Apache Flink 1.11.0 Release Announcement
July 6, 2020 - Marta Paes (@morsapaes)The Apache Flink community is proud to announce the release of Flink 1.11.0! More than 200 contributors worked on over 1.3k issues to bring significant improvements to usability as well as new features to Flink users across the whole API stack. Some highlights that we’re particularly excited about are:
-
The core engine is introducing unaligned checkpoints, a major change to Flink’s fault tolerance mechanism that improves checkpointing performance under heavy backpressure.
-
A new Source API that simplifies the implementation of (custom) sources by unifying batch and streaming execution, as well as offloading internals such as event-time handling, watermark generation or idleness detection to Flink.
-
Flink SQL is introducing Support for Change Data Capture (CDC) to easily consume and interpret database changelogs from tools like Debezium. The renewed FileSystem Connector also expands the set of use cases and formats supported in the Table API/SQL, enabling scenarios like streaming data directly from Kafka to Hive.
-
Multiple performance optimizations to PyFlink, including support for vectorized User-defined Functions (Pandas UDFs). This improves interoperability with libraries like Pandas and NumPy, making Flink more powerful for data science and ML workloads.
Read on for all major new features and improvements, important changes to be aware of and what to expect moving forward!
The binary distribution and source artifacts are now available on the updated Downloads page of the Flink website, and the most recent distribution of PyFlink is available on PyPI. Please review the release notes carefully, and check the complete release changelog and updated documentation for more details.
We encourage you to download the release and share your feedback with the community through the Flink mailing lists or JIRA.
New Features and Improvements #
Unaligned Checkpoints (Beta) #
Triggering a checkpoint in Flink will cause a checkpoint barrier to flow from the sources of your topology all the way towards the sinks. For operators that receive more than one input stream, the barriers flowing through each channel need to be aligned before the operator can snapshot its state and forward the checkpoint barrier — typically, this alignment will take just a few milliseconds to complete, but it can become a bottleneck in backpressured pipelines as:
-
Checkpoint barriers will flow much slower through backpressured channels, effectively blocking the remaining channels and their upstream operators during checkpointing;
-
Slow checkpoint barrier propagation leads to longer checkpointing times and can, worst case, result in little to no progress in the application.
To improve the performance of checkpointing under backpressure scenarios, the community is rolling out the first iteration of unaligned checkpoints (FLIP-76) with Flink 1.11. Compared to the original checkpointing mechanism (Fig. 1), this approach doesn’t wait for barrier alignment across input channels, instead allowing barriers to overtake in-flight records (i.e., data stored in buffers) and forwarding them downstream before the synchronous part of the checkpoint takes place (Fig. 2).
