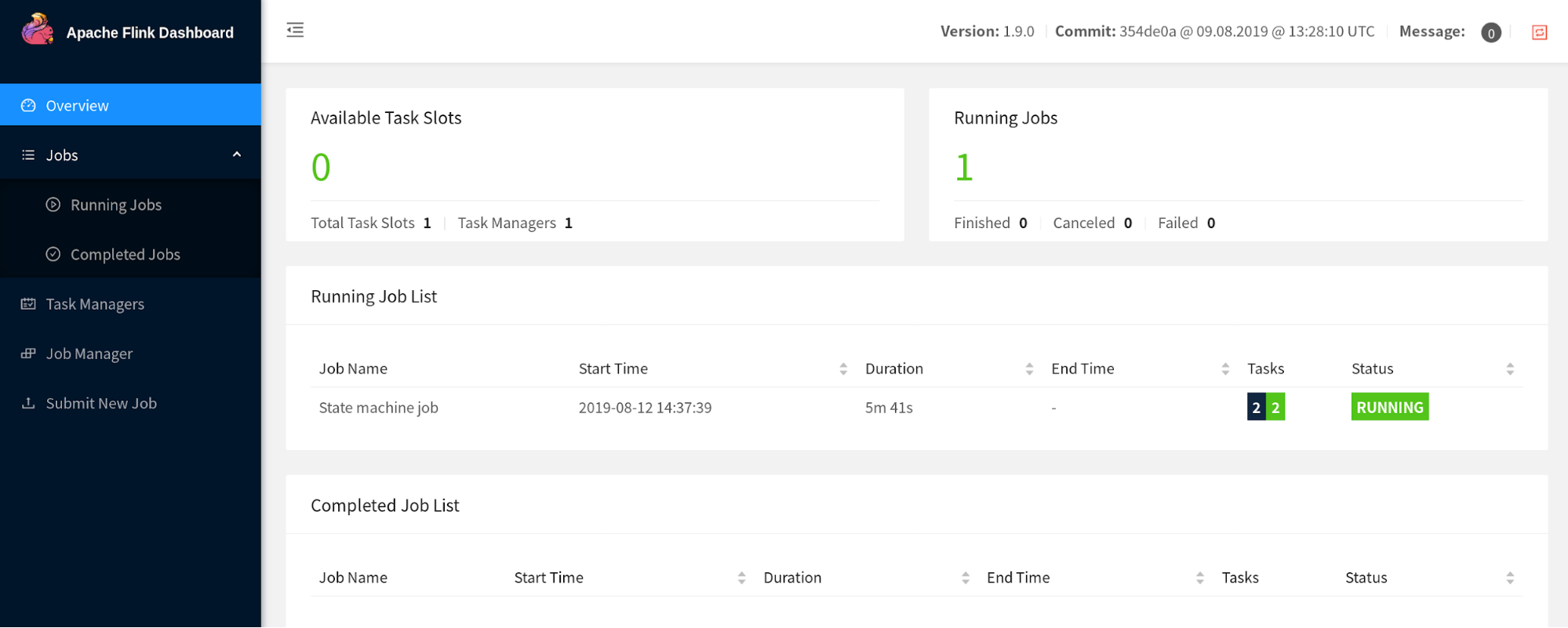
Note: Moving forward, feature parity for the old version of the WebUI will not be guaranteed.
Preview of the new Blink SQL Query Processor #
Following the donation of
Blink to
Apache Flink, the community worked on integrating Blink’s query optimizer and
runtime for the Table API and SQL. As a first step, we refactored the
monolithic flink-table module into smaller modules
(FLIP-32).
This resulted in a clear separation of and well-defined interfaces between the
Java and Scala API modules and the optimizer and runtime modules.
