State Unlocked: Interacting with State in Apache Flink
January 29, 2020 - Seth Wiesman (@sjwiesman)Introduction #
With stateful stream-processing becoming the norm for complex event-driven applications and real-time analytics, Apache Flink is often the backbone for running business logic and managing an organization’s most valuable asset — its data — as application state in Flink.
In order to provide a state-of-the-art experience to Flink developers, the Apache Flink community makes significant efforts to provide the safety and future-proof guarantees organizations need while managing state in Flink. In particular, Flink developers should have sufficient means to access and modify their state, as well as making bootstrapping state with existing data from external systems a piece-of-cake. These efforts span multiple Flink major releases and consist of the following:
- Evolvable state schema in Apache Flink
- Flexibility in swapping state backends, and
- The State processor API, an offline tool to read, write and modify state in Flink
This post discusses the community’s efforts related to state management in Flink, provides some practical examples of how the different features and APIs can be utilized and covers some future ideas for new and improved ways of managing state in Apache Flink.
Stream processing: What is State? #
To set the tone for the remaining of the post, let us first try to explain the very definition of state in stream processing. When it comes to stateful stream processing, state comprises of the information that an application or stream processing engine will remember across events and streams as more realtime (unbounded) and/or offline (bounded) data flow through the system. Most trivial applications are inherently stateful; even the example of a simple COUNT operation, whereby when counting up to 10, you essentially need to remember that you have already counted up to 9.
To better understand how Flink manages state, one can think of Flink like a three-layered state abstraction, as illustrated in the diagram below.
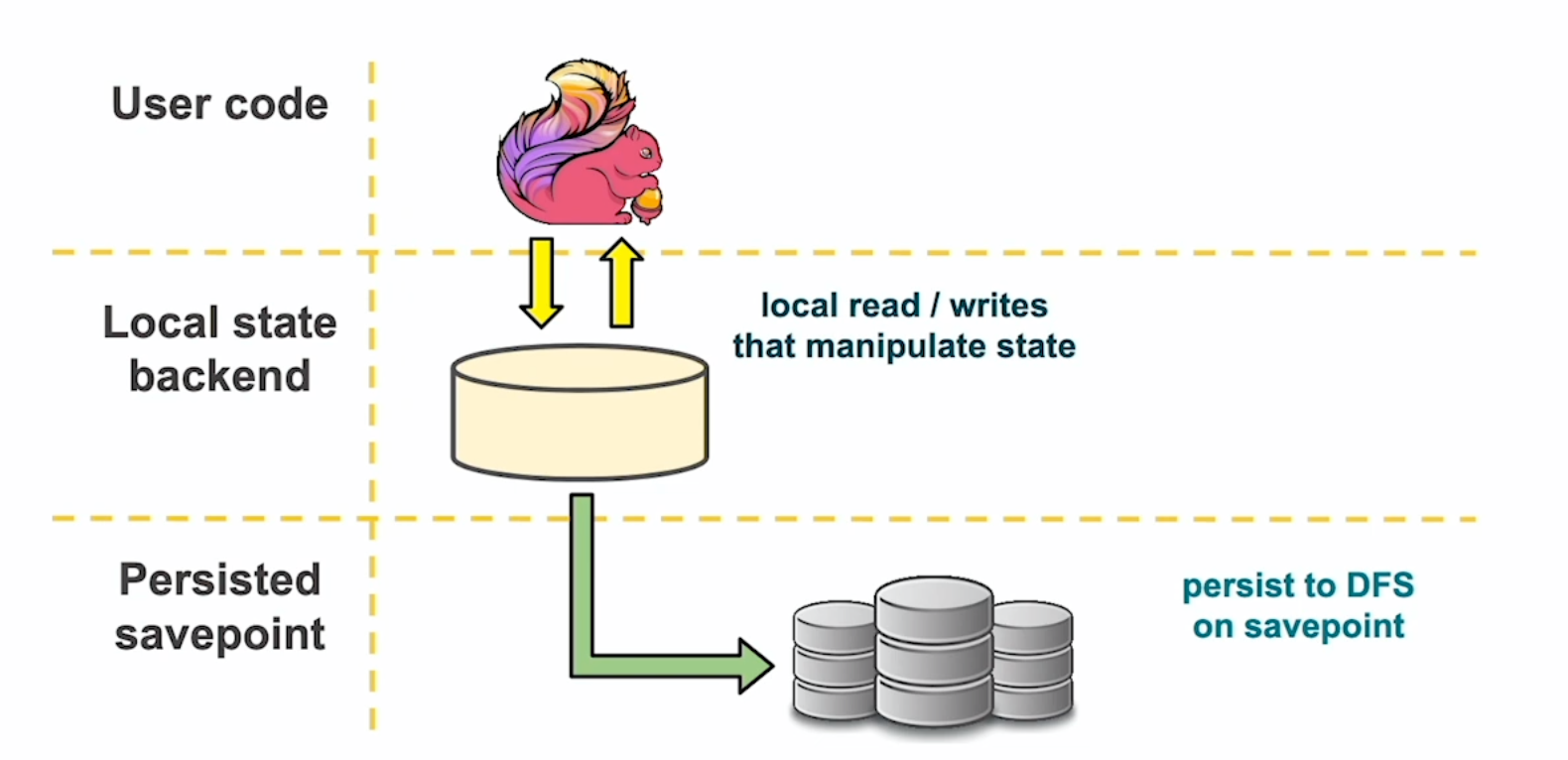
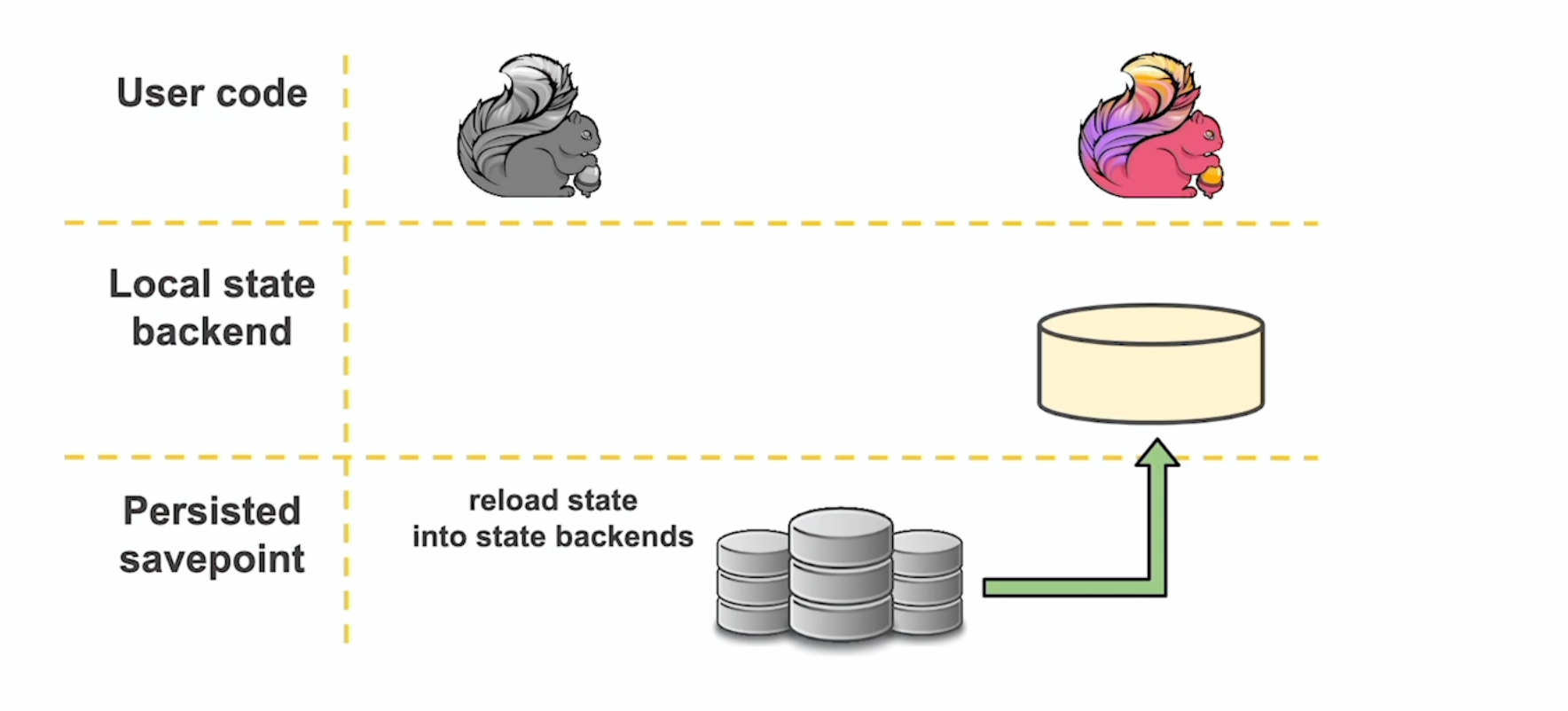
On the top layer, sits the Flink user code, for example, a KeyedProcessFunction that contains some value state. This is a simple variable whose value state annotations makes it automatically fault-tolerant, re-scalable and queryable by the runtime. These variables are backed by the configured state backend that sits either on-heap or on-disk (RocksDB State Backend) and provides data locality, proximity to the computation and speed when it comes to per-record computations. Finally, when it comes to upgrades, the introduction of new features or bug fixes, and in order to keep your existing state intact, this is where savepoints come in.
