FLIP-147: Support Checkpoints After Tasks Finished - Part One
July 11, 2022 - Yun Gao Dawid Wysakowicz Daisy TsangMotivation #
Flink is a distributed processing engine for both unbounded and bounded streams of data. In recent versions, Flink has unified the DataStream API and the Table / SQL API to support both streaming and batch cases. Since most users require both types of data processing pipelines, the unification helps reduce the complexity of developing, operating, and maintaining consistency between streaming and batch backfilling jobs, like the case for Alibaba.
Flink provides two execution modes under the unified programming API: the streaming mode and the batch mode. The streaming mode processes records incrementally based on the states, thus it supports both bounded and unbounded sources. The batch mode works with bounded sources and usually has a better performance for bounded jobs because it executes all the tasks in topological order and avoids random state access by pre-sorting the input records. Although batch mode is often the preferred mode to process bounded jobs, streaming mode is also required for various reasons. For example, users may want to deal with records containing retraction or exploit the property that data is roughly sorted by event times in streaming mode (like the case in Kappa+ Architecture). Moreover, users often have mixed jobs involving both unbounded streams and bounded side-inputs, which also require streaming execution mode.
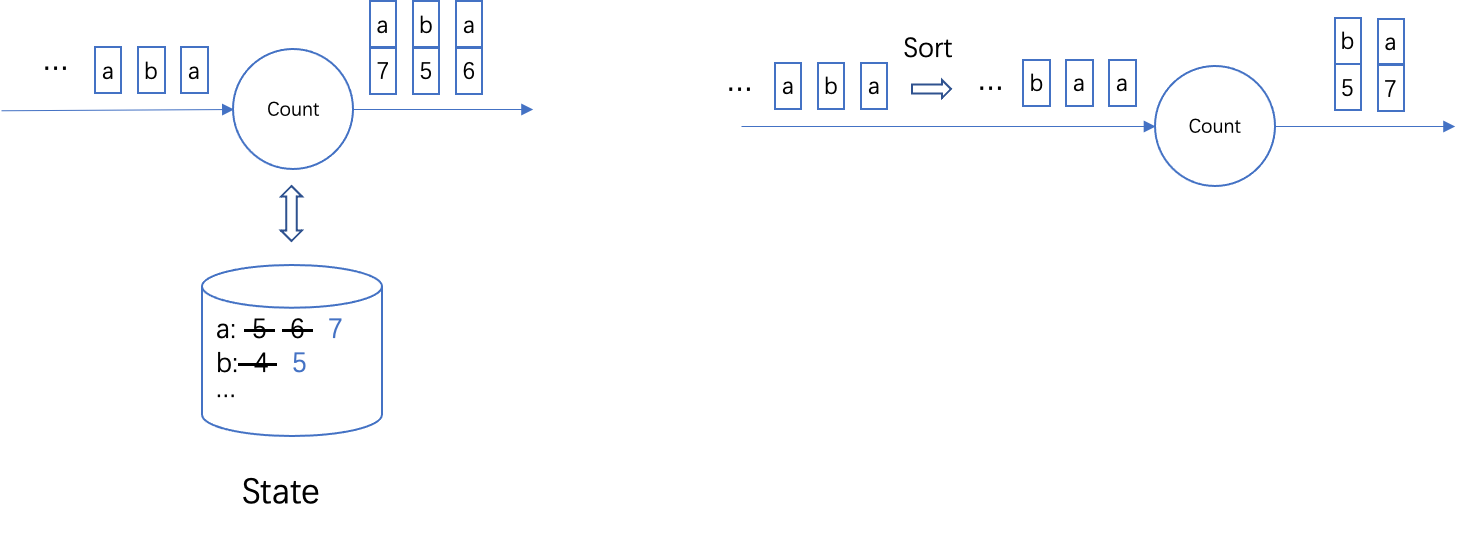
Figure 1. A comparison of the Streaming mode and Batch mode for the example Count operator. For streaming mode, the arrived elements are not sorted, the operator would read / write the state corresponding to the element for computation. For batch mode, the arrived elements are first sorted as a whole and then processed.
