Apache Flink 1.10.0 Release Announcement
February 11, 2020 - Marta Paes (@morsapaes)The Apache Flink community is excited to hit the double digits and announce the release of Flink 1.10.0! As a result of the biggest community effort to date, with over 1.2k issues implemented and more than 200 contributors, this release introduces significant improvements to the overall performance and stability of Flink jobs, a preview of native Kubernetes integration and great advances in Python support (PyFlink).
Flink 1.10 also marks the completion of the Blink integration, hardening streaming SQL and bringing mature batch processing to Flink with production-ready Hive integration and TPC-DS coverage. This blog post describes all major new features and improvements, important changes to be aware of and what to expect moving forward.
The binary distribution and source artifacts are now available on the updated Downloads page of the Flink website. For more details, check the complete release changelog and the updated documentation. We encourage you to download the release and share your feedback with the community through the Flink mailing lists or JIRA.
New Features and Improvements #
Improved Memory Management and Configuration #
The current TaskExecutor memory configuration in Flink has some shortcomings that make it hard to reason about or optimize resource utilization, such as:
-
Different configuration models for memory footprint in Streaming and Batch execution;
-
Complex and user-dependent configuration of off-heap state backends (i.e. RocksDB) in Streaming execution.
To make memory options more explicit and intuitive to users, Flink 1.10 introduces significant changes to the TaskExecutor memory model and configuration logic (FLIP-49). These changes make Flink more adaptable to all kinds of deployment environments (e.g. Kubernetes, Yarn, Mesos), giving users strict control over its memory consumption.
Managed Memory Extension
Managed memory was extended to also account for memory usage of RocksDBStateBackend. While batch jobs can use either on-heap or off-heap memory, streaming jobs with RocksDBStateBackend can use off-heap memory only. Therefore, to allow users to switch between Streaming and Batch execution without having to modify cluster configurations, managed memory is now always off-heap.
Simplified RocksDB Configuration
Configuring an off-heap state backend like RocksDB used to involve a good deal of manual tuning, like decreasing the JVM heap size or setting Flink to use off-heap memory. This can now be achieved through Flink’s out-of-box configuration, and adjusting the memory budget for RocksDBStateBackend is as simple as resizing the managed memory size.
Another important improvement was to allow Flink to bind RocksDB native memory usage (FLINK-7289), preventing it from exceeding its total memory budget — this is especially relevant in containerized environments like Kubernetes. For details on how to enable and tune this feature, refer to Tuning RocksDB.
Note FLIP-49 changes the process of cluster resource configuration, which may require tuning your clusters for upgrades from previous Flink versions. For a comprehensive overview of the changes introduced and tuning guidance, consult this setup.
Unified Logic for Job Submission #
Prior to this release, job submission was part of the duties of the Execution Environments and closely tied to the different deployment targets (e.g. Yarn, Kubernetes, Mesos). This led to a poor separation of concerns and, over time, to a growing number of customized environments that users needed to configure and manage separately.
In Flink 1.10, job submission logic is abstracted into the generic Executor interface (FLIP-73). The addition of the ExecutorCLI (FLIP-81) introduces a unified way to specify configuration parameters for any execution target. To round up this effort, the process of result retrieval was also decoupled from job submission with the introduction of a JobClient (FLINK-74), responsible for fetching the JobExecutionResult.
In particular, these changes make it much easier to programmatically use Flink in downstream frameworks — for example, Apache Beam or Zeppelin interactive notebooks — by providing users with a unified entry point to Flink. For users working with Flink across multiple target environments, the transition to a configuration-based execution process also significantly reduces boilerplate code and maintainability overhead.
