Apache Flink 1.12.0 Release Announcement
December 10, 2020 - Marta Paes (@morsapaes) Aljoscha Krettek (@aljoscha)The Apache Flink community is excited to announce the release of Flink 1.12.0! Close to 300 contributors worked on over 1k threads to bring significant improvements to usability as well as new features that simplify (and unify) Flink handling across the API stack.
Release Highlights
-
The community has added support for efficient batch execution in the DataStream API. This is the next major milestone towards achieving a truly unified runtime for both batch and stream processing.
-
Kubernetes-based High Availability (HA) was implemented as an alternative to ZooKeeper for highly available production setups.
-
The Kafka SQL connector has been extended to work in upsert mode, supported by the ability to handle connector metadata in SQL DDL. Temporal table joins can now also be fully expressed in SQL, no longer depending on the Table API.
-
Support for the DataStream API in PyFlink expands its usage to more complex scenarios that require fine-grained control over state and time, and it’s now possible to deploy PyFlink jobs natively on Kubernetes.
This blog post describes all major new features and improvements, important changes to be aware of and what to expect moving forward.
The binary distribution and source artifacts are now available on the updated Downloads page of the Flink website, and the most recent distribution of PyFlink is available on PyPI. Please review the release notes carefully, and check the complete release changelog and updated documentation for more details.
We encourage you to download the release and share your feedback with the community through the Flink mailing lists or JIRA.
New Features and Improvements #
Batch Execution Mode in the DataStream API #
Flink’s core APIs have developed organically over the lifetime of the project, and were initially designed with specific use cases in mind. And while the Table API/SQL already has unified operators, using lower-level abstractions still requires you to choose between two semantically different APIs for batch (DataSet API) and streaming (DataStream API). Since a batch is a subset of an unbounded stream, there are some clear advantages to consolidating them under a single API:
-
Reusability: efficient batch and stream processing under the same API would allow you to easily switch between both execution modes without rewriting any code. So, a job could be easily reused to process real-time and historical data.
-
Operational simplicity: providing a unified API would mean using a single set of connectors, maintaining a single codebase and being able to easily implement mixed execution pipelines e.g. for use cases like backfilling.
With these advantages in mind, the community has taken the first step towards the unification of the DataStream API: supporting efficient batch execution (FLIP-134). This means that, in the long run, the DataSet API will be deprecated and subsumed by the DataStream API and the Table API/SQL (FLIP-131). For an overview of the unification effort, refer to this recent Flink Forward talk.
Batch for Bounded Streams
You could already use the DataStream API to process bounded streams (e.g. files), with the limitation that the runtime is not “aware” that the job is bounded. To optimize the runtime for bounded input, the new BATCH mode execution uses sort-based shuffles with aggregations purely in-memory and an improved scheduling strategy (see Pipelined Region Scheduling). As a result, BATCH mode execution in the DataStream API already comes very close to the performance of the DataSet API in Flink 1.12. For more details on the performance benchmark, check the original proposal (FLIP-140).