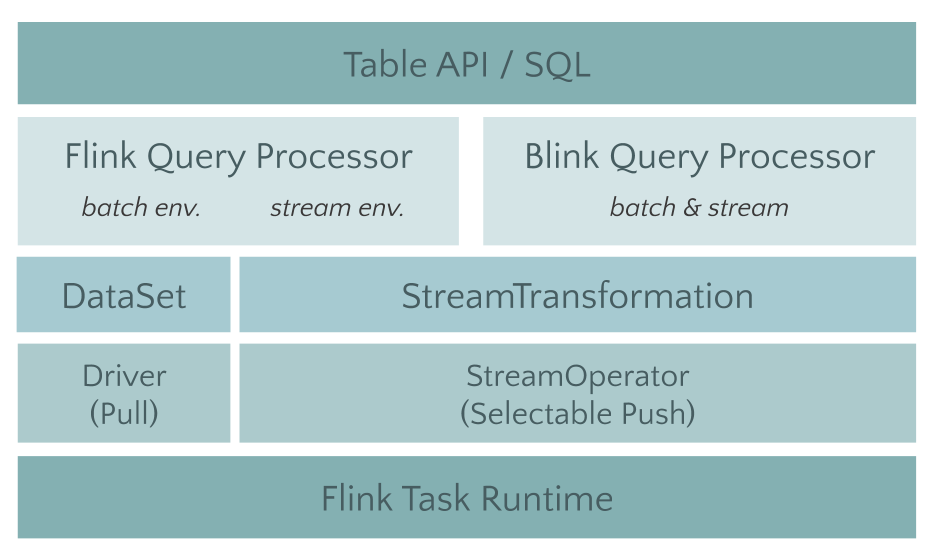
Next, we extended Blink’s planner to implement the new optimizer interface such that there are now two pluggable query processors to execute Table API and SQL statements: the pre-1.9 Flink processor and the new Blink-based query processor. The Blink-based query processor offers better SQL coverage (full TPC-H coverage in 1.9, TPC-DS coverage is planned for the next release) and improved performance for batch queries as the result of more extensive query optimization (cost-based plan selection and more optimization rules), improved code-generation, and tuned operator implementations. The Blink-based query processor also provides a more powerful streaming runner, with some new features (e.g. dimension table join, TopN, deduplication) and optimizations to solve data-skew in aggregation and more useful built-in functions.
Note: The semantics and set of supported operations of the query processors are mostly, but not fully aligned.
However, the integration of Blink’s query processor is not fully completed
yet. Therefore, the pre-1.9 Flink processor is still the default processor in
Flink 1.9 and recommended for production settings. You can enable the Blink
processor by configuring it via the EnvironmentSettings when creating a
TableEnvironment. The selected processor must be on the classpath of the
executing Java process. For cluster setups, both query processors are
automatically loaded with the default configuration. When running a query from
your IDE you need to explicitly add a planner
dependency
to your project.
Other Improvements to the Table API and SQL #
Besides the exciting progress around the Blink planner, the community worked on a whole set of other improvements to these interfaces, including:
-
Scala-free Table API and SQL for Java users (FLIP-32)
As part of the refactoring and splitting of the flink-table module, two separate API modules for Java and Scala were created. For Scala users, nothing really changes, but Java users can use the Table API and/or SQL now without pulling in a Scala dependency.
-
Rework of the Table API Type System (FLIP-37)
The community implemented a new data type system to detach the Table API from Flink’s TypeInformation class and improve its compliance with the SQL standard. This is still a work in progress and expected to be completed in the next release. In Flink 1.9, UDFs are―among other things―not ported to the new type system yet.
-
Multi-column and Multi-row Transformations for Table API (FLIP-29)
The functionality of the Table API was extended with a set of transformations that support multi-row and/or multi-column inputs and outputs. These transformations significantly ease the implementation of processing logic that would be cumbersome to implement with relational operators.
-
New, Unified Catalog APIs (FLIP-30)
We reworked the catalog APIs to store metadata and unified the handling of internal and external catalogs. This effort was mainly initiated as a prerequisite for the Hive integration (see below), but improves the overall convenience of managing catalog metadata in Flink. Besides improving the catalog interfaces, we also extended their functionality. Previously table definitions for Table API or SQL queries were volatile. With Flink 1.9, the metadata of tables which are registered with a SQL DDL statement can be persisted in a catalog. This means you can add a table that is backed by a Kafka topic to a Metastore catalog and from then on query this table whenever your catalog is connected to Metastore.
-
DDL Support in the SQL API (FLINK-10232)
Up to this point, Flink SQL only supported DML statements (e.g.
SELECT,INSERT). External tables (table sources and sinks) had to be registered via Java/Scala code or configuration files. For 1.9, we added support for SQL DDL statements to register and remove tables and views (CREATE TABLE, DROP TABLE). However, we did not add stream-specific syntax extensions to define timestamp extraction and watermark generation, yet. Full support for streaming use cases is planned for the next release.
Preview of Full Hive Integration (FLINK-10556) #
Apache Hive is widely used in Hadoop’s ecosystem to store and query large amounts of structured data. Besides being a query processor, Hive features a catalog called Metastore to manage and organize large datasets. A common integration point for query processors is to integrate with Hive’s Metastore in order to be able to tap into the data managed by Hive.
Recently, the community started implementing an external catalog for Flink’s Table API and SQL that connects to Hive’s Metastore. In Flink 1.9, users will be able to query and process all data that is stored in Hive. As described earlier, you will also be able to persist metadata of Flink tables in Metastore. Moreover, the Hive integration includes support to use Hive’s UDFs in Flink Table API or SQL queries. More details are available in FLINK-10556.
While, previously, table definitions for Table API or SQL queries were always volatile, the new catalog connector additionally allows persisting a table in Metastore that is created with a SQL DDL statement (see above). This means that you connect to Metastore and register a table that is, for example, backed by a Kafka topic. From now on, you can query that table whenever your catalog is connected to Metastore.
