Announcing Apache Flink 0.10.0
November 16, 2015 -The Apache Flink community is pleased to announce the availability of the 0.10.0 release. The community put significant effort into improving and extending Apache Flink since the last release, focusing on data stream processing and operational features. About 80 contributors provided bug fixes, improvements, and new features such that in total more than 400 JIRA issues could be resolved.
For Flink 0.10.0, the focus of the community was to graduate the DataStream API from beta and to evolve Apache Flink into a production-ready stream data processor with a competitive feature set. These efforts resulted in support for event-time and out-of-order streams, exactly-once guarantees in the case of failures, a very flexible windowing mechanism, sophisticated operator state management, and a highly-available cluster operation mode. Flink 0.10.0 also brings a new monitoring dashboard with real-time system and job monitoring capabilities. Both batch and streaming modes of Flink benefit from the new high availability and improved monitoring features. Needless to say that Flink 0.10.0 includes many more features, improvements, and bug fixes.
We encourage everyone to download the release and check out the documentation. Feedback through the Flink mailing lists is, as always, very welcome!
New Features #
Event-time Stream Processing #
Many stream processing applications consume data from sources that produce events with associated timestamps such as sensor or user-interaction events. Very often, events have to be collected from several sources such that it is usually not guaranteed that events arrive in the exact order of their timestamps at the stream processor. Consequently, stream processors must take out-of-order elements into account in order to produce results which are correct and consistent with respect to the timestamps of the events. With release 0.10.0, Apache Flink supports event-time processing as well as ingestion-time and processing-time processing. See FLINK-2674 for details.
Stateful Stream Processing #
Operators that maintain and update state are a common pattern in many stream processing applications. Since streaming applications tend to run for a very long time, operator state can become very valuable and impossible to recompute. In order to enable fault-tolerance, operator state must be backed up to persistent storage in regular intervals. Flink 0.10.0 offers flexible interfaces to define, update, and query operator state and hooks to connect various state backends.
Highly-available Cluster Operations #
Stream processing applications may be live for months. Therefore, a production-ready stream processor must be highly-available and continue to process data even in the face of failures. With release 0.10.0, Flink supports high availability modes for standalone cluster and YARN setups, eliminating any single point of failure. In this mode, Flink relies on Apache Zookeeper for leader election and persisting small sized meta-data of running jobs. You can check out the documentation to see how to enable high availability. See FLINK-2287 for details.
Graduated DataStream API #
The DataStream API was revised based on user feedback and with foresight for upcoming features and graduated from beta status to fully supported. The most obvious changes are related to the methods for stream partitioning and window operations. The new windowing system is based on the concepts of window assigners, triggers, and evictors, inspired by the Dataflow Model. The new API is fully described in the DataStream API documentation. This migration guide will help to port your Flink 0.9 DataStream programs to the revised API of Flink 0.10.0. See FLINK-2674 and FLINK-2877 for details.
New Connectors for Data Streams #
Apache Flink 0.10.0 features DataStream sources and sinks for many common data producers and stores. This includes an exactly-once rolling file sink which supports any file system, including HDFS, local FS, and S3. We also updated the Apache Kafka producer to use the new producer API, and added a connectors for ElasticSearch and Apache Nifi. More connectors for DataStream programs will be added by the community in the future. See the following JIRA issues for details FLINK-2583, FLINK-2386, FLINK-2372, FLINK-2740, and FLINK-2558.
New Web Dashboard & Real-time Monitoring #
The 0.10.0 release features a newly designed and significantly improved monitoring dashboard for Apache Flink. The new dashboard visualizes the progress of running jobs and shows real-time statistics of processed data volumes and record counts. Moreover, it gives access to resource usage and JVM statistics of TaskManagers including JVM heap usage and garbage collection details. The following screenshot shows the job view of the new dashboard.