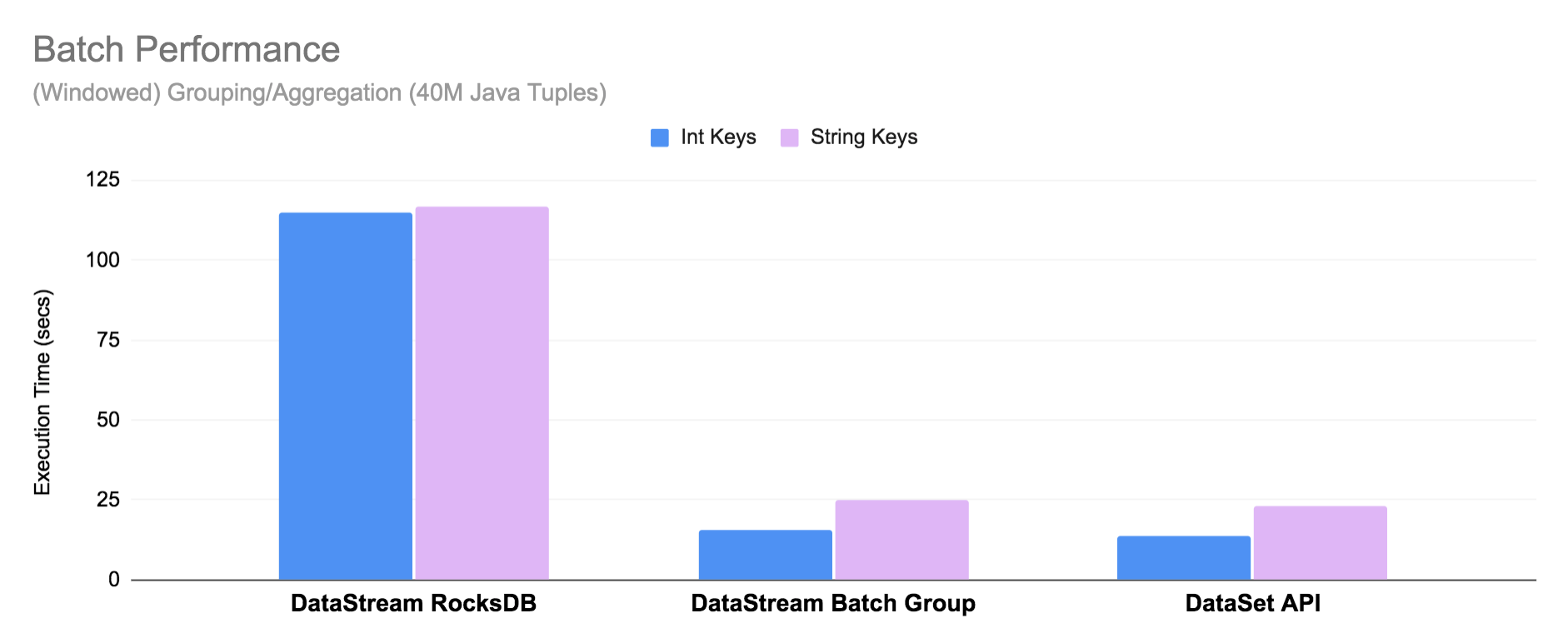
In Flink 1.12, the default execution mode is STREAMING. To configure a job to run in BATCH mode, you can set the configuration when submitting a job:
bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
, or do it programmatically:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeMode.BATCH);
BATCH execution mode for new batch jobs, and consider migrating existing DataSet jobs.
New Data Sink API (Beta) #
Ensuring that connectors can work for both execution modes has already been covered for data sources in the previous release, so in Flink 1.12 the community focused on implementing a unified Data Sink API (FLIP-143). The new abstraction introduces a write/commit protocol and a more modular interface where the individual components are transparently exposed to the framework.
A Sink implementor will have to provide the what and how: a SinkWriter that writes data and outputs what needs to be committed (i.e. committables); and a Committer and GlobalCommitter that encapsulate how to handle the committables. The framework is responsible for the when and where: at what time and on which machine or process to commit.
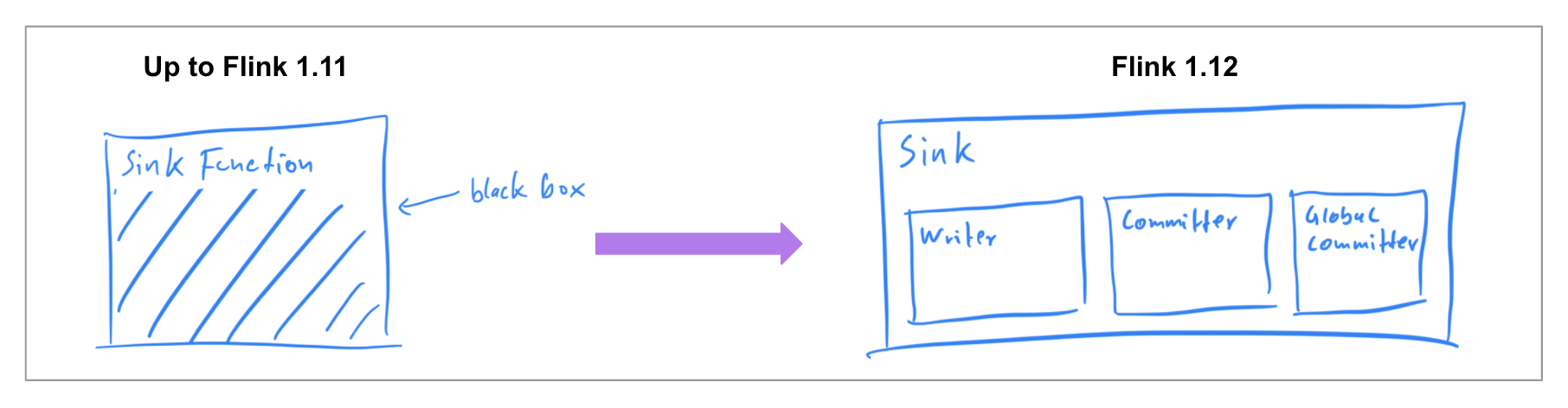
This more modular abstraction allowed to support different runtime implementations for the BATCH and STREAMING execution modes that are efficient for their intended purpose, but use just one, unified sink implementation. In Flink 1.12, the FileSink connector is the unified drop-in replacement for StreamingFileSink (FLINK-19758). The remaining connectors will be ported to the new interfaces in future releases.
