Using RocksDB State Backend in Apache Flink: When and How
January 18, 2021 - Jun QinStream processing applications are often stateful, “remembering” information from processed events and using it to influence further event processing. In Flink, the remembered information, i.e., state, is stored locally in the configured state backend. To prevent data loss in case of failures, the state backend periodically persists a snapshot of its contents to a pre-configured durable storage. The RocksDB state backend (i.e., RocksDBStateBackend) is one of the three built-in state backends in Flink. This blog post will guide you through the benefits of using RocksDB to manage your application’s state, explain when and how to use it and also clear up a few common misconceptions. Having said that, this is not a blog post to explain how RocksDB works in-depth or how to do advanced troubleshooting and performance tuning; if you need help with any of those topics, you can reach out to the Flink User Mailing List.
State in Flink #
To best understand state and state backends in Flink, it’s important to distinguish between in-flight state and state snapshots. In-flight state, also known as working state, is the state a Flink job is working on. It is always stored locally in memory (with the possibility to spill to disk) and can be lost when jobs fail without impacting job recoverability. State snapshots, i.e., checkpoints and savepoints, are stored in a remote durable storage, and are used to restore the local state in the case of job failures. The appropriate state backend for a production deployment depends on scalability, throughput, and latency requirements.
What is RocksDB? #
Thinking of RocksDB as a distributed database that needs to run on a cluster and to be managed by specialized administrators is a common misconception. RocksDB is an embeddable persistent key-value store for fast storage. It interacts with Flink via the Java Native Interface (JNI). The picture below shows where RocksDB fits in a Flink cluster node. Details are explained in the following sections.
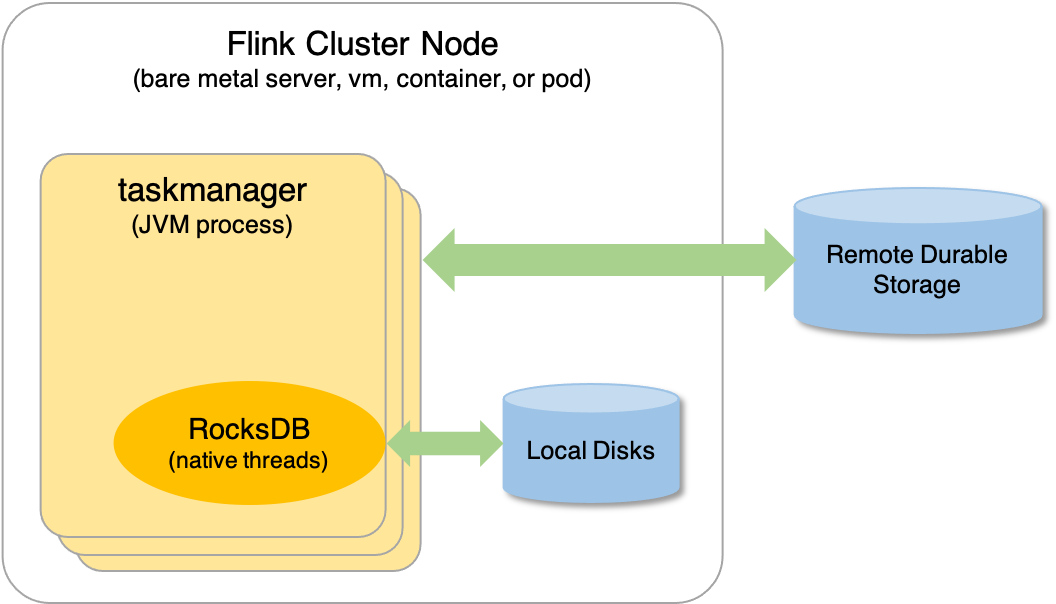
RocksDB in Flink #
Everything you need to use RocksDB as a state backend is bundled in the Apache Flink distribution, including the native shared library:
$ jar -tvf lib/flink-dist_2.12-1.12.0.jar| grep librocksdbjni-linux64
8695334 Wed Nov 27 02:27:06 CET 2019 librocksdbjni-linux64.so
At runtime, RocksDB is embedded in the TaskManager processes. It runs in native threads and works with local files. For example, if you have a job configured with RocksDBStateBackend running in your Flink cluster, you’ll see something similar to the following, where 32513 is the TaskManager process ID.
$ ps -T -p 32513 | grep -i rocksdb
32513 32633 ? 00:00:00 rocksdb:low0
32513 32634 ? 00:00:00 rocksdb:high0
When to use RocksDBStateBackend #
In addition to RocksDBStateBackend, Flink has two other built-in state backends: MemoryStateBackend and FsStateBackend. They both are heap-based, as in-flight state is stored in the JVM heap. For the moment being, let’s ignore MemoryStateBackend, as it is intended only for local developments and debugging, not for production use.
With RocksDBStateBackend, in-flight state is first written into off-heap/native memory, and then flushed to local disks when a configured threshold is reached. This means that RocksDBStateBackend can support state larger than the total configured heap capacity. The amount of state that you can store in RocksDBStateBackend is only limited by the amount of disk space available across the entire cluster. In addition, since RocksDBStateBackend doesn’t use the JVM heap to store in-flight state, it’s not affected by JVM Garbage Collection and therefore has predictable latency.