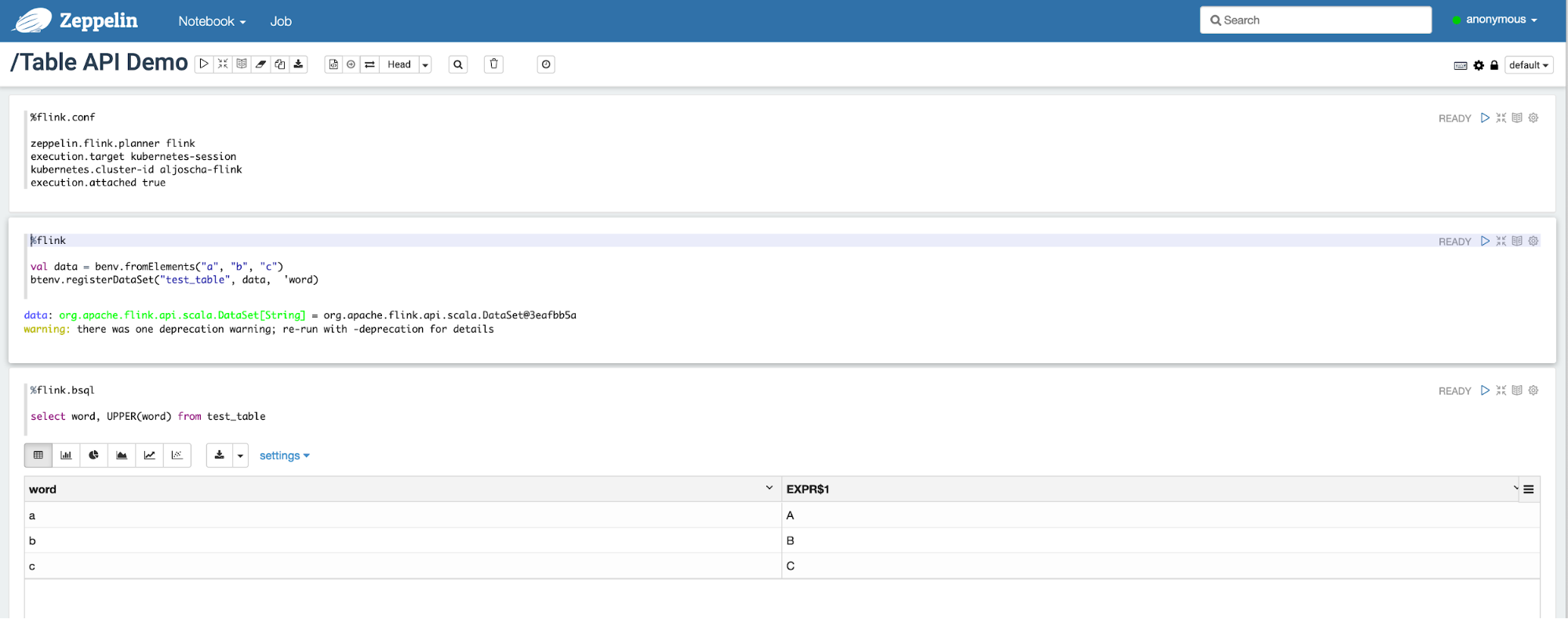
Native Kubernetes Integration (Beta) #
For users looking to get started with Flink on a containerized environment, deploying and managing a standalone cluster on top of Kubernetes requires some upfront knowledge about containers, operators and environment-specific tools like kubectl.
In Flink 1.10, we rolled out the first phase of Active Kubernetes Integration (FLINK-9953) with support for session clusters (with per-job planned). In this context, “active” means that Flink’s ResourceManager (K8sResMngr) natively communicates with Kubernetes to allocate new pods on-demand, similar to Flink’s Yarn and Mesos integration. Users can also leverage namespaces to launch Flink clusters for multi-tenant environments with limited aggregate resource consumption. RBAC roles and service accounts with enough permission should be configured beforehand.
As introduced in Unified Logic For Job Submission, all command-line options in Flink 1.10 are mapped to a unified configuration. For this reason, users can simply refer to the Kubernetes config options and submit a job to an existing Flink session on Kubernetes in the CLI using:
./bin/flink run -d -e kubernetes-session -Dkubernetes.cluster-id=<ClusterId> examples/streaming/WindowJoin.jar
If you want to try out this preview feature, we encourage you to walk through the Native Kubernetes setup, play around with it and share feedback with the community.
Table API/SQL: Production-ready Hive Integration #
Hive integration was announced as a preview feature in Flink 1.9. This preview allowed users to persist Flink-specific metadata (e.g. Kafka tables) in Hive Metastore using SQL DDL, call UDFs defined in Hive and use Flink for reading and writing Hive tables. Flink 1.10 rounds up this effort with further developments that bring production-ready Hive integration to Flink with full compatibility of most Hive versions.
Native Partition Support for Batch SQL #
So far, only writes to non-partitioned Hive tables were supported. In Flink 1.10, the Flink SQL syntax has been extended with INSERT OVERWRITE and PARTITION (FLIP-63), enabling users to write into both static and dynamic partitions in Hive.
Static Partition Writing
INSERT { INTO | OVERWRITE } TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
Dynamic Partition Writing
INSERT { INTO | OVERWRITE } TABLE tablename1 select_statement1 FROM from_statement;
Fully supporting partitioned tables allows users to take advantage of partition pruning on read, which significantly increases the performance of these operations by reducing the amount of data that needs to be scanned.
Further Optimizations #
Besides partition pruning, Flink 1.10 introduces more read optimizations to Hive integration, such as:
-
Projection pushdown: Flink leverages projection pushdown to minimize data transfer between Flink and Hive tables by omitting unnecessary fields from table scans. This is especially beneficial for tables with a large number of columns.
