Accelerating your workload with GPU and other external resources
August 6, 2020 - Yangze GuoApache Flink 1.11 introduces a new External Resource Framework, which allows you to request external resources from the underlying resource management systems (e.g., Kubernetes) and accelerate your workload with those resources. As Flink provides a first-party GPU plugin at the moment, we will take GPU as an example and show how it affects Flink applications in the AI field. Other external resources (e.g. RDMA and SSD) can also be supported in a pluggable manner.
End-to-end real-time AI with GPU #
Recently, AI and Machine Learning have gained additional popularity and have been widely used in various scenarios, such as personalized recommendation and image recognition. Flink, with the ability to support GPU allocation, can be used to build an end-to-end real-time AI workflow.
Why Flink #
Typical AI workloads fall into two categories: training and inference.
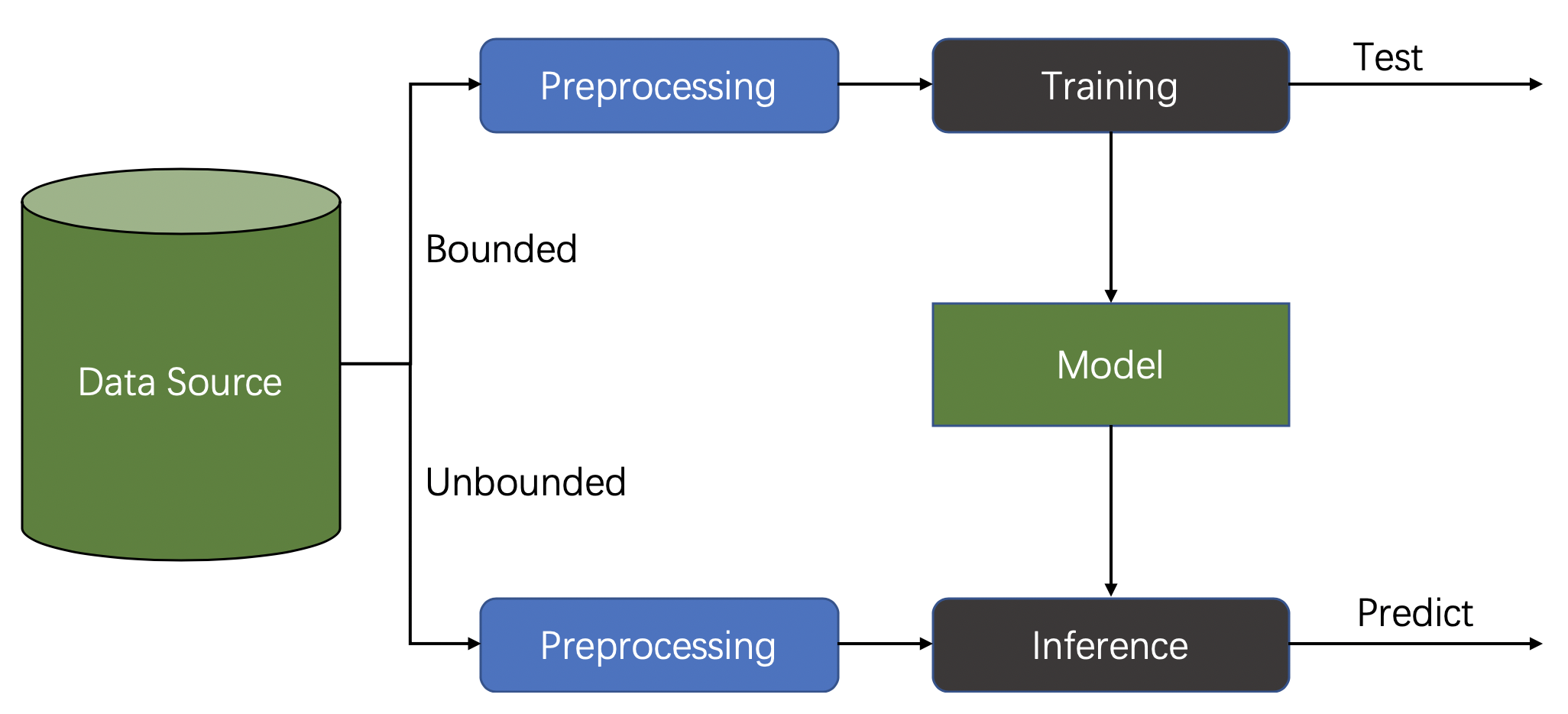
Typical AI Workflow
The training workload is usually a batch task, in which we train a model from a bounded dataset. On the other hand, the inference workload tends to be a streaming job. It consumes an unbounded data stream, which contains image data, for example, and uses a model to produce the output of predictions. Both workloads need to do data preprocessing first. Flink, as a unified batch and stream processing engine, can be used to build an end-to-end AI workflow naturally.
