Flink Community Update - July'20
July 29, 2020 - Marta Paes (@morsapaes)As July draws to an end, we look back at a monthful of activity in the Flink community, including two releases (!) and some work around improving the first-time contribution experience in the project.
Also, events are starting to pick up again, so we’ve put together a list of some great ones you can (virtually) attend in August!
The Past Month in Flink #
Flink Releases #
Flink 1.11 #
A couple of weeks ago, Flink 1.11 was announced in what was (again) the biggest Flink release to date (see “A Look Into the Evolution of Flink Releases”)! The new release brought significant improvements to usability as well as new features to Flink users across the API stack. Some highlights of Flink 1.11 are:
-
Unaligned checkpoints to cope with high backpressure scenarios;
-
The new source API, that simplifies and unifies the implementation of (custom) sources;
-
Support for Change Data Capture (CDC) and other common use cases in the Table API/SQL;
-
Pandas UDFs and other performance optimizations in PyFlink, making it more powerful for data science and ML workloads.
For a more detailed look into the release, you can recap the announcement blogpost and join the upcoming meetup on “What’s new in Flink 1.11?”, where you’ll be able to ask anything release-related to Aljoscha Krettek (Flink PMC Member). The community has also been working on a series of blogposts that deep-dive into the most significant features and improvements in 1.11, so keep an eye on the Flink blog!
Flink 1.11.1 #
Shortly after releasing Flink 1.11, the community announced the first patch version to cover some outstanding issues in the major release. This version is particularly important for users of the Table API/SQL, as it addresses known limitations that affect the usability of new features like changelog sources and support for JDBC catalogs.
You can find a detailed list with all the improvements and bugfixes that went into Flink 1.11.1 in the announcement blogpost.
Gearing up for Flink 1.12 #
The Flink 1.12 release cycle has been kicked-off last week and a discussion about what features will go into the upcoming release is underway in this @dev Mailing List thread. While we wait for more of these ideas to turn into proposals and JIRA issues, here are some recent FLIPs that are already being discussed in the Flink community:
| FLIP | |
|---|---|
| FLIP-130 |
Python support in Flink has so far been bounded to the Table API/SQL. These APIs are high-level and convenient, but have some limitations for more complex stream processing use cases. To expand the usability of PyFlink to a broader set of use cases, FLIP-130 proposes to support it also in the DataStream API, starting with stateless operations. |
| FLIP-132 |
Flink SQL users can't currently create temporal tables using SQL DDL, which forces them to change context frequently for use cases that require them. FLIP-132 proposes to extend the DDL syntax to support temporal tables, which in turn will allow to also bring temporal joins with changelog sources to Flink SQL. |
New Committers and PMC Members #
The Apache Flink community has welcomed 2 new PMC Members since the last update. Congratulations!
New PMC Members #


The Bigger Picture #
A Look Into the Evolution of Flink Releases #
It’s been a while since we had a look at community numbers, so this time we’d like to shed some light on the evolution of contributors and, well, work across releases. Let’s have a look at some git data:
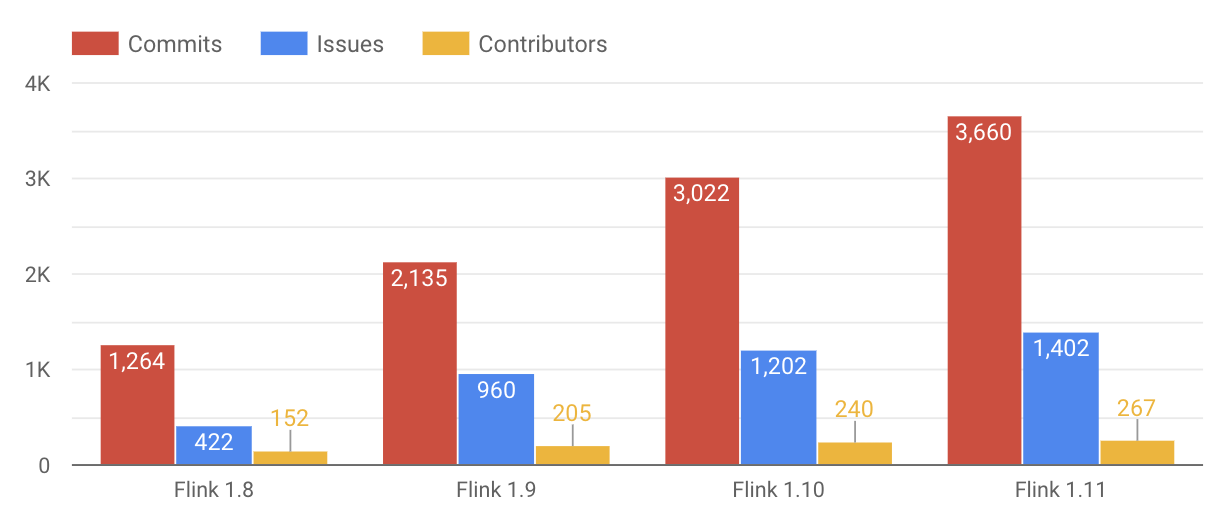
If we consider Flink 1.8 (Apr. 2019) as the baseline, the Flink community more than tripled the number of implemented and/or resolved issues in a single release with the support of an additional ~100 contributors in Flink 1.11. This is pretty impressive on its own, and even more so if you consider that Flink contributors are distributed around the globe, working across different locations and timezones!
First-time Contributor Guide #
Flink has an extensive guide for code and non-code contributions that helps new community members navigate the project and get familiar with existing contribution guidelines. In particular for code contributions, knowing where to start can be difficult, given the sheer size of the Flink codebase and the pace of development of the project.
To better guide new contributors, a brief section was added to the guide on how to look for what to contribute and the starter label has been revived in Jira to highlight issues that are suitable for first-time contributors.
Replacing “charged” words in the Flink repo #
The community is working on gradually replacing words that are outdated and carry a negative connotation in the Flink codebase, such as “master/slave” and “whitelist/blacklist”. The progress of this work can be tracked in FLINK-18209.
Upcoming Events (and More!) #
We’re happy to see the “high season” of virtual events approaching, with a lot of great conferences taking place in the coming month, as well as some meetups. Here, we highlight some of the Flink talks happening in those events, but we recommend checking out the complete event programs!
As usual, we also leave you with some resources to read and explore.
| Category | |
|---|---|
| Events |
Change Data Capture with Flink SQL and Debezium Sweet Streams are Made of These: Data Driven Development with Stream Processing
|
| Blogposts |
|
Flink Packages |
Flink Packages is a website where you can explore (and contribute to) the Flink |
If you’d like to keep a closer eye on what’s happening in the community, subscribe to the Flink @community mailing list to get fine-grained weekly updates, upcoming event announcements and more.