Kubernetes High Availability (HA) Service #
Kubernetes provides built-in functionalities that Flink can leverage for JobManager failover, instead of relying on ZooKeeper. To enable a “ZooKeeperless” HA setup, the community implemented a Kubernetes HA service in Flink 1.12 (FLIP-144). The service is built on the same base interface as the ZooKeeper implementation and uses Kubernetes’ ConfigMap objects to handle all the metadata needed to recover from a JobManager failure. For more details and examples on how to configure a highly available Kubernetes cluster, check out the documentation.
Other Improvements #
Migration of existing connectors to the new Data Source API
The previous release introduced a new Data Source API (FLIP-27), allowing to implement connectors that work both as bounded (batch) and unbounded (streaming) sources. In Flink 1.12, the community started porting existing source connectors to the new interfaces, starting with the FileSystem connector (FLINK-19161).
Pipelined Region Scheduling (FLIP-119)
Flink’s scheduler has been largely designed to address batch and streaming workloads separately. This release introduces a unified scheduling strategy that identifies blocking data exchanges to break down the execution graph into pipelined regions. This allows to schedule each region only when there’s data to perform work and only deploy it once all the required resources are available; as well as to restart failed regions independently. In particular for batch jobs, the new strategy leads to more efficient resource utilization and eliminates deadlocks.
Support for Sort-Merge Shuffles (FLIP-148)
To improve the stability, performance and resource utilization of large-scale batch jobs, the community introduced sort-merge shuffle as an alternative to the original shuffle implementation that Flink already used. This approach can reduce shuffle time significantly, and uses fewer file handles and file write buffers (which is problematic for large-scale jobs). Further optimizations will be implemented in upcoming releases (FLINK-19614).
Improvements to the Flink WebUI (FLIP-75)
As a continuation of the series of improvements to the Flink WebUI kicked off in the last release, the community worked on exposing JobManager’s memory-related metrics and configuration parameters on the WebUI (FLIP-104). The TaskManager’s metrics page has also been updated to reflect the changes to the TaskManager memory model introduced in Flink 1.10 (FLIP-102), adding new metrics for Managed Memory, Network Memory and Metaspace.
Table API/SQL: Metadata Handling in SQL Connectors #
Some sources (and formats) expose additional fields as metadata that can be valuable for users to process along with record data. A common example is Kafka, where you might want to e.g. access offset, partition or topic information, read/write the record key or use embedded metadata timestamps for time-based operations.
With the new release, Flink SQL supports metadata columns to read and write connector- and format-specific fields for every row of a table (FLIP-107). These columns are declared in the CREATE TABLE statement using the METADATA (reserved) keyword.
CREATE TABLE kafka_table (
id BIGINT,
name STRING,
event_time TIMESTAMP(3) METADATA FROM 'timestamp', -- access Kafka 'timestamp' metadata
headers MAP<STRING, BYTES> METADATA -- access Kafka 'headers' metadata
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'format' = 'avro'
);
In Flink 1.12, metadata is exposed for the Kafka and Kinesis connectors, with work on the FileSystem connector already planned (FLINK-19903). Due to the more complex structure of Kafka records, new properties were also specifically implemented for the Kafka connector to control how to handle the key/value pairs. For a complete overview of metadata support in Flink SQL, check the documentation for each connector, as well as the motivating use cases in the original proposal.