A savepoint is a snapshot of the distributed, global state of an application at a logical point-in-time and is stored in an external distributed file system or blob storage such as HDFS, or S3. Upon upgrading an application or implementing a code change — such as adding a new operator or changing a field — the Flink job can restart by re-loading the application state from the savepoint into the state backend, making it local and available for the computation and continue processing as if nothing had ever happened.
Schema Evolution with Apache Flink #
In the previous section, we explained how state is stored and persisted in a Flink application. Let’s now take a look at what happens when evolving state in a stateful Flink streaming application becomes necessary.
Imagine an Apache Flink application that implements a KeyedProcessFunction and contains some ValueState. As illustrated below, within the state descriptor, when registering the type, Flink users specify their TypeInformation that informs Flink about how to serialize the bytes and represents Flink’s internal type system, used to serialize data when shipped across the network or stored in state backends. Flink’s type system has built-in support for all the basic types such as longs, strings, doubles, arrays and basic collection types like lists and maps. Additionally, Flink supports most of the major composite types including Tuples, POJOs, Scala Case Classes and Apache AvroⓇ. Finally, if an application’s type does not match any of the above, developers can either plug in their own serializer or Flink will then fall back to Kryo.
State registration with built-in serialization in Apache Flink #
public class MyFunction extends KeyedProcessFunction<Key, Input, Output> {
private transient ValueState<MyState> valueState;
public void open(Configuration parameters) {
ValueStateDescriptor<MyState> descriptor =
new ValueStateDescriptor<>("my-state", TypeInformation.of(MyState.class));
valueState = getRuntimeContext().getState(descriptor);
}
}
Typically, evolving the schema of an application’s state happens because of some business logic change (adding or dropping fields or changing data types). In all cases, the schema is determined by means of its serializer, and can be thought of in terms of an alter table statement when compared with a database. When a state variable is first introduced it is like running a CREATE_TABLE command, there is a lot of freedom with its execution. However, having data in that table (registered rows) limits developers in what they can do and what rules they follow in order to make updates or changes by an ALTER_TABLE statement. Schema migration in Apache Flink follows a similar principle since the framework is essentially running an ALTER_TABLE statement across savepoints.
Flink 1.8 comes with built-in support for Apache Avro (specifically the 1.7.7 specification) and evolves state schema according to Avro specifications by adding and removing types or even by swapping between generic and specific Avro record types.
In Flink 1.9 the community added support for schema evolution for POJOs, including the ability to remove existing fields from POJO types or add new fields. The POJO schema evolution tends to be less flexible — when compared to Avro — since it is not possible to change neither the declared field types nor the class name of a POJO type, including its namespace.
With the community’s efforts related to schema evolution, Flink developers can now expect out-of-the-box support for both Avro and POJO formats, with backwards compatibility for all Flink state backends. Future work revolves around adding support for Scala Case Classes, Tuples and other formats. Make sure to subscribe to the Flink mailing list to contribute and stay on top of any upcoming additions in this space.
Peeking Under the Hood #
Now that we have explained how schema evolution in Flink works, let’s describe the challenges of performing schema serialization with Flink under the hood. Flink considers state as a core part of its API stability, in a way that developers should always be able to take a savepoint from one version of Flink and restart it on the next. With schema evolution, every migration needs to be backwards compatible and also compatible with the different state backends. While in the Flink code the state backends are represented as interfaces detailing how to store and retrieve bytes, in practice, they behave vastly differently, something that adds extra complexity to how schema evolution is executed in Flink.
For instance, the heap state backend supports lazy serialization and eager deserialization, making the per-record code path always working with Java objects, serializing on a background thread. When restoring, Flink will eagerly deserialize all the data and then start the user code. If a developer plugs in a new serializer, the deserialization happens before Flink ever receives the information.
The RocksDB state backend behaves in the exact opposite manner: it supports eager serialization — because of items being stored on disk and RocksDB only consuming byte arrays. RocksDB provides lazy deserialization simply by downloading files to the local disk, making Flink unaware of what the bytes mean until a serializer is registered.
