Apache Flink Table Store 0.2.0 Release Announcement
August 29, 2022 - Jingsong Lee
The Apache Flink community is pleased to announce the release of the Apache Flink Table Store (0.2.0).
Please check out the full documentation for detailed information and user guides.
What is Flink Table Store #
Flink Table Store is a data lake storage for streaming updates/deletes changelog ingestion and high-performance queries in real time.
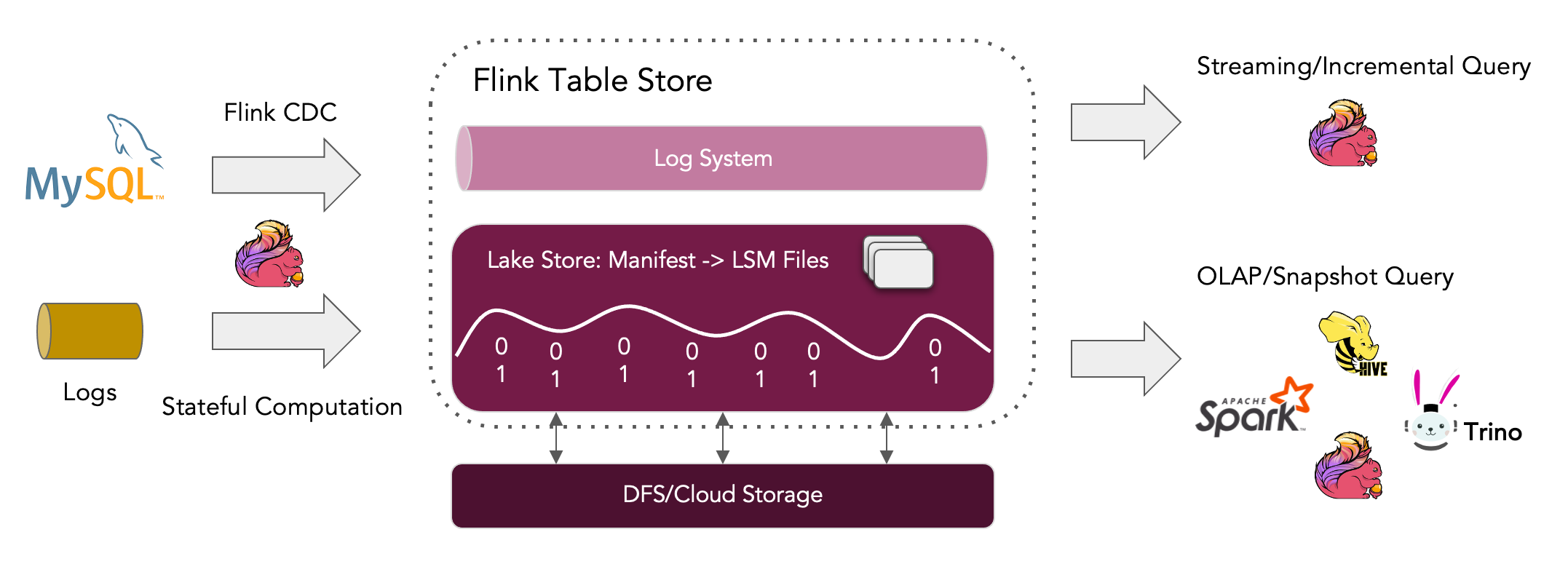
As a new type of updatable data lake, Flink Table Store has the following features:
- Large throughput data ingestion while offering good query performance.
- High performance query with primary key filters, as fast as 100ms.
- Streaming reads are available on Lake Storage, lake storage can also be integrated with Kafka to provide second-level streaming reads.
Notable Features #
In this release, we have accomplished many exciting features.
Catalog #
This release introduces Table Store’s own catalog and supports automatic synchronization to the Hive Metastore.
CREATE CATALOG tablestore WITH (
'type'='table-store',
'warehouse'='hdfs://nn:8020/warehouse/path',
-- optional hive metastore
'metastore'='hive',
'uri'='thrift://<hive-metastore-host-name>:<port>'
);
USE CATALOG tablestore;
CREATE TABLE my_table ...
Ecosystem #
In this release, we provide support for Flink 1.14 and provide read support for multiple compute engines.
| Engine | Version | Feature | Read Pushdown |
|---|---|---|---|
| Flink | 1.14 | read, write | Projection, Filter |
| Flink | 1.15 | read, write | Projection, Filter |
| Hive | 2.3 | read | Projection, Filter |
| Spark | 2.4 | read | Projection, Filter |
| Spark | 3.0 | read | Projection, Filter |
| Spark | 3.1 | read | Projection, Filter |
| Spark | 3.2 | read | Projection, Filter |
| Spark | 3.3 | read | Projection, Filter |
| Trino | 358 | read | Projection, Filter |
| Trino | 388 | read | Projection, Filter |
Append-only #
The append-only table feature is a performance improvement and only accepts INSERT_ONLY data to append to the storage instead of updating or de-duplicating the existing data, and hence suitable for use cases that do not require updates (such as log data synchronization).
CREATE TABLE my_table (
...
) WITH (
'write-mode' = 'append-only',
...
)
Streaming writing to an Append-only table also has asynchronous compaction, so you don’t have to worry about small files.
Rescale Bucket #
Since the number of total buckets dramatically influences the performance, Table Store allows
users to tune bucket numbers by ALTER TABLE command and reorganize necessary partitions,
the old partitions remain unchanged.
Getting started #
Please refer to the getting started guide for more details.
What’s Next? #
In the upcoming 0.3.0 release you can expect the following additional features:
- Streaming Changelog Concurrent Writes, the separation of Compaction.
- Aggregation Table, to build your materialized view.
- Changelog producing for partial-update/aggregation Tables.
- Full Schema Evolution supports for drop column and rename column.
- Lookup Supports for Flink Dim Join.
Please give the release a try, share your feedback on the Flink mailing list and contribute to the project!
We encourage you to download the release and share your feedback with the community through the Flink mailing lists or JIRA.
List of Contributors #
The Apache Flink community would like to thank every one of the contributors that have made this release possible:
Jane Chan, Jia Liu, Jingsong Lee, liliwei, Nicholas Jiang, openinx, tsreaper