Table API/SQL: Upsert Kafka Connector #
For some use cases, like interpreting compacted topics or writing out (updating) aggregated results, it’s necessary to handle Kafka record keys as true primary keys that can determine what should be inserted, deleted or updated. To enable this, the community created a dedicated upsert connector (upsert-kafka) that extends the base implementation to work in upsert mode (FLIP-149).
The new upsert-kafka connector can be used for sources and sinks, and provides the same base functionality and persistence guarantees as the existing Kafka connector, as it reuses most of its code under the hood. To use the upsert-kafka connector, you must define a primary key constraint on table creation, as well as specify the (de)serialization format for the key (key.format) and value (value.format).
Table API/SQL: Support for Temporal Table Joins in SQL #
Instead of creating a temporal table function to look up against a table at a certain point in time, you can now simply use the standard SQL clause FOR SYSTEM_TIME AS OF (SQL:2011) to express a temporal table join. In addition, temporal joins are now supported against any kind of table that has a time attribute and a primary key, and not just append-only tables. This unlocks a new set of use cases, like performing temporal joins directly against Kafka compacted topics or database changelogs (e.g. from Debezium).
-- Table backed by a Kafka topic
CREATE TABLE orders (
order_id STRING,
currency STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '30' SECOND
) WITH (
'connector' = 'kafka',
...
);
-- Table backed by a Kafka compacted topic
CREATE TABLE latest_rates (
currency STRING,
currency_rate DECIMAL(38, 10),
currency_time TIMESTAMP(3),
WATERMARK FOR currency_time AS currency_time - INTERVAL '5' SECOND,
PRIMARY KEY (currency) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
...
);
-- Event-time temporal table join
SELECT
o.order_id,
o.order_time,
o.amount * r.currency_rate AS amount,
r.currency
FROM orders AS o JOIN latest_rates FOR SYSTEM_TIME AS OF o.order_time r
ON o.currency = r.currency;
The previous example also shows how you can take advantage of the new upsert-kafka connector in the context of temporal table joins.
Hive Tables in Temporal Table Joins
You can also perform temporal table joins against Hive tables by either automatically reading the latest table partition as a temporal table (FLINK-19644) or the whole table as a bounded stream tracking the latest version at execution time. Refer to the documentation for examples of using Hive tables in temporal table joins.
Other Improvements to the Table API/SQL #
Kinesis Flink SQL Connector (FLINK-18858)
From Flink 1.12, Amazon Kinesis Data Streams (KDS) is natively supported as a source/sink also in the Table API/SQL. The new Kinesis SQL connector ships with support for Enhanced Fan-Out (EFO) and Sink Partitioning. For a complete overview of supported features, configuration options and exposed metadata, check the updated documentation.
Streaming Sink Compaction in the FileSystem/Hive Connector (FLINK-19345)
Many bulk formats, such as Parquet, are most efficient when written as large files; this is a challenge when frequent checkpointing is enabled, as too many small files are created (and need to be rolled on checkpoint). In Flink 1.12, the file sink supports file compaction, allowing jobs to retain smaller checkpoint intervals without generating a large number of files. To enable file compaction, you can set auto-compaction=true in the properties of the FileSystem connector, as described in the documentation.
Watermark Pushdown in the Kafka Connector (FLINK-20041)
To ensure correctness when consuming from Kafka, it’s generally preferable to generate watermarks on a per-partition basis, since the out-of-orderness within a partition is usually lower than across all partitions. Flink will now push down watermark strategies to emit per-partition watermarks from within the Kafka consumer. The output watermark of the source will be determined by the minimum watermark across the partitions it reads, leading to better (i.e. closer to real-time) watermarking. Watermark pushdown also lets you configure per-partition idleness detection to prevent idle partitions from holding back the event time progress of the entire application.
