Improvements in task scheduling for batch workloads in Apache Flink 1.12
December 2, 2020 - Andrey ZagrebinThe Flink community has been working for some time on making Flink a truly unified batch and stream processing system. Achieving this involves touching a lot of different components of the Flink stack, from the user-facing APIs all the way to low-level operator processes such as task scheduling. In this blogpost, we’ll take a closer look at how far the community has come in improving scheduling for batch workloads, why this matters and what you can expect in the Flink 1.12 release with the new pipelined region scheduler.
Towards unified scheduling #
Flink has an internal scheduler to distribute work to all available cluster nodes, taking resource utilization, state locality and recovery into account. How do you write a scheduler for a unified batch and streaming system? To answer this question, let’s first have a look into the high-level differences between batch and streaming scheduling requirements.
Streaming #
Streaming jobs usually require that all operator subtasks are running in parallel at the same time, for an indefinite time. Therefore, all the required resources to run these jobs have to be provided upfront, and all operator subtasks must be deployed at once.
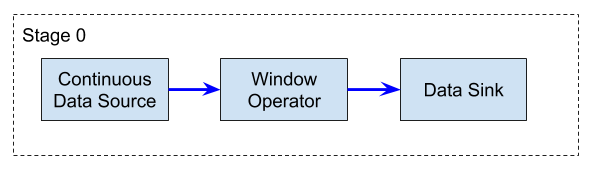
Flink: Streaming job example
Because there are no finite intermediate results, a streaming job always has to be restarted fully from a checkpoint or a savepoint in case of failure.
Batch #
In contrast to streaming jobs, batch jobs usually consist of one or more stages that can have dependencies between them. Each stage will only run for a finite amount of time and produce some finite output (i.e. at some point, the batch job will be finished). Independent stages can run in parallel to improve execution time, but for cases where there are dependencies between stages, a stage may have to wait for upstream results to be produced before it can run. These are called blocking results, and in this case stages cannot run in parallel.
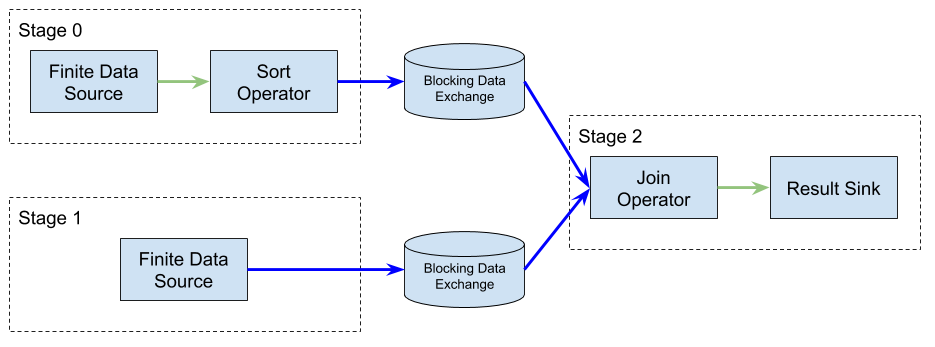
Flink: Batch job example
As an example, in the figure above Stage 0 and Stage 1 can run simultaneously, as there is no dependency between them. Stage 3, on the other hand, can only be scheduled once both its inputs are available. There are a few implications from this:
-
(a) You can use available resources more efficiently by only scheduling stages that have data to perform work;
-
(b) You can use this mechanism also for failover: if a stage fails, it can be restarted individually, without recomputing the results of other stages.
Scheduling Strategies in Flink before 1.12 #
Given these differences, a unified scheduler would have to be good at resource management for each individual stage, be it finite (batch) or infinite (streaming), and also across multiple stages. The existing scheduling strategies in older Flink versions up to 1.11 have been largely designed to address these concerns separately.
“All at once (Eager)”
This strategy is the simplest: Flink just tries to allocate resources and deploy all subtasks at once. Up to Flink 1.11, this is the scheduling strategy used for all streaming jobs. For batch jobs, using “all at once” scheduling would lead to suboptimal resource utilization, since it’s unlikely that such jobs would require all resources upfront, and any resources allocated to subtasks that could not run at a given moment would be idle and therefore wasted.
“Lazy from sources”
To account for blocking results and make sure that no consumer is deployed before their respective producers are finished, Flink provides a different scheduling strategy for batch workloads. “Lazy from sources” scheduling deploys subtasks only once all their inputs are ready. This strategy operates on each subtask individually; it does not identify all subtasks which can (or have to) run at the same time.