-
LIMIT pushdown: for queries with the
LIMITclause, Flink will limit the number of output records wherever possible to minimize the amount of data transferred across the network. -
ORC Vectorization on Read: to boost read performance for ORC files, Flink now uses the native ORC Vectorized Reader by default for Hive versions above 2.0.0 and columns with non-complex data types.
Pluggable Modules as Flink System Objects (Beta) #
Flink 1.10 introduces a generic mechanism for pluggable modules in the Flink table core, with a first focus on system functions (FLIP-68). With modules, users can extend Flink’s system objects — for example use Hive built-in functions that behave like Flink system functions. This release ships with a pre-implemented HiveModule, supporting multiple Hive versions, but users are also given the possibility to write their own pluggable modules.
Other Improvements to the Table API/SQL #
Watermarks and Computed Columns in SQL DDL #
Flink 1.10 supports stream-specific syntax extensions to define time attributes and watermark generation in Flink SQL DDL (FLIP-66). This allows time-based operations, like windowing, and the definition of watermark strategies on tables created using DDL statements.
CREATE TABLE table_name (
WATERMARK FOR columnName AS <watermark_strategy_expression>
) WITH (
...
)
This release also introduces support for virtual computed columns (FLIP-70) that can be derived based on other columns in the same table or deterministic expressions (i.e. literal values, UDFs and built-in functions). In Flink, computed columns are useful to define time attributes upon table creation.
Additional Extensions to SQL DDL #
There is now a clear distinction between temporary/persistent and system/catalog functions (FLIP-57). This not only eliminates ambiguity in function reference, but also allows for deterministic function resolution order (i.e. in case of naming collision, system functions will precede catalog functions, with temporary functions taking precedence over persistent functions for both dimensions).
Following the groundwork in FLIP-57, we extended the SQL DDL syntax to support the creation of catalog functions, temporary functions and temporary system functions (FLIP-79):
CREATE [TEMPORARY|TEMPORARY SYSTEM] FUNCTION
[IF NOT EXISTS] [catalog_name.][db_name.]function_name
AS identifier [LANGUAGE JAVA|SCALA]
For a complete overview of the current state of DDL support in Flink SQL, check the updated documentation.
Note In order to correctly handle and guarantee a consistent behavior across meta-objects (tables, views, functions) in the future, some object declaration methods in the Table API have been deprecated in favor of methods that are closer to standard SQL DDL (FLIP-64).
Full TPC-DS Coverage for Batch #
TPC-DS is a widely used industry-standard decision support benchmark to evaluate and measure the performance of SQL-based data processing engines. In Flink 1.10, all TPC-DS queries are supported end-to-end (FLINK-11491), reflecting the readiness of its SQL engine to address the needs of modern data warehouse-like workloads.
PyFlink: Support for Native User Defined Functions (UDFs) #
A preview of PyFlink was introduced in the previous release, making headway towards the goal of full Python support in Flink. For this release, the focus was to enable users to register and use Python User-Defined Functions (UDF, with UDTF/UDAF planned) in the Table API/SQL (FLIP-58).

If you are interested in the underlying implementation — leveraging Apache Beam’s Portability Framework — refer to the “Architecture” section of FLIP-58 and also to FLIP-78. These data structures lay the required foundation for Pandas support and for PyFlink to eventually reach the DataStream API.
From Flink 1.10, users can also easily install PyFlink through pip using:
pip install apache-flink
For a preview of other improvements planned for PyFlink, check FLINK-14500 and get involved in the discussion for requested user features.
Important Changes #
-
[FLINK-10725] Flink can now be compiled and run on Java 11.
-
[FLINK-15495] The Blink planner is now the default in the SQL Client, so that users can benefit from all the latest features and improvements. The switch from the old planner in the Table API is also planned for the next release, so we recommend that users start getting familiar with the Blink planner.
-
[FLINK-13025] There is a new Elasticsearch sink connector, fully supporting Elasticsearch 7.x versions.
-
[FLINK-15115] The connectors for Kafka 0.8 and 0.9 have been marked as deprecated and will no longer be actively supported. If you are still using these versions or have any other related concerns, please reach out to the @dev mailing list.
-
[FLINK-14516] The non-credit-based network flow control code was removed, along with the configuration option
taskmanager.network.credit.model. Moving forward, Flink will always use credit-based flow control. -
[FLINK-12122] FLIP-6 was rolled out with Flink 1.5.0 and introduced a code regression related to the way slots are allocated from
TaskManagers. To use a scheduling strategy that is closer to the pre-FLIP behavior, where Flink tries to spread out the workload across all currently availableTaskManagers, users can setcluster.evenly-spread-out-slots: truein theflink-conf.yaml. -
[FLINK-11956]
s3-hadoopands3-prestofilesystems no longer use class relocations and should be loaded through plugins, but now seamlessly integrate with all credential providers. Other filesystems are strongly recommended to be used only as plugins, as we will continue to remove relocations. -
Flink 1.9 shipped with a refactored Web UI, with the legacy one being kept around as backup in case something wasn’t working as expected. No issues have been reported so far, so the community voted to drop the legacy Web UI in Flink 1.10.