An additional challenge stems from the fact that different versions of user code contain different classes on their classpath making the serializer used to write into a savepoint likely potentially unavailable at runtime.
To overcome the previously mentioned challenges, we introduced what we call TypeSerializerSnapshot. The TypeSerializerSnapshot stores the configuration of the writer serializer in the snapshot. When restoring it will use that configuration to read back the previous state and check its compatibility with the current version. Using such operation allows Flink to:
- Read the configuration used to write out a snapshot
- Consume the new user code
- Check if both items above are compatible
- Consume the bytes from the snapshot and move forward or alert the user otherwise
public interface TypeSerializerSnapshot<T> {
int getCurrentVersion();
void writeSnapshot(DataOutputView out) throws IOException;
void readSnapshot(
int readVersion,
DataInputView in,
ClassLoader userCodeClassLoader) throws IOException;
TypeSerializer<T> restoreSerializer();
TypeSerializerSchemaCompatibility<T> resolveSchemaCompatibility(
TypeSerializer<T> newSerializer);
}
Implementing Apache Avro Serialization in Flink #
Apache Avro is a data serialization format that has very well-defined schema migration semantics and supports both reader and writer schemas. During normal Flink execution the reader and writer schemas will be the same. However, when upgrading an application they may be different and with schema evolution, Flink will be able to migrate objects with their schemas.
public class AvroSerializerSnapshot<T> implements TypeSerializerSnapshot<T> {
private Schema runtimeSchema;
private Schema previousSchema;
@SuppressWarnings("WeakerAccess")
public AvroSerializerSnapshot() { }
AvroSerializerSnapshot(Schema schema) {
this.runtimeSchema = schema;
}
This is a sketch of our Avro serializer. It uses the provided schemas and delegates to Apache Avro for all (de)-serialization. Let’s take a look at one possible implementation of a TypeSerializerSnapshot that supports schema migration for Avro.
Writing out the snapshot #
When serializing out the snapshot, the snapshot configuration will write two pieces of information; the current snapshot configuration version and the serializer configuration.
@Override
public int getCurrentVersion() {
return 1;
}
@Override
public void writeSnapshot(DataOutputView out) throws IOException {
out.writeUTF(runtimeSchema.toString(false));
}
The version is used to version the snapshot configuration object itself while the writeSnapshot method writes out all the information we need to understand the current format; the runtime schema.
@Override
public void readSnapshot(
int readVersion,
DataInputView in,
ClassLoader userCodeClassLoader) throws IOException {
assert readVersion == 1;
final String previousSchemaDefinition = in.readUTF();
this.previousSchema = parseAvroSchema(previousSchemaDefinition);
this.runtimeType = findClassOrFallbackToGeneric(
userCodeClassLoader,
previousSchema.getFullName());
this.runtimeSchema = tryExtractAvroSchema(userCodeClassLoader, runtimeType);
}
Now when Flink restores it is able to read back in the writer schema used to serialize the data. The current runtime schema is discovered on the class path using some Java reflection magic.
Once we have both of these we can compare them for compatibility. Perhaps nothing has changed and the schemas are compatible as is.
@Override
public TypeSerializerSchemaCompatibility<T> resolveSchemaCompatibility(
TypeSerializer<T> newSerializer) {
if (!(newSerializer instanceof AvroSerializer)) {
return TypeSerializerSchemaCompatibility.incompatible();
}
if (Objects.equals(previousSchema, runtimeSchema)) {
return TypeSerializerSchemaCompatibility.compatibleAsIs();
}
Otherwise, the schemas are compared using Avro’s compatibility checks and they may either be compatible with a migration or incompatible.
final SchemaPairCompatibility compatibility = SchemaCompatibility
.checkReaderWriterCompatibility(previousSchema, runtimeSchema);
return avroCompatibilityToFlinkCompatibility(compatibility);
}
If they are compatible with migration then Flink will restore a new serializer that can read the old schema and deserialize into the new runtime type which is in effect a migration.