Please note that the Hive support in Flink 1.9 is experimental. We are planning to stabilize these features for the next release and are looking forward to your feedback.
Preview of the new Python Table API (FLIP-38) #
This release also introduces a first version of a Python Table API (FLIP-38). This marks the start towards our goal of bringing full-fledged Python support to Flink. The feature was designed as a slim Python API wrapper around the Table API, basically translating Python Table API method calls into Java Table API calls. In the initial version that ships with Flink 1.9, the Python Table API does not support UDFs yet, but just standard relational operations. Support for UDFs implemented in Python is on the roadmap for future releases.
If you’d like to try the new Python API, you have to manually install
PyFlink.
From there, you can have a look at this
walkthrough
or explore it on your own. The community is currently
working
on preparing a pyflink Python package that will be made available for
installation via pip.
Important Changes #
- The Table API and SQL are now part of the default configuration of the Flink distribution. Before, the Table API and SQL had to be enabled by moving the corresponding JAR file from ./opt to ./lib.
- The machine learning library (flink-ml) has been removed in preparation for FLIP-39.
- The old DataSet and DataStream Python APIs have been removed in favor of FLIP-38.
- Flink can be compiled and run on Java 9. Note that certain components interacting with external systems (connectors, filesystems, reporters) may not work since the respective projects may have skipped Java 9 support.
Release Notes #
Please review the release notes for a more detailed list of changes and new features if you plan to upgrade your Flink setup to Flink 1.9.0.
List of Contributors #
We would like to thank all contributors who have made this release possible:
Abdul Qadeer (abqadeer), Aitozi, Alberto Romero, Aleksey Pak, Alexander Fedulov, Alice Yan, Aljoscha Krettek, Aloys, Andrew Duffy, Andrey Zagrebin, Ankur, Artsem Semianenka, Benchao Li, Biao Liu, Bo WANG, Bowen L, Chesnay Schepler, Clark Yang, Congxian Qiu, Cristian, Danny Chan, David Moravek, Dawid Wysakowicz, Dian Fu, EronWright, Fabian Hueske, Fabio Lombardelli, Fokko Driesprong, Gao Yun, Gary Yao, Gen Luo, Gyula Fora, Hequn Cheng, Hongtao Zhang, Huang Xingbo, HuangXingBo, Hugo Da Cruz Louro, Humberto Rodríguez A, Hwanju Kim, Igal Shilman, Jamie Grier, Jark Wu, Jason, Jasper Yue, Jeff Zhang, Jiangjie (Becket) Qin, Jiezhi.G, Jincheng Sun, Jing Zhang, Jingsong Lee, Juan Gentile, Jungtaek Lim, Kailash Dayanand, Kevin Bohinski, Konstantin Knauf, Konstantinos Papadopoulos, Kostas Kloudas, Kurt Young, Lakshmi, Lakshmi Gururaja Rao, Leeviiii, LouisXu, Maximilian Michels, Nico Kruber, Niels Basjes, Paul Lam, PengFei Li, Peter Huang, Pierre Zemb, Piotr Nowojski, Piyush Narang, Richard Deurwaarder, Robert Metzger, Robert Stoll, Romano Vacca, Rong Rong, Rui Li, Ryantaocer, Scott Mitchell, Seth Wiesman, Shannon Carey, Shimin Yang, Stefan Richter, Stephan Ewen, Stephen Connolly, Steven Wu, SuXingLee, TANG Wen-hui, Thomas Weise, Till Rohrmann, Timo Walther, Tom Goong, TsReaper, Tzu-Li (Gordon) Tai, Ufuk Celebi, Victor Wong, WangHengwei, Wei Zhong, WeiZhong94, Xintong Song, Xpray, XuQianJin-Stars, Xuefu Zhang, Xupingyong, Yangze Guo, Yu Li, Yun Gao, Yun Tang, Zhanchun Zhang, Zhenghua Gao, Zhijiang, Zhu Zhu, Zili Chen, aloys, arganzheng, azagrebin, bd2019us, beyond1920, biao.liub, blueszheng, boshu Zheng, chenqi, chummyhe89, chunpinghe, dcadmin, dianfu, godfrey he, guanghui01.rong, hehuiyuan, hello, hequn8128, jackyyin, joongkeun.yang, klion26, lamber-ken, leesf, liguowei, lincoln-lil, liyafan82, luoqi, mans2singh, maqingxiang, maxin, mjl, okidogi, ozan, potseluev, qiangsi.lq, qiaoran, robbinli, shaoxuan-wang, shengqian.zhou, shenlang.sl, shuai-xu, sunhaibotb, tianchen, tianchen92, tison, tom_gong, vinoyang, vthinkxie, wanggeng3, wenhuitang, winifredtamg, xl38154, xuyang1706, yangfei5, yanghua, yuzhao.cyz, zhangxin516, zhangxinxing, zhaofaxian, zhijiang, zjuwangg, 林小铂, 黄培松, 时无两丶.