A practical example #
Let’s take a closer look at the specific case of batch jobs, using as motivation a simple SQL query:
CREATE TABLE customers (
customerId int,
name varchar(255)
);
CREATE TABLE orders (
orderId int,
orderCustomerId int
);
--fill tables with data
SELECT customerId, name
FROM customers, orders
WHERE customerId = orderCustomerId
Assume that two tables were created in some database: the customers table is relatively small and fits into the local memory (or also on disk). The orders table is bigger, as it contains all orders created by customers, and doesn’t fit in memory. To enrich the orders with the customer name, you have to join these two tables. There are basically two stages in this batch job:
- Load the complete
customerstable into a local map:(customerId, name); because this table is smaller, - Process the
orderstable record by record, enriching it with thenamevalue from the map.
Executing the job #
The batch job described above will have three operators. For simplicity, each operator is represented with a parallelism of 1, so the resulting ExecutionGraph will consist of three subtasks: A, B and C.
- A: load full
customerstable - B: load
orderstable record by record in a streaming (pipelined) fashion - C: join order table records with the loaded customer table
This translates into A and C being connected with a blocking data exchange,
because the customers table needs to be loaded locally (A) before we start processing the order table (B).
B and C are connected with a pipelined data exchange,
because the consumer (C) can run as soon as the first result records from B have been produced.
You can think of B->C as a finite streaming job. It’s then possible to identify two separate stages within the ExecutionGraph: A and B->C.
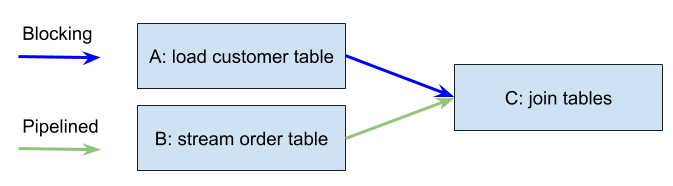
Flink: SQL Join job example
Scheduling Limitations #
Imagine that the cluster this job will run in has only one slot and can therefore only execute one subtask. If Flink deploys B chained with C first into this one slot (as B and C are connected with a pipelined edge), C cannot run because A has not produced its blocking result yet. Flink will try to deploy A and the job will fail, because there are no more slots. If there were two slots available, Flink would be able to deploy A and the job would eventually succeed. Nonetheless, the resources of the first slot occupied by B and C would be wasted while A was running.
Both scheduling strategies available as of Flink 1.11 (“all at once” and “lazy from source”) would be affected by these limitations. What would be the optimal approach? In this case, if A was deployed first, then B and C could also complete afterwards using the same slot. The job would succeed even if only a single slot was available.
Last but not least, let’s consider what happens in the case of failover: if the processing of the orders table fails (B->C),
then we do not have to reload the customer table (A); we only need to restart B->C. This did not work prior to Flink 1.9.
To satisfy the scheduling requirements for batch and streaming and overcome these limitations, the Flink community has worked on a new unified scheduling and failover strategy that is suitable for both types of workloads: pipelined region scheduling.
The new pipelined region scheduling #
As you read in the previous introductory sections, an optimal scheduler should efficiently allocate resources for the sub-stages of the pipeline, finite or infinite, running in a streaming fashion. Those stages are called pipelined regions in Flink. In this section, we will take a deeper dive into pipelined region scheduling and failover.
Pipelined regions #
The new scheduling strategy analyses the ExecutionGraph before starting the subtask deployment in order to identify its pipelined regions. A pipelined region is a subset of subtasks in the ExecutionGraph connected by pipelined data exchanges. Subtasks from different pipelined regions are connected only by blocking data exchanges. The depicted example of an ExecutionGraph has four pipelined regions and subtasks, A to H:
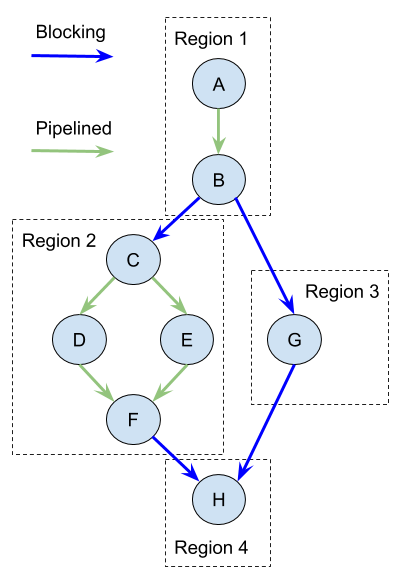
Flink: Pipelined regions
Why do we need the pipelined region? Within the pipelined region all consumers have to constantly consume the produced results to not block the producers and avoid backpressure. Hence, all subtasks of a pipelined region have to be scheduled, restarted in case of failure and run at the same time.