In streaming mode, checkpointing is the vital mechanism in supporting exactly-once guarantees. By periodically snapshotting the aligned states of operators, Flink can recover from the latest checkpoint and continue execution when failover happens. However, previously Flink could not take checkpoints if any task gets finished. This would cause problems for jobs with both bounded and unbounded sources: if there are no checkpoints after the bounded part finished, the unbounded part might need to reprocess a large amount of records in case of a failure.
Furthermore, being unable to take checkpoints with finished tasks is a problem for jobs using two-phase-commit sinks to achieve end-to-end exactly-once processing. The two-phase-commit sinks first write data to temporary files or external transactions, and commit the data only after a checkpoint completes to ensure the data would not be replayed on failure. However, if a job contains bounded sources, committing the results would not be possible after the bounded sources finish. Also because of that, for bounded jobs we have no way to commit the last piece of data after the first source task finished, and previously the bounded jobs just ignore the uncommitted data when finishing. These behaviors caused a lot of confusion and are always asked in the user mailing list.
Therefore, to complete the support of streaming mode for jobs using bounded sources, it is important for us to
- Support taking checkpoints with finished tasks.
- Furthermore, revise the process of finishing so that all the data could always be committed.
The remaining blog briefly describes the changes we made to achieve the above goals. In the next blog, we’ll share more details on how they are implemented.
Support Checkpointing with Finished Tasks #
The core idea of supporting checkpoints with finished tasks is to mark the finished operators in checkpoints and skip executing these operators after recovery. As illustrated in Figure 2, a checkpoint is composed of the states of all the operators. If all the subtasks of an operator have finished, we could mark it as fully finished and skip the execution of this operator on startup. For other operators, their states are composed of the states of all the running subtasks. The states will be repartitioned on restarting and all the new subtasks restarted with the assigned states.
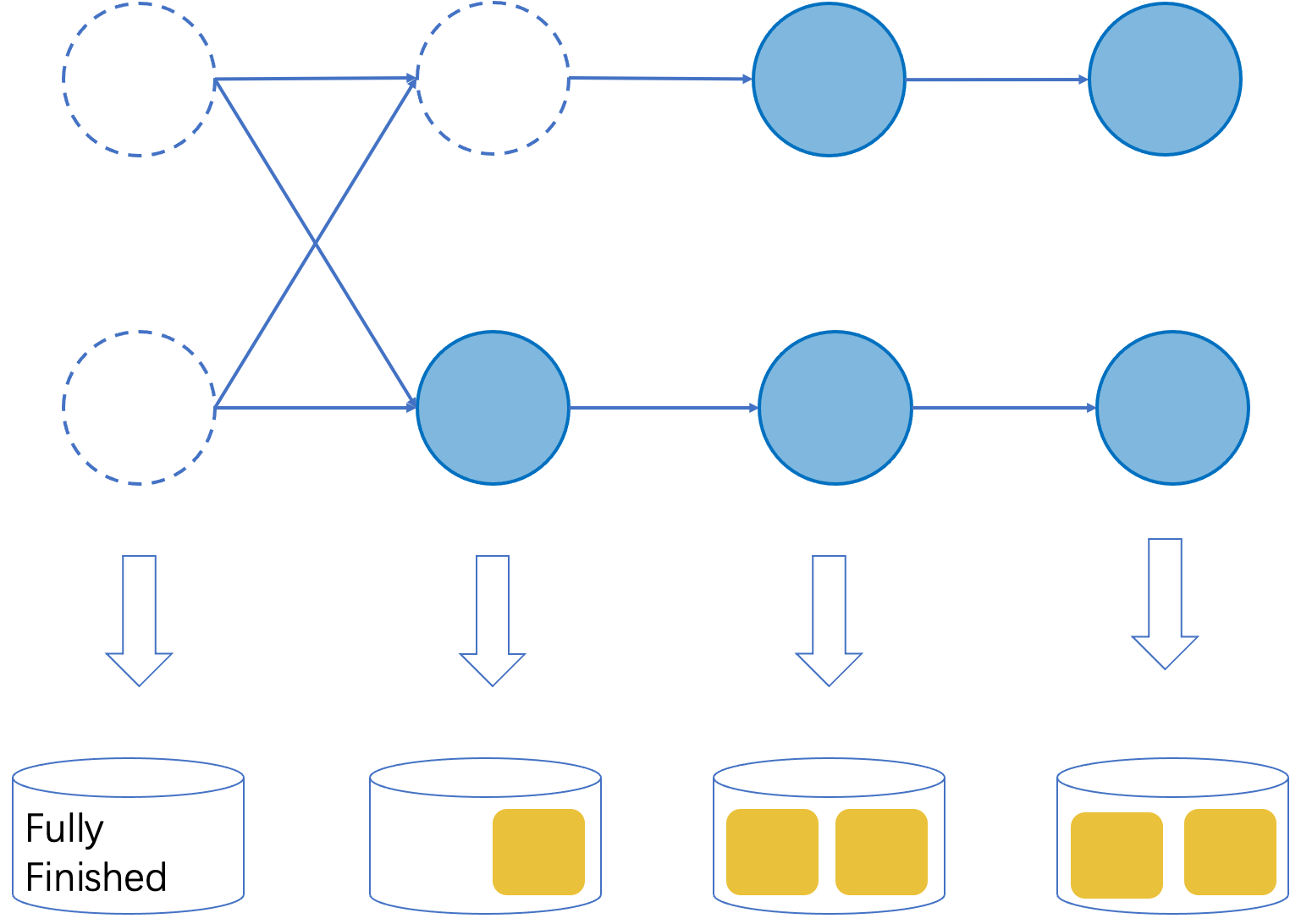
Figure 2. An illustration of the extended checkpoint format.
