How to query Pulsar Streams using Apache Flink
November 25, 2019 - Sijie Guo (@sijieg) Markos Sfikas (@MarkSfik)In a previous story on the Flink blog, we explained the different ways that Apache Flink and Apache Pulsar can integrate to provide elastic data processing at large scale. This blog post discusses the new developments and integrations between the two frameworks and showcases how you can leverage Pulsar’s built-in schema to query Pulsar streams in real time using Apache Flink.
A short intro to Apache Pulsar #
Apache Pulsar is a flexible pub/sub messaging system, backed by durable log storage. Some of the framework’s highlights include multi-tenancy, a unified message model, structured event streams and a cloud-native architecture that make it a perfect fit for a wide set of use cases, ranging from billing, payments and trading services all the way to the unification of the different messaging architectures in an organization. If you are interested in finding out more about Pulsar, you can visit the Apache Pulsar documentation or get in touch with the Pulsar community on Slack.
Existing Pulsar & Flink integration (Apache Flink 1.6+) #
The existing integration between Pulsar and Flink exploits Pulsar as a message queue in a Flink application. Flink developers can utilize Pulsar as a streaming source and streaming sink for their Flink applications by selecting a specific Pulsar source and connecting to their desired Pulsar cluster and topic:
// create and configure Pulsar consumer
PulsarSourceBuilder<String>builder = PulsarSourceBuilder
.builder(new SimpleStringSchema())
.serviceUrl(serviceUrl)
.topic(inputTopic)
.subsciptionName(subscription);
SourceFunction<String> src = builder.build();
// ingest DataStream with Pulsar consumer
DataStream<String> words = env.addSource(src);
Pulsar streams can then get connected to the Flink processing logic…
// perform computation on DataStream (here a simple WordCount)
DataStream<WordWithCount> wc = words
.flatmap((FlatMapFunction<String, WordWithCount>) (word, collector) -> {
collector.collect(new WordWithCount(word, 1));
})
.returns(WordWithCount.class)
.keyBy("word")
.timeWindow(Time.seconds(5))
.reduce((ReduceFunction<WordWithCount>) (c1, c2) ->
new WordWithCount(c1.word, c1.count + c2.count));
…and then get emitted back to Pulsar (used now as a sink), sending one’s computation results downstream, back to a Pulsar topic:
// emit result via Pulsar producer
wc.addSink(new FlinkPulsarProducer<>(
serviceUrl,
outputTopic,
new AuthentificationDisabled(),
wordWithCount -> wordWithCount.toString().getBytes(UTF_8),
wordWithCount -> wordWithCount.word)
);
Although this is a great first integration step, the existing design is not leveraging the full power of Pulsar. Some shortcomings of the integration with Flink 1.6.0 relate to Pulsar neither being utilized as durable storage nor having schema integration with Flink, resulting in manual input when describing an application’s schema registry.
Pulsar’s integration with Flink 1.9: Using Pulsar as a Flink catalog #
The latest integration between Flink 1.9.0 and Pulsar addresses most of the previously mentioned shortcomings. The contribution of Alibaba’s Blink to the Flink repository adds many enhancements and new features to the processing framework that make the integration with Pulsar significantly more powerful and impactful. Flink 1.9.0 brings Pulsar schema integration into the picture, makes the Table API a first-class citizen and provides an exactly-once streaming source and at-least-once streaming sink with Pulsar. Lastly, with schema integration, Pulsar can now be registered as a Flink catalog, making running Flink queries on top of Pulsar streams a matter of a few commands. In the following sections, we will take a closer look at the new integrations and provide examples of how to query Pulsar streams using Flink SQL.
Leveraging the Flink <> Pulsar Schema Integration #
Before delving into the integration details and how you can use Pulsar schema with Flink, let us describe how schema in Pulsar works. Schema in Apache Pulsar already co-exists and serves as the representation of the data on the broker side of the framework, something that makes schema registry with external systems obsolete. Additionally, the data schema in Pulsar is associated with each topic so both producers and consumers send data with predefined schema information, while the broker performs schema validation, and manages schema multi-versioning and evolution in compatibility checks.
Below you can find an example of Pulsar’s schema on both the producer and consumer side. On the producer side, you can specify which schema you want to use and Pulsar then sends a POJO class without the need to perform any serialization/deserialization. Similarly, on the consumer end, you can also specify the data schema and upon receiving the data, Pulsar will automatically validate the schema information, fetch the schema of the given version and then deserialize the data back to a POJO structure. Pulsar stores the schema information in the metadata of a Pulsar topic.