In many cases, the training and inference workload can benefit a lot by leveraging GPUs. Research shows that CPU cluster is outperformed by GPU cluster, which is of similar cost, by about 400 percent. As training datasets are getting bigger and models more complex, supporting GPUs has become mandatory for running AI workloads.
With the External Resource Framework and its GPU plugin, Flink can now request GPU resources from the external resource management system and expose GPU information to operators. With this feature, users can now easily build end-to-end training and real-time inference pipelines with GPU support on Flink.
Example: MNIST Inference with Flink #
We take the MNIST inference task as an example to show how to use the External Resource Framework and how to leverage GPUs in Flink. MNIST is a database of handwritten digits, which is usually viewed as the HelloWorld of AI. The goal is to recognize a 28px*28px picture of a number from 0 to 9.
First, you need to set configurations for the external resource framework to enable GPU support:
external-resources: gpu
# Define the driver factory class of gpu resource.
external-resource.gpu.driver-factory.class: org.apache.flink.externalresource.gpu.GPUDriverFactory
# Define the amount of gpu resource per TaskManager.
external-resource.gpu.amount: 1
# Enable the coordination mode if you run it in standalone mode
external-resource.gpu.param.discovery-script.args: --enable-coordination
# If you run it on Yarn
external-resource.gpu.yarn.config-key: yarn.io/gpu
# If you run it on Kubernetes
external-resource.gpu.kubernetes.config-key: nvidia.com/gpu
For more details of the configuration, please refer to the official documentation.
In the MNIST inference task, we first need to read the images and do data preprocessing. You can download training or testing data from this site. We provide a simple MNISTReader. It will read the image data located in the provided file path and transform each image into a list of floating point numbers.
Then, we need a classifier to recognize those images. A one-layer pre-trained neural network, whose prediction accuracy is 92.14%, is used in our classify operator. To leverage GPUs in order to accelerate the matrix-matrix multiplication, we use JCuda to call the native Cuda API. The prediction logic of the MNISTClassifier is shown below.
class MNISTClassifier extends RichMapFunction<List<Float>, Integer> {
@Override
public void open(Configuration parameters) {
// Get the GPU information and select the first GPU.
final Set<ExternalResourceInfo> externalResourceInfos = getRuntimeContext().getExternalResourceInfos(resourceName);
final Optional<String> firstIndexOptional = externalResourceInfos.iterator().next().getProperty("index");
// Initialize JCublas with the selected GPU
JCuda.cudaSetDevice(Integer.parseInt(firstIndexOptional.get()));
JCublas.cublasInit();
}
@Override
public Integer map(List<Float> value) {
// Performs multiplication using JCublas. The matrixPointer points to our pre-trained model.
JCublas.cublasSgemv('n', DIMENSIONS.f1, DIMENSIONS.f0, 1.0f,
matrixPointer, DIMENSIONS.f1, inputPointer, 1, 0.0f, outputPointer, 1);
// Read the result back from GPU.
JCublas.cublasGetVector(DIMENSIONS.f1, Sizeof.FLOAT, outputPointer, 1, Pointer.to(output), 1);
int result = 0;
for (int i = 0; i < DIMENSIONS.f1; ++i) {
result = output[i] > output[result] ? i : result;
}
return result;
}
}
The complete MNIST inference project can be found here. In this project, we simply print the inference result to STDOUT. In the actual production environment, you could also write the result to Elasticsearch or Kafka, for example.
The MNIST inference task is just a simple case that shows you how the external resource framework works and what Flink can do with GPU support. With Flink’s open source extension Alink, which contains a lot of pre-built algorithms based on Flink, and Tensorflow on Flink, some complex AI workloads, e.g. online learning, real-time inference service, could be easily implemented as well.
Other external resources #
In addition to GPU support, there are many other external resources that can be used to accelerate jobs in some specific scenarios. E.g. FPGA, for AI workloads, is supported by both Yarn and Kubernetes. Some low-latency network devices, like RDMA and Solarflare, also provide their device plugin for Kubernetes. Currently, Yarn supports GPUs and FPGAs, while the list of Kubernetes’ device plugins can be found here.
With the external resource framework, you only need to implement a plugin that enables the operator to get the information for these external resources; see Custom Plugin for more details. If you just want to ensure that an external resource exists in the TaskManager, then you only need to find the configuration key of that resource in the underlying resource management system and configure the external resource framework accordingly.
Conclusion #
In the latest Flink release (Flink 1.11), an external resource framework has been introduced to support requesting various types of resources from the underlying resource management systems, and supply all the necessary information for using these resources to the operators. The first-party GPU plugin expands the application prospects of Flink in the AI domain. Different resource types can be supported in a pluggable way. You can also implement your own plugins for custom resource types.
Future developments in this area include implementing operator level resource isolation and fine-grained external resource scheduling. The community may kick this work off once FLIP-56 is finished. If you have any suggestions or questions for the community, we encourage you to sign up to the Apache Flink mailing lists and join the discussion there.