Newly Supported Formats
| Format | Description | Supported Connectors |
|---|---|---|
| Avro Schema Registry | Read and write data serialized with the Confluent Schema Registry KafkaAvroSerializer. | Kafka, Upsert Kafka |
| Debezium Avro | Read and write Debezium records serialized with the Confluent Schema Registry KafkaAvroSerializer. | Kafka |
| Maxwell (CDC) | Read and write Maxwell JSON records. |
Kafka FileSystem |
Raw | Read and write raw (byte-based) values as a single column. |
Kafka, Upsert Kafka Kinesis FileSystem |
Multi-input Operator for Join Optimization (FLINK-19621)
To eliminate unnecessary serialization and data spilling and improve the performance of batch and streaming Table API/SQL jobs, the default planner now leverages the N-ary stream operator introduced in the last release (FLIP-92) to implement the “chaining” of operators connected by forward edges.
Type Inference for Table API UDAFs (FLIP-65)
This release concluded the work started in Flink 1.9 on a new data type system for the Table API, with the exposure of aggregate functions (UDAFs) to the new type system. From Flink 1.12, UDAFs behave similarly to scalar and table functions, and support all data types.
PyFlink: Python DataStream API #
To expand the usability of PyFlink, this release introduces a first version of the Python DataStream API (FLIP-130) with support for stateless operations (e.g. Map, FlatMap, Filter, KeyBy).
from pyflink.common.typeinfo import Types
from pyflink.datastream import MapFunction, StreamExecutionEnvironment
class MyMapFunction(MapFunction):
def map(self, value):
return value + 1
env = StreamExecutionEnvironment.get_execution_environment()
data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())
mapped_stream.print()
env.execute("datastream job")
To give the Python DataStream API a try, you can install PyFlink and check out this tutorial that guides you through building a simple streaming application.
Other Improvements to PyFlink #
PyFlink Jobs on Kubernetes (FLINK-17480)
In addition to standalone and YARN deployments, PyFlink jobs can now also be deployed natively on Kubernetes. The deployment documentation has detailed instructions on how to start a session or application cluster on Kubernetes.
User-defined Aggregate Functions (UDAFs)
From Flink 1.12, you can define and register UDAFs in PyFlink (FLIP-139). In contrast to a normal UDF, which doesn’t handle state and operates on a single row at a time, a UDAF is stateful and can be used to compute custom aggregations over multiple input rows. To benefit from vectorization, you can also use Pandas UDAFs (FLIP-137) (up to 10x faster).
Important Changes #
-
[FLINK-19319] The default stream time characteristic has been changed to
EventTime, so you no longer need to callStreamExecutionEnvironment.setStreamTimeCharacteristic()to enable event time support. -
[FLINK-19278] Flink now relies on Scala Macros 2.1.1, so Scala versions < 2.11.11 are no longer supported.
-
[FLINK-19152] The Kafka 0.10.x and 0.11.x connectors have been removed with this release. If you’re still using these versions, please refer to the documentation to learn how to upgrade to the universal Kafka connector.
-
[FLINK-18795] The HBase connector has been upgraded to the last stable version (2.2.3).
-
[FLINK-17877] PyFlink now supports Python 3.8.
-
[FLINK-18738] To align with FLIP-53, managed memory is now the default also for Python workers. The configurations
python.fn-execution.buffer.memory.sizeandpython.fn-execution.framework.memory.sizehave been removed and will not take effect anymore.
Release Notes #
Please review the release notes carefully for a detailed list of changes and new features if you plan to upgrade your setup to Flink 1.12. This version is API-compatible with previous 1.x releases for APIs annotated with the @Public annotation.