To support creating such a checkpoint for jobs with finished tasks, we extended the checkpoint procedure. Previously the checkpoint coordinator inside the JobManager first notifies all the sources to report snapshots, then all the sources further notify their descendants via broadcasting barrier events. Since now the sources might have already finished, the checkpoint coordinator would instead treat the running tasks who also do not have running precedent tasks as “new sources”, and it notifies these tasks to initiate the checkpoints. Finally, if the subtasks of an operator are either finished on triggering checkpoint or have finished processing all the data on snapshotting states, the operator would be marked as fully finished.
The changes of the checkpoint procedure are transparent to users except that for checkpoints indeed containing finished tasks, we disallowed adding new operators as precedents of the fully finished ones, since it would make the fully finished operators have running precedents after restarting, which conflicts with the design that tasks finished in topological order.
Revise the Process of Finishing #
Based on the ability to take checkpoints with finished tasks, we could then solve the issue that two-phase-commit operators could not commit all the data when running in streaming mode. As the background, Flink jobs have two ways to finish:
- All sources are bound and they processed all the input records. The job will finish after all the input records are processed and all the result are committed to external systems.
- Users execute
stop-with-savepoint [--drain]. The job will take a savepoint and then finish. With–-drain, the job will be stopped permanently and is also required to commit all the data. However, without--drainthe job might be resumed from the savepoint later, thus not all data are required to be committed, as long as the state of the data could be recovered from the savepoint.
Let’s first have a look at the case of bounded sources. To achieve end-to-end exactly-once, two-phase-commit operators only commit data after a checkpoint following this piece of data succeeded. However, previously there is no such an opportunity for the data between the last periodic checkpoint and job getting finished, and the data finally gets lost. Note that it is also not correct if we directly commit the data on job finished, since if there are failovers after that (like due to other unfinished tasks getting failed), the data will be replayed and cause duplication.
The case of stop-with-savepoint --drain also has problems. The previous implementation first stalls the execution and
takes a savepoint. After the savepoint succeeds, all the source tasks would stop actively. Although the savepoint seems to
provide the opportunity to commit all the data, some processing logic is in fact executed during the job getting stopped,
and the records produced would be discarded by mistake. For example, calling endInput() method for operators happens during
the stopping phase, some operators like the async operator might still emit new records in this method.