On top of full, self-contained state snapshots, RocksDBStateBackend also supports incremental checkpointing as a performance tuning option. An incremental checkpoint stores only the changes that occurred since the latest completed checkpoint. This dramatically reduces checkpointing time in comparison to performing a full snapshot. RocksDBStateBackend is currently the only state backend that supports incremental checkpointing.
RocksDB is a good option when:
- The state of your job is larger than can fit in local memory (e.g., long windows, large keyed state);
- You’re looking into incremental checkpointing as a way to reduce checkpointing time;
- You expect to have more predictable latency without being impacted by JVM Garbage Collection.
Otherwise, if your application has small state or requires very low latency, you should consider FsStateBackend. As a rule of thumb, RocksDBStateBackend is a few times slower than heap-based state backends, because it stores key/value pairs as serialized bytes. This means that any state access (reads/writes) needs to go through a de-/serialization process crossing the JNI boundary, which is more expensive than working directly with the on-heap representation of state. The upside is that, for the same amount of state, it has a low memory footprint compared to the corresponding on-heap representation.
How to use RocksDBStateBackend #
RocksDB is fully embedded within and fully managed by the TaskManager process. RocksDBStateBackend can be configured at the cluster level as the default for the entire cluster, or at the job level for individual jobs. The job level configuration takes precedence over the cluster level configuration.
Cluster Level #
Add the following configuration in conf/flink-conf.yaml:
state.backend: rocksdb
state.backend.incremental: true
state.checkpoints.dir: hdfs:///flink-checkpoints # location to store checkpoints
Job Level #
Add the following into your job’s code after StreamExecutionEnvironment is created:
# 'env' is the created StreamExecutionEnvironment
# 'true' is to enable incremental checkpointing
env.setStateBackend(new RocksDBStateBackend("hdfs:///fink-checkpoints", true));
Best Practices and Advanced Configuration #
We hope this overview helped you gain a better understanding of the role of RocksDB in Flink and how to successfully run a job with RocksDBStateBackend. To round it off, we’ll explore some best practices and a few reference points for further troubleshooting and performance tuning.
State Location in RocksDB #
As mentioned earlier, in-flight state in RocksDBStateBackend is spilled to files on disk. These files are located under the directory specified by the Flink configuration state.backend.rocksdb.localdir. Because disk performance has a direct impact on RocksDB’s performance, it’s recommended that this directory is located on a local disk. It’s discouraged to configure it to a remote network-based location like NFS or HDFS, as writing to remote disks is usually slower. Also high availability is not a requirement for in-flight state. Local SSD disks are preferred if high disk throughput is required.
State snapshots are persisted to remote durable storage. During state snapshotting, TaskManagers take a snapshot of the in-flight state and store it remotely. Transferring the state snapshot to remote storage is handled purely by the TaskManager itself without the involvement of the state backend. So, state.checkpoints.dir or the parameter you set in the code for a particular job can be different locations like an on-premises HDFS cluster or a cloud-based object store like Amazon S3, Azure Blob Storage, Google Cloud Storage, Alibaba OSS, etc.
Troubleshooting RocksDB #
To check how RocksDB is behaving in production, you should look for the RocksDB log file named LOG. By default, this log file is located in the same directory as your data files, i.e., the directory specified by the Flink configuration state.backend.rocksdb.localdir. When enabled, RocksDB statistics are also logged there to help diagnose potential problems. For further information, check RocksDB Troubleshooting Guide in RocksDB Wiki. If you are interested in the RocksDB behavior trend over time, you can consider enabling RocksDB native metrics for your Flink job.
Tuning RocksDB #
Since Flink 1.10, Flink configures RocksDB’s memory allocation to the amount of managed memory of each task slot by default. The primary mechanism for improving memory-related performance issues is to increase Flink’s managed memory via the Flink configuration taskmanager.memory.managed.size or taskmanager.memory.managed.fraction. For more fine-grained control, you should first disable the automatic memory management by setting state.backend.rocksdb.memory.managed to false, then start with the following Flink configuration: state.backend.rocksdb.block.cache-size (corresponding to block_cache_size in RocksDB), state.backend.rocksdb.writebuffer.size (corresponding to write_buffer_size in RocksDB), and state.backend.rocksdb.writebuffer.count (corresponding to max_write_buffer_number in RocksDB). For more details, check this blog post on how to manage RocksDB memory size in Flink and the RocksDB Memory Usage Wiki page.
While data is being written or overwritten in RocksDB, flushing from memory to local disks and data compaction are managed in the background by RocksDB threads. On a machine with many CPU cores, you should increase the parallelism of background flushing and compaction by setting the Flink configuration state.backend.rocksdb.thread.num (corresponding to max_background_jobs in RocksDB). The default configuration is usually too small for a production setup. If your job reads frequently from RocksDB, you should consider enabling bloom filters.
For other RocksDBStateBackend configurations, check the Flink documentation on Advanced RocksDB State Backends Options. For further tuning, check RocksDB Tuning Guide in RocksDB Wiki.
Conclusion #
The RocksDB state backend (i.e., RocksDBStateBackend) is one of the three state backends bundled in Flink, and can be a powerful choice when configuring your streaming applications. It enables scalable applications maintaining up to many terabytes of state with exactly-once processing guarantees. If the state of your Flink job is too large to fit on the JVM heap, you are interested in incremental checkpointing, or you expect to have predictable latency, you should use RocksDBStateBackend. Since RocksDB is embedded in TaskManager processes as native threads and works with files on local disks, RocksDBStateBackend is supported out-of-the-box without the need to further setup and manage any external systems or processes.