List of Contributors #
The Apache Flink community would like to thank each and every one of the 300 contributors that have made this release possible:
Abhijit Shandilya, Aditya Agarwal, Alan Su, Alexander Alexandrov, Alexander Fedulov, Alexey Trenikhin, Aljoscha Krettek, Allen Madsen, Andrei Bulgakov, Andrey Zagrebin, Arvid Heise, Authuir, Bairos, Bartosz Krasinski, Benchao Li, Brandon, Brian Zhou, C08061, Canbin Zheng, Cedric Chen, Chesnay Schepler, Chris Nix, Congxian Qiu, DG-Wangtao, Da(Dash)Shen, Dan Hill, Daniel Magyar, Danish Amjad, Danny Chan, Danny Cranmer, David Anderson, Dawid Wysakowicz, Devin Thomson, Dian Fu, Dongxu Wang, Dylan Forciea, Echo Lee, Etienne Chauchot, Fabian Paul, Felipe Lolas, Fin-Chan, Fin-chan, Flavio Pompermaier, Flora Tao, Fokko Driesprong, Gao Yun, Gary Yao, Ghildiyal, GitHub, Grebennikov Roman, GuoWei Ma, Gyula Fora, Hequn Cheng, Herman, Hong Teoh, HuangXiao, HuangXingBo, Husky Zeng, Hyeonseop Lee, I. Raleigh, Ivan, Jacky Lau, Jark Wu, Jaskaran Bindra, Jeff Yang, Jeff Zhang, Jiangjie (Becket) Qin, Jiatao Tao, Jiayi Liao, Jiayi-Liao, Jiezhi.G, Jimmy.Zhou, Jindrich Vimr, Jingsong Lee, JingsongLi, Joey Echeverria, Juha Mynttinen, Jun Qin, Jörn Kottmann, Karim Mansour, Kevin Bohinski, Kezhu Wang, Konstantin Knauf, Kostas Kloudas, Kurt Young, Lee Do-Kyeong, Leonard Xu, Lijie Wang, Liu Jiangang, Lorenzo Nicora, LululuAlu, Luxios22, Marta Paes Moreira, Mateusz Sabat, Matthias Pohl, Maximilian Michels, Miklos Gergely, Milan Nikl, Nico Kruber, Niel Hu, Niels Basjes, Oleksandr Nitavskyi, Paul Lam, Peng, PengFei Li, PengchengLiu, Peter Huang, Piotr Nowojski, PoojaChandak, Qingsheng Ren, Qishang Zhong, Richard Deurwaarder, Richard Moorhead, Robert Metzger, Roc Marshal, Roey Shem Tov, Roman, Roman Khachatryan, Rong Rong, Rui Li, Seth Wiesman, Shawn Huang, ShawnHx, Shengkai, Shuiqiang Chen, Shuo Cheng, SteNicholas, Stephan Ewen, Steve Whelan, Steven Wu, Tartarus0zm, Terry Wang, Thesharing, Thomas Weise, Till Rohrmann, Timo Walther, TsReaper, Tzu-Li (Gordon) Tai, Ufuk Celebi, V1ncentzzZ, Vladimirs Kotovs, Wei Zhong, Weike DONG, XBaith, Xiaogang Zhou, Xiaoguang Sun, Xingcan Cui, Xintong Song, Xuannan, Yang Liu, Yangze Guo, Yichao Yang, Yikun Jiang, Yu Li, Yuan Mei, Yubin Li, Yun Gao, Yun Tang, Yun Wang, Zhenhua Yang, Zhijiang, Zhu Zhu, acesine, acqua.csq, austin ce, bigdata-ny, billyrrr, caozhen, caozhen1937, chaojianok, chenkai, chris, cpugputpu, dalong01.liu, darionyaphet, dijie, diohabara, dufeng1010, fangliang, felixzheng, gkrishna, gm7y8, godfrey he, godfreyhe, gsralex, haseeb1431, hequn.chq, hequn8128, houmaozheng, huangxiao, huangxingbo, huzekang, jPrest, jasonlee, jinfeng, jinhai, johnm, jxeditor, kecheng, kevin.cyj, kevinzwx, klion26, leiqiang, libenchao, lijiewang.wlj, liufangliang, liujiangang, liuyongvs, liuyufei9527, lsy, lzy3261944, mans2singh, molsionmo, openopen2, pengweibo, rinkako, sanshi@wwdz.onaliyun.com, secondChoice, seunjjs, shaokan.cao, shizhengchao, shizk233, shouweikun, spurthi chaganti, sujun, sunjincheng121, sxnan, tison, totorooo, venn, vthinkxie, wangsong2, wangtong, wangxiyuan, wangxlong, wangyang0918, wangzzu, weizheng92, whlwanghailong, wineandcheeze, wooplevip, wtog, wudi28, wxp, xcomp, xiaoHoly, xiaolong.wang, yangyichao-mango, yingshin, yushengnan, yushujun, yuzhao.cyz, zhangap, zhangmang, zhangzhanchum, zhangzhanchun, zhangzhanhua, zhangzp, zheyu, zhijiang, zhushang, zhuxiaoshang, zlzhang0122, zodo, zoudan, zouzhiye