Release Notes #
Please review the release notes carefully for a detailed list of changes and new features if you plan to upgrade your setup to Flink 1.10. This version is API-compatible with previous 1.x releases for APIs annotated with the @Public annotation.
List of Contributors #
The Apache Flink community would like to thank all contributors that have made this release possible:
Achyuth Samudrala, Aitozi, Alberto Romero, Alec.Ch, Aleksey Pak, Alexander Fedulov, Alice Yan, Aljoscha Krettek, Aloys, Andrey Zagrebin, Arvid Heise, Benchao Li, Benoit Hanotte, Benoît Paris, Bhagavan Das, Biao Liu, Chesnay Schepler, Congxian Qiu, Cyrille Chépélov, César Soto Valero, David Anderson, David Hrbacek, David Moravek, Dawid Wysakowicz, Dezhi Cai, Dian Fu, Dyana Rose, Eamon Taaffe, Fabian Hueske, Fawad Halim, Fokko Driesprong, Frey Gao, Gabor Gevay, Gao Yun, Gary Yao, GatsbyNewton, GitHub, Grebennikov Roman, GuoWei Ma, Gyula Fora, Haibo Sun, Hao Dang, Henvealf, Hongtao Zhang, HuangXingBo, Hwanju Kim, Igal Shilman, Jacob Sevart, Jark Wu, Jeff Martin, Jeff Yang, Jeff Zhang, Jiangjie (Becket) Qin, Jiayi, Jiayi Liao, Jincheng Sun, Jing Zhang, Jingsong Lee, JingsongLi, Joao Boto, John Lonergan, Kaibo Zhou, Konstantin Knauf, Kostas Kloudas, Kurt Young, Leonard Xu, Ling Wang, Lining Jing, Liupengcheng, LouisXu, Mads Chr. Olesen, Marco Zühlke, Marcos Klein, Matyas Orhidi, Maximilian Bode, Maximilian Michels, Nick Pavlakis, Nico Kruber, Nicolas Deslandes, Pablo Valtuille, Paul Lam, Paul Lin, PengFei Li, Piotr Nowojski, Piotr Przybylski, Piyush Narang, Ricco Chen, Richard Deurwaarder, Robert Metzger, Roman, Roman Grebennikov, Roman Khachatryan, Rong Rong, Rui Li, Ryan Tao, Scott Kidder, Seth Wiesman, Shannon Carey, Shaobin.Ou, Shuo Cheng, Stefan Richter, Stephan Ewen, Steve OU, Steven Wu, Terry Wang, Thesharing, Thomas Weise, Till Rohrmann, Timo Walther, Tony Wei, TsReaper, Tzu-Li (Gordon) Tai, Victor Wong, WangHengwei, Wei Zhong, WeiZhong94, Wind (Jiayi Liao), Xintong Song, XuQianJin-Stars, Xuefu Zhang, Xupingyong, Yadong Xie, Yang Wang, Yangze Guo, Yikun Jiang, Ying, YngwieWang, Yu Li, Yuan Mei, Yun Gao, Yun Tang, Zhanchun Zhang, Zhenghua Gao, Zhijiang, Zhu Zhu, a-suiniaev, azagrebin, beyond1920, biao.liub, blueszheng, bowen.li, caoyingjie, catkint, chendonglin, chenqi, chunpinghe, cyq89051127, danrtsey.wy, dengziming, dianfu, eskabetxe, fanrui, forideal, gentlewang, godfrey he, godfreyhe, haodang, hehuiyuan, hequn8128, hpeter, huangxingbo, huzheng, ifndef-SleePy, jiemotongxue, joe, jrthe42, kevin.cyj, klion26, lamber-ken, libenchao, liketic, lincoln-lil, lining, liuyongvs, liyafan82, lz, mans2singh, mojo, openinx, ouyangwulin, shining-huang, shuai-xu, shuo.cs, stayhsfLee, sunhaibotb, sunjincheng121, tianboxiu, tianchen, tianchen92, tison, tszkitlo40, unknown, vinoyang, vthinkxie, wangpeibin, wangxiaowei, wangxiyuan, wangxlong, wangyang0918, whlwanghailong, xuchao0903, xuyang1706, yanghua, yangjf2019, yongqiang chai, yuzhao.cyz, zentol, zhangzhanchum, zhengcanbin, zhijiang, zhongyong jin, zhuzhu.zz, zjuwangg, zoudaokoulife, 砚田, 谢磊, 张志豪, 曹建华