Pipelined region scheduling strategy #
Once the pipelined regions are identified, each region is scheduled only when all the regions it depends on (i.e. its inputs), have produced their blocking results (for the depicted graph: R2 and R3 after R1; R4 after R2 and R3). If the JobManager has enough resources available, it will try to run as many schedulable pipelined regions in parallel as possible. The subtasks of a pipelined region are either successfully deployed all at once or none at all. The job fails if there are not enough resources to run any of its pipelined regions. You can read more about this effort in the original FLIP-119 proposal.
Failover strategy #
As mentioned before, only certain regions are running at the same time. Others have already produced their blocking results. The results are stored locally in TaskManagers where the corresponding subtasks run. If a currently running region fails, it gets restarted to consume its inputs again. If some input results got lost (e.g. the hosting TaskManager failed as well), Flink will rerun their producing regions. You can read more about this effort in the user documentation and the original FLIP-1 proposal.
Benefits #
Run any batch job, possibly with limited resources
The subtasks of a pipelined region are deployed only when all necessary conditions for their success are fulfilled: inputs are ready and all needed resources are allocated. Hence, the batch job never gets stuck without notifying the user. The job either eventually finishes or fails after a timeout.
Depending on how the subtasks are allowed to share slots, it is often the case that the whole pipelined region can run within one slot, making it generally possible to run the whole batch job with only a single slot. At the same time, if the cluster provides more resources, Flink will run as many regions as possible in parallel to improve the overall job performance.
No resource waste
As mentioned in the definition of pipelined region, all its subtasks have to run simultaneously. The subtasks of other regions either cannot or do not have to run at the same time. This means that a pipelined region is the minimum subgraph of a batch job’s ExecutionGraph that has to be scheduled at once. There is no way to run the job with fewer resources than needed to run the largest region, and so there can be no resource waste.
Conclusion #
Scheduling is a fundamental component of the Flink stack. In this blogpost, we recapped how scheduling affects resource utilization and failover as a part of the user experience. We described the limitations of Flink’s old scheduler and introduced a new approach to tackle them: the pipelined region scheduler, which ships with Flink 1.12. The blogpost also explained how pipelined region failover (introduced in Flink 1.11) works.
Stay tuned for more improvements to scheduling in upcoming releases. If you have any suggestions or questions for the community, we encourage you to sign up to the Apache Flink mailing lists and become part of the discussion.
Appendix #
What is scheduling? #
ExecutionGraph #
A Flink job is a pipeline of connected operators to process data. Together, the operators form a JobGraph. Each operator has a certain number of subtasks executed in parallel. The subtask is the actual execution unit in Flink. Each subtask can consume user records from other subtasks (inputs), process them and produce records for further consumption by other subtasks (outputs) down the stream. There are source subtasks without inputs and sink subtasks without outputs. Hence, the subtasks form the nodes of the ExecutionGraph.
Intermediate results #
There are also two major data-exchange types to produce and consume results by operators and their subtasks: pipelined and blocking. They are basically types of edges in the ExecutionGraph.
A pipelined result can be consumed record by record. This means that the consumer can already run once the first result records have been produced. A pipelined result can be a never ending output of records, e.g. in case of a streaming job.
A blocking result can be consumed only when its production is done. Hence, the blocking result is always finite and the consumer of the blocking result can run only when the producer has finished its execution.
Slots and resources #
A TaskManager instance has a certain number of virtual slots. Each slot represents a certain part of the TaskManager’s physical resources to run the operator subtasks, and each subtask is deployed into a slot of the TaskManager. A slot can run multiple subtasks from different operators at the same time, usually chained together.
Scheduling strategy #
Scheduling in Flink is a process of searching for and allocating appropriate resources (slots) from the TaskManagers to run the subtasks and produce results. The scheduling strategy reacts on scheduling events (like start job, subtask failed or finished etc) to decide which subtask to deploy next.
For instance, it does not make sense to schedule subtasks whose inputs are not ready to consume yet to avoid wasting resources. Another example is to schedule subtasks which are connected with pipelined edges together, to avoid deadlocks caused by backpressure.