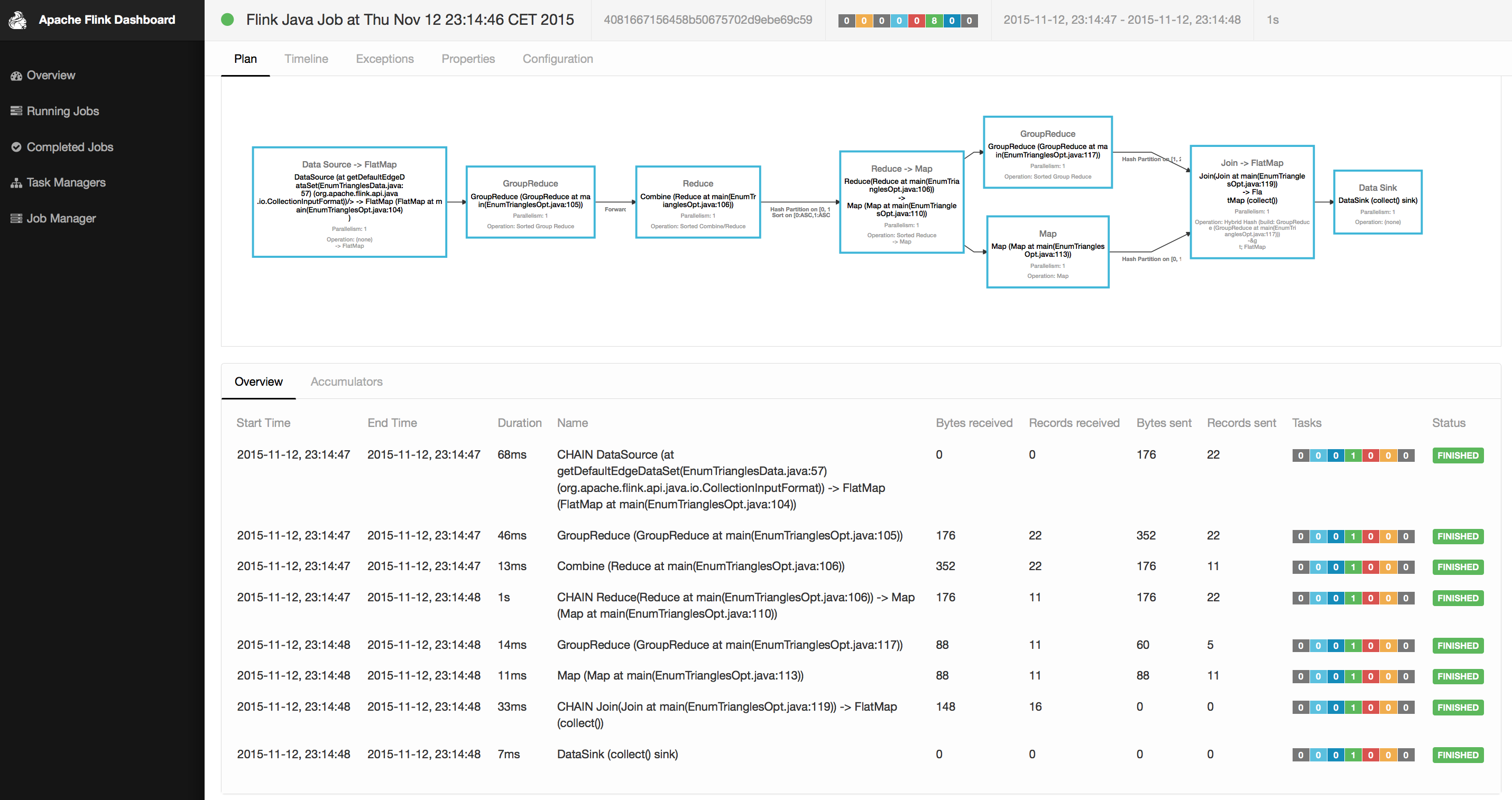
The web server that provides all monitoring statistics has been designed with a REST interface allowing other systems to also access the internal system metrics. See FLINK-2357 for details.
Off-heap Managed Memory #
Flink’s internal operators (such as its sort algorithm and hash tables) write data to and read data from managed memory to achieve memory-safe operations and reduce garbage collection overhead. Until version 0.10.0, managed memory was allocated only from JVM heap memory. With this release, managed memory can also be allocated from off-heap memory. This will facilitate shorter TaskManager start-up times as well as reduce garbage collection pressure. See the documentation to learn how to configure managed memory on off-heap memory. JIRA issue FLINK-1320 contains further details.
Outer Joins #
Outer joins have been one of the most frequently requested features for Flink’s DataSet API. Although there was a workaround to implement outer joins as CoGroup function, it had significant drawbacks including added code complexity and not being fully memory-safe. With release 0.10.0, Flink adds native support for left, right, and full outer joins to the DataSet API. All outer joins are backed by a memory-safe operator implementation that leverages Flink’s managed memory. See FLINK-687 and FLINK-2107 for details.