At last, although stop-with-savepoint without draining is not required to commit all the data, we hope the job finish process could
be unified for all the cases to keep the code clean.
To fix the remaining issues, we need to modify the process of finishing to ensure all the data getting committed for the required cases. An intuitive idea is to directly insert a step to the tasks’ lifecycle to wait for the next checkpoint, as shown in the left part of Figure 3. However, it could not solve all the issues.

Figure 3. A comparison of the two options to ensure tasks committed all the data before getting finished. The first option directly inserts a step in the tasks’ lifecycle to wait for the next checkpoint, which disallows the tasks to wait for the same checkpoint / savepoint. The second option decouples the notification of finishing operator logic and finishing tasks, thus it allows all the tasks to first process all records, then they have the chance to wait for the same checkpoint / savepoint.
For the case of bounded sources, the intuitive idea works, but it might have performance issues in some cases: as exemplified in Figure 4, If there are multiple cascading tasks containing two-phase commit sinks, each task would wait for the next checkpoint separately, thus the job needs to wait for three more checkpoints during finishing, which might prolong the total execution time for a long time.
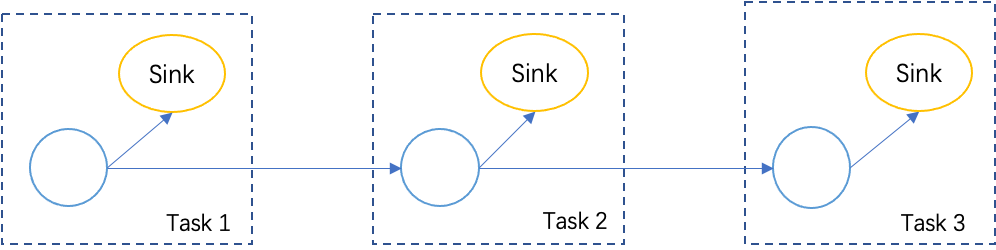
Figure 4. An example job that contains a chain of tasks containing two-phase-commit operators.
For the case of stop-with-savepoint [--drain], the intuitive idea does not work since different tasks have to
wait for different checkpoints / savepoints, thus we could not finish the job with a specific savepoint.
Therefore, we do not take the intuitive option. Instead, we decoupled “finishing operator logic” and “finishing tasks”:
all the tasks would first finish their execution logic as a whole, including calling lifecycle methods like endInput(),
then each task could wait for the next checkpoint concurrently. Besides, for stop-with-savepoint we also reverted the current
implementation similarly: all the tasks will first finish executing the operators’ logic, then they simply wait for the next savepoint
to happen before finish. Therefore, in this way the finishing processes are unified and the data could be fully committed for all the cases.
Based on this thought, as shown in the right part of Figure 3, to decoupled the process of “finishing operator logic”
and “finishing tasks”, we introduced a new EndOfData event. For each task, after executing all the operator logic it would first notify
the descendants with an EndOfData event so that the descendants also have chances to finish executing the operator logic. Then all
the tasks could wait for the next checkpoint or the specified savepoint concurrently to commit all the remaining data before getting finished.
At last, it is also worthy to mention we have clarified and renamed the close() and dispose() methods in the operators’ lifecycle.
The two methods are in fact different since close() is only called when the task finishes normally and dispose() is called in both
cases of normal finishing and failover. However, this was not clear from their names. Therefore, we rename the two methods to finish() and close():
finish()marks the termination of the operator and no more records are allowed afterfinish()is called. It should only be called when sources are finished or when the-–drainparameter is specified.close()is used to do cleanup and release all the held resources.
Conclusion #
By supporting the checkpoints after tasks finished and revising the process of finishing, we can support checkpoints for jobs with both bounded and unbounded sources, and ensure the bounded job gets all output records committed before it finishes. The motivation behind this change is to ensure data consistency, results completeness, and failure recovery if there are bounded sources in the pipeline. The final checkpoint mechanism was first implemented in Flink 1.14 and enabled by default in Flink 1.15. If you have any questions, please feel free to start a discussion or report an issue in the dev or user mailing list.