@Override
public TypeSerializer<T> restoreSerializer() {
if (previousSchema != null) {
return new AvroSerializer<>(runtimeType, runtimeSchema, previousSchema);
} else {
return new AvroSerializer<>(runtimeType, runtimeSchema, runtimeSchema);
}
}
}
The State Processor API: Reading, writing and modifying Flink state #
The State Processor API allows reading from and writing to Flink savepoints. Some of the interesting use cases it can be used for are:
- Analyzing state for interesting patterns
- Troubleshooting or auditing jobs by checking for state discrepancies
- Bootstrapping state for new applications
- Modifying savepoints such as:
- Changing the maximum parallelism of a savepoint after deploying a Flink job
- Introducing breaking schema updates to a Flink application
- Correcting invalid state in a Flink savepoint
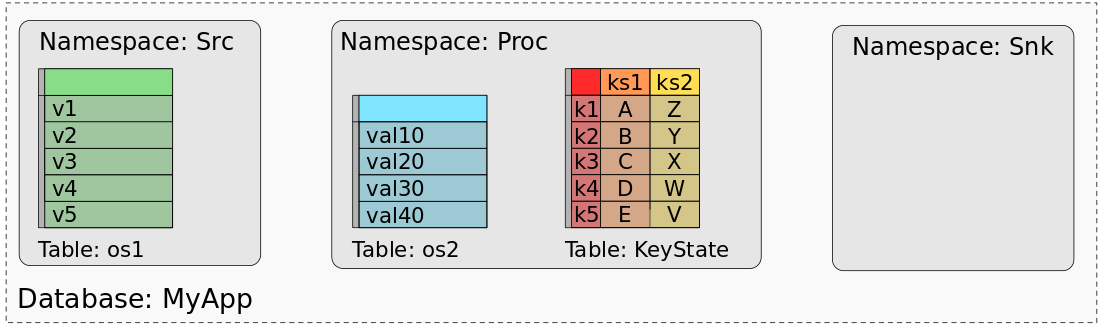
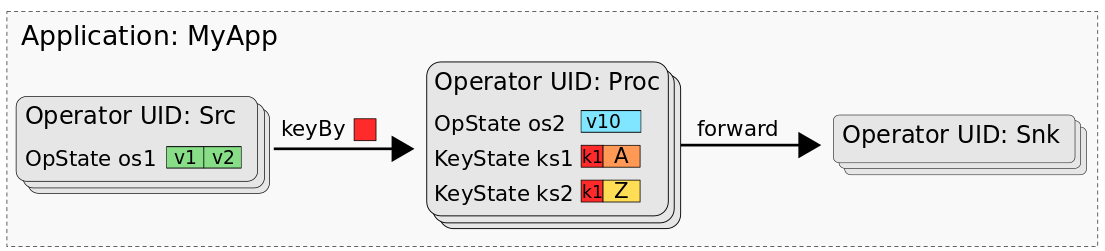
In a previous blog post, we discussed the State Processor API in detail, the community’s motivation behind introducing the feature in Flink 1.9, what you can use the API for and how you can use it. Essentially, the State Processor API is based around a relational model of mapping your Flink job state to a database, as illustrated in the diagram below. We encourage you to read the previous story for more information on the API and how to use it. In a follow up post, we will provide detailed tutorials on:
- Reading Keyed and Operator State with the State Processor API and
- Writing and Bootstrapping Keyed and Operator State with the State Processor API
Stay tuned for more details and guidance around this feature of Flink.
Looking ahead: More ways to interact with State in Flink #
There is a lot of discussion happening in the community related to extending the way Flink developers interact with state in their Flink applications. Regarding the State Processor API, some thoughts revolve around further broadening the API’s scope beyond its current ability to read from and write to both keyed and operator state. In upcoming releases, the State processor API will be extended to support both reading from and writing to windows and have a first-class integration with Flink’s Table API and SQL.
Beyond widening the scope of the State Processor API, the Flink community is discussing a few additional ways to improve the way developers interact with state in Flink. One of them is the proposal for a Unified Savepoint Format (FLIP-41) for all keyed state backends. Such improvement aims at introducing a unified binary format across all savepoints in all keyed state backends, something that drastically reduces the overhead of swapping the state backend in a Flink application. Such an improvement would allow developers to take a savepoint in their application and restart it in a different state backend — for example, moving it from the heap to disk (RocksDB state backend) and back — depending on the scalability and evolution of the application at different points-in-time.
The community is also discussing the ability to have upgradability dry runs in upcoming Flink releases. Having such functionality in Flink allows developers to detect incompatible updates offline without the need of starting a new Flink job from scratch. For example, Flink users will be able to uncover topology or schema incompatibilities upon upgrading a Flink job, without having to load the state back to a running Flink job in the first place. Additionally, with upgradability dry runs Flink users will be able to get information about the registered state through the streaming graph, without needing to access the state in the state backend.
With all the exciting new functionality added in Flink 1.9 as well as some solid ideas and discussions around bringing state in Flink to the next level, the community is committed to making state in Apache Flink a fundamental element of the framework, something that is ever-present across versions and upgrades of your application and a component that is a true first-class citizen in Apache Flink. We encourage you to sign up to the mailing list and stay on top of the announcements and new features in upcoming releases.