Gelly: Major Improvements and Scala API #
Gelly is Flink’s API and library for processing and analyzing large-scale graphs. Gelly was introduced with release 0.9.0 and has been very well received by users and contributors. Based on user feedback, Gelly has been improved since then. In addition, Flink 0.10.0 introduces a Scala API for Gelly. See FLINK-2857 and FLINK-1962 for details.
More Improvements and Fixes #
The Flink community resolved more than 400 issues. The following list is a selection of new features and fixed bugs.
- FLINK-1851 Java Table API does not support Casting
- FLINK-2152 Provide zipWithIndex utility in flink-contrib
- FLINK-2158 NullPointerException in DateSerializer.
- FLINK-2240 Use BloomFilter to minimize probe side records which are spilled to disk in Hybrid-Hash-Join
- FLINK-2533 Gap based random sample optimization
- FLINK-2555 Hadoop Input/Output Formats are unable to access secured HDFS clusters
- FLINK-2565 Support primitive arrays as keys
- FLINK-2582 Document how to build Flink with other Scala versions
- FLINK-2584 ASM dependency is not shaded away
- FLINK-2689 Reusing null object for joins with SolutionSet
- FLINK-2703 Remove log4j classes from fat jar / document how to use Flink with logback
- FLINK-2763 Bug in Hybrid Hash Join: Request to spill a partition with less than two buffers.
- FLINK-2767 Add support Scala 2.11 to Scala shell
- FLINK-2774 Import Java API classes automatically in Flink’s Scala shell
- FLINK-2782 Remove deprecated features for 0.10
- FLINK-2800 kryo serialization problem
- FLINK-2834 Global round-robin for temporary directories
- FLINK-2842 S3FileSystem is broken
- FLINK-2874 Certain Avro generated getters/setters not recognized
- FLINK-2895 Duplicate immutable object creation
- FLINK-2964 MutableHashTable fails when spilling partitions without overflow segments
Notice #
As previously announced, Flink 0.10.0 no longer supports Java 6. If you are still using Java 6, please consider upgrading to Java 8 (Java 7 ended its free support in April 2015).
Also note that some methods in the DataStream API had to be renamed as part of the API rework. For example the groupBy method has been renamed to keyBy and the windowing API changed. This migration guide will help to port your Flink 0.9 DataStream programs to the revised API of Flink 0.10.0.
Contributors #
- Alexander Alexandrov
- Marton Balassi
- Enrique Bautista
- Faye Beligianni
- Bryan Bende
- Ajay Bhat
- Chris Brinkman
- Dmitry Buzdin
- Kun Cao
- Paris Carbone
- Ufuk Celebi
- Shivani Chandna
- Liang Chen
- Felix Cheung
- Hubert Czerpak
- Vimal Das
- Behrouz Derakhshan
- Suminda Dharmasena
- Stephan Ewen
- Fengbin Fang
- Gyula Fora
- Lun Gao
- Gabor Gevay
- Piotr Godek
- Sachin Goel
- Anton Haglund
- Gábor Hermann
- Greg Hogan
- Fabian Hueske
- Martin Junghanns
- Vasia Kalavri
- Ulf Karlsson
- Frederick F. Kautz
- Samia Khalid
- Johannes Kirschnick
- Kostas Kloudas
- Alexander Kolb
- Johann Kovacs
- Aljoscha Krettek
- Sebastian Kruse
- Andreas Kunft
- Chengxiang Li
- Chen Liang
- Andra Lungu
- Suneel Marthi
- Tamara Mendt
- Robert Metzger
- Maximilian Michels
- Chiwan Park
- Sahitya Pavurala
- Pietro Pinoli
- Ricky Pogalz
- Niraj Rai
- Lokesh Rajaram
- Johannes Reifferscheid
- Till Rohrmann
- Henry Saputra
- Matthias Sax
- Shiti Saxena
- Chesnay Schepler
- Peter Schrott
- Saumitra Shahapure
- Nikolaas Steenbergen
- Thomas Sun
- Peter Szabo
- Viktor Taranenko
- Kostas Tzoumas
- Pieter-Jan Van Aeken
- Theodore Vasiloudis
- Timo Walther
- Chengxuan Wang
- Huang Wei
- Dawid Wysakowicz
- Rerngvit Yanggratoke
- Nezih Yigitbasi
- Ted Yu
- Rucong Zhang
- Vyacheslav Zholudev
- Zoltán Zvara