// Create producer with Struct schema and send messages
Producer<User> producer = client.newProducer(Schema.AVRO(User.class)).create();
producer.newMessage()
.value(User.builder()
.userName(“pulsar-user”)
.userId(1L)
.build())
.send();
// Create consumer with Struct schema and receive messages
Consumer<User> consumer = client.newCOnsumer(Schema.AVRO(User.class)).create();
consumer.receive();
Let’s assume we have an application that specifies a schema to the producer and/or consumer. Upon receiving the schema information, the producer (or consumer) — that is connected to the broker — will transfer such information so that the broker can then perform schema registration, validations and schema compatibility checks before returning or rejecting the schema as illustrated in the diagram below:
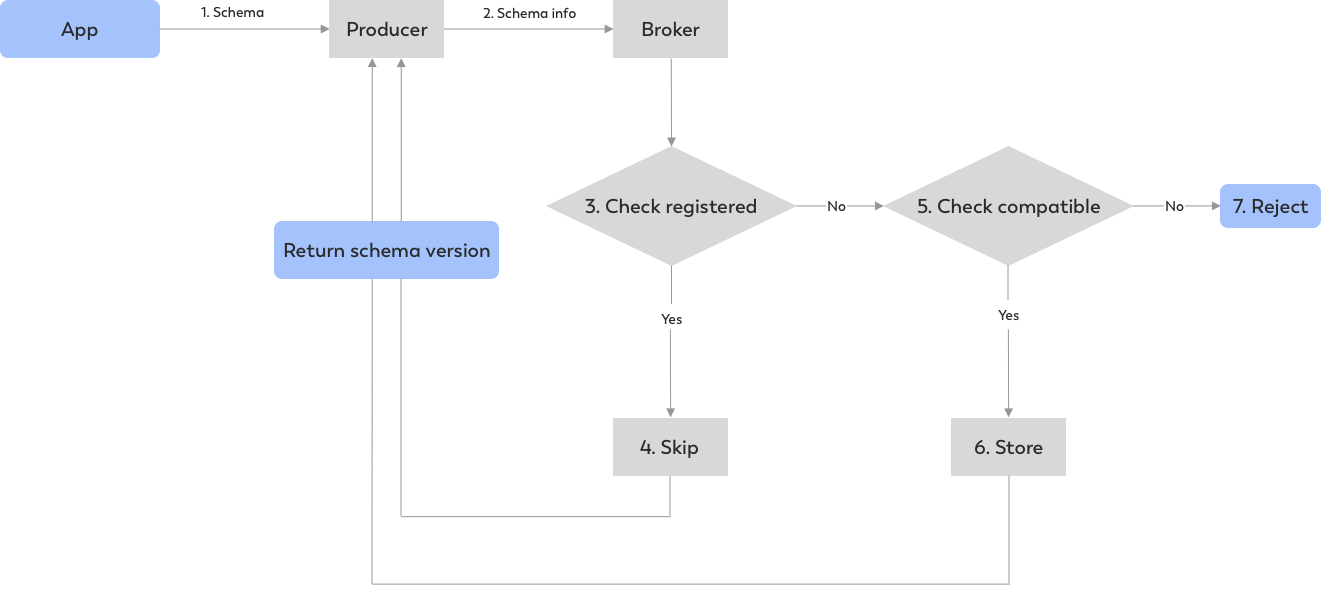
Not only is Pulsar able to handle and store the schema information, but is additionally able to handle any schema evolution — where necessary. Pulsar will effectively manage any schema evolution in the broker, keeping track of all different versions of your schema while performing any necessary compatibility checks.
Moreover, when messages are published on the producer side, Pulsar will tag each message with the schema version as part of each message’s metadata. On the consumer side, when the message is received and the metadata is deserialized, Pulsar will check the schema version associated with this message and will fetch the corresponding schema information from the broker. As a result, when Pulsar integrates with a Flink application it uses the pre-existing schema information and maps individual messages with schema information to a different row in Flink’s type system.
For the cases when Flink users do not interact with schema directly or make use of primitive schema (for example, using a topic to store a string or long number), Pulsar will either convert the message payload into a Flink row, called ‘value’ or — for the cases of structured schema types, like JSON and AVRO — Pulsar will extract the individual fields from the schema information and will map the fields to Flink’s type system. Finally, all metadata information associated with each message, such as the message key, topic, publish time, or event time will be converted into metadata fields in a Flink row. Below we provide two examples of primitive schema and structured schema types and how these will be transformed from a Pulsar topic to Flink’s type system.

Once all the schema information is mapped to Flink’s type system, you can start building a Pulsar source, sink or catalog in Flink based on the specified schema information as illustrated below:
Flink & Pulsar: Read data from Pulsar #
- Create a Pulsar source for streaming queries
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("service.url", "pulsar://...")
props.setProperty("admin.url", "http://...")
props.setProperty("partitionDiscoveryIntervalMillis", "5000")
props.setProperty("startingOffsets", "earliest")
props.setProperty("topic", "test-source-topic")
val source = new FlinkPulsarSource(props)
// you don't need to provide a type information to addSource since FlinkPulsarSource is ResultTypeQueryable
val dataStream = env.addSource(source)(null)
// chain operations on dataStream of Row and sink the output
// end method chaining
env.execute()
- Register topics in Pulsar as streaming tables
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = StreamTableEnvironment.create(env)
val prop = new Properties()
prop.setProperty("service.url", serviceUrl)
prop.setProperty("admin.url", adminUrl)
prop.setProperty("flushOnCheckpoint", "true")
prop.setProperty("failOnWrite", "true")
props.setProperty("topic", "test-sink-topic")
tEnv
.connect(new Pulsar().properties(props))
.inAppendMode()
.registerTableSource("sink-table")
val sql = "INSERT INTO sink-table ....."
tEnv.sqlUpdate(sql)
env.execute()
Flink & Pulsar: Write data to Pulsar #
- Create a Pulsar sink for streaming queries
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = .....
val prop = new Properties()
prop.setProperty("service.url", serviceUrl)
prop.setProperty("admin.url", adminUrl)
prop.setProperty("flushOnCheckpoint", "true")
prop.setProperty("failOnWrite", "true")
props.setProperty("topic", "test-sink-topic")
stream.addSink(new FlinkPulsarSink(prop, DummyTopicKeyExtractor))
env.execute()
- Write a streaming table to Pulsar
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = StreamTableEnvironment.create(env)
val prop = new Properties()
prop.setProperty("service.url", serviceUrl)
prop.setProperty("admin.url", adminUrl)
prop.setProperty("flushOnCheckpoint", "true")
prop.setProperty("failOnWrite", "true")
props.setProperty("topic", "test-sink-topic")
tEnv
.connect(new Pulsar().properties(props))
.inAppendMode()
.registerTableSource("sink-table")
val sql = "INSERT INTO sink-table ....."
tEnv.sqlUpdate(sql)
env.execute()
In every instance, Flink developers only need to specify the properties of how Flink will connect to a Pulsar cluster without worrying about any schema registry, or serialization/deserialization actions and register the Pulsar cluster as a source, sink or streaming table in Flink. Once all three elements are put together, Pulsar can then be registered as a catalog in Flink, something that drastically simplifies how you process and query data like, for example, writing a program to query data from Pulsar or using the Table API and SQL to query Pulsar data streams.
Next Steps & Future Integration #
The goal of the integration between Pulsar and Flink is to simplify how developers use the two frameworks to build a unified data processing stack. As we progress from the classical Lamda architectures — where an online, speeding layer is combined with an offline, batch layer to run data computations — Flink and Pulsar present a great combination in providing a truly unified data processing stack. We see Flink as a unified computation engine, handling both online (streaming) and offline (batch) workloads and Pulsar as the unified data storage layer for a truly unified data processing stack that simplifies developer workloads.
There is still a lot of ongoing work and effort from both communities in getting the integration even better, such as a new source API (FLIP-27) that will allow the contribution of the Pulsar connectors to the Flink community as well as a new subscription type called Key_Shared subscription type in Pulsar that will allow efficient scaling of the source parallelism. Additional efforts focus around the provision of end-to-end, exactly-once guarantees (currently available only in the source Pulsar connector, and not the sink Pulsar connector) and more efforts around using Pulsar/BookKeeper as a Flink state backend.
You can find a more detailed overview of the integration work between the two communities in this recording video from Flink Forward Europe 2019 or sign up to the Flink dev mailing list for the latest contribution and integration efforts between Flink and Pulsar.