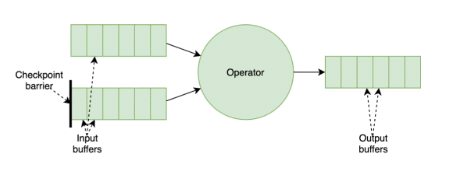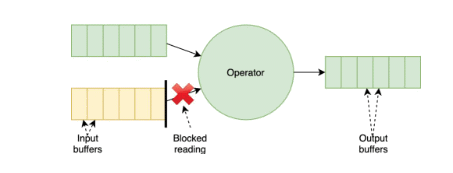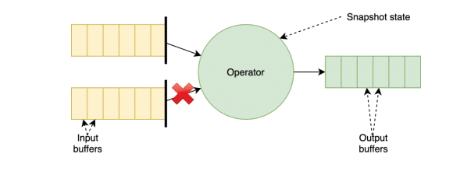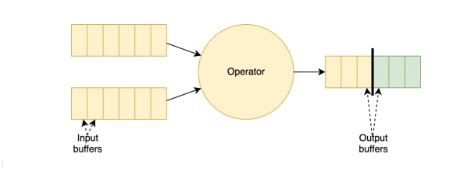
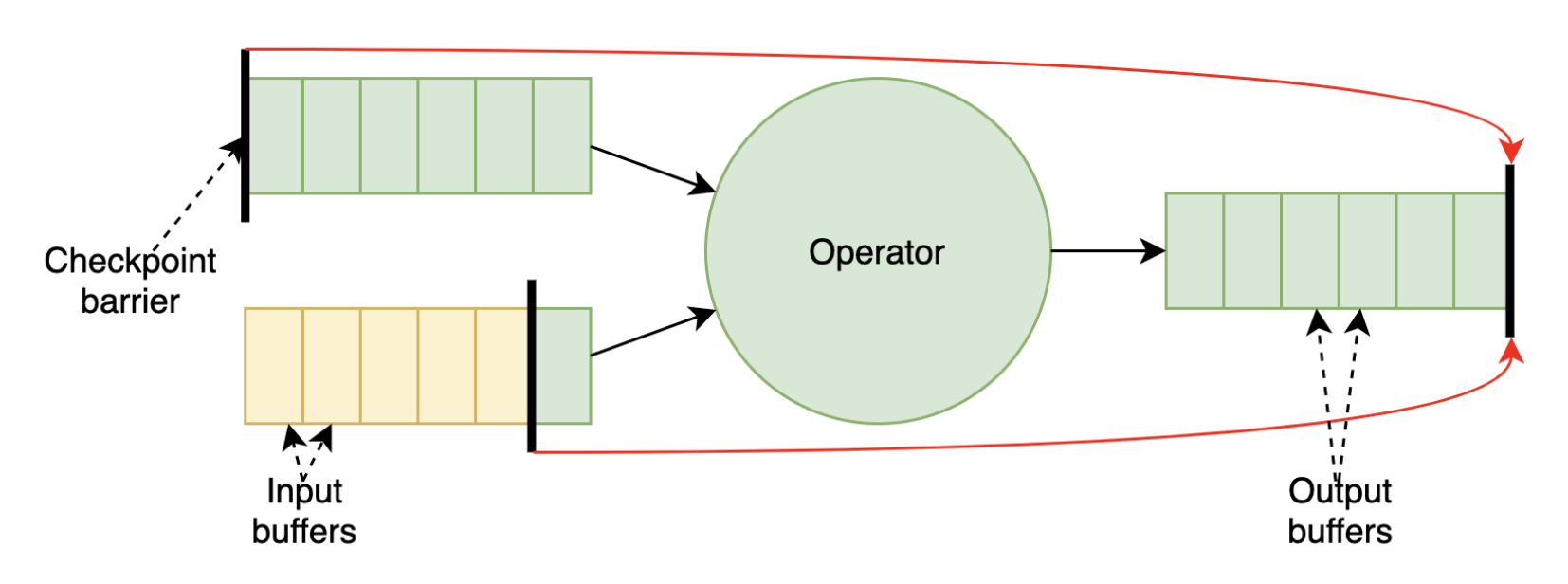
Because in-flight records have to be persisted as part of the snapshot, unaligned checkpoints will lead to increased checkpoints sizes. On the upside, checkpointing times are heavily reduced, so users will see more progress (even in unstable environments) as more up-to-date checkpoints will lighten the recovery process. You can learn more about the current limitations of unaligned checkpoints in the documentation, and track the improvement work planned for this feature in FLINK-14551.
As with any beta feature, we appreciate early feedback that you might want to share with the community after giving unaligned checkpoints a try!
Info To enable this feature, you need to configure the enableUnalignedCheckpoints option in your checkpoint config. Please note that unaligned checkpoints can only be enabled if checkpointingMode is set to CheckpointingMode.EXACTLY_ONCE.
Unified Watermark Generators #
So far, watermark generation (prev. also called assignment) relied on two different interfaces: AssignerWithPunctuatedWatermarks and AssignerWithPeriodicWatermarks; that were closely intertwined with timestamp extraction. This made it difficult to implement long-requested features like support for idleness detection, besides leading to code duplication and maintenance burden. With FLIP-126, the legacy watermark assigners are unified into a single interface: the WatermarkGenerator; and detached from the TimestampAssigner.
This gives users more control over watermark emission and simplifies the implementation of new connectors that need to support watermark assignment and timestamp extraction at the source (see New Data Source API). Multiple strategies for watermarking are available out-of-the-box as convenience methods in Flink 1.11 (e.g. forBoundedOutOfOrderness, forMonotonousTimestamps), though you can also choose to customize your own.
Support for Watermark Idleness Detection
The WatermarkStrategy.withIdleness() method allows you to mark a stream as idle if no events arrive within a configured time (i.e. a timeout duration), which in turn allows handling event time skew properly and preventing idle partitions from holding back the event time progress of the entire application. Users can already benefit from per-partition idleness detection in the Kafka connector, which has been adapted to use the new interfaces (FLINK-17669).
Note FLIP-126 introduces no breaking changes, but we recommend that users give preference to the new WatermarkGenerator interface moving forward, in preparation for the deprecation of the legacy watermark assigners in future releases.
New Data Source API (Beta) #
Up to this point, writing a production-grade source connector for Flink was a non-trivial task that required users to be somewhat familiar with Flink internals and account for implementation details like event time assignment, watermark generation or idleness detection in their code. Flink 1.11 introduces a new Data Source API (FLIP-27) to overcome these limitations, as well as the need to rewrite separate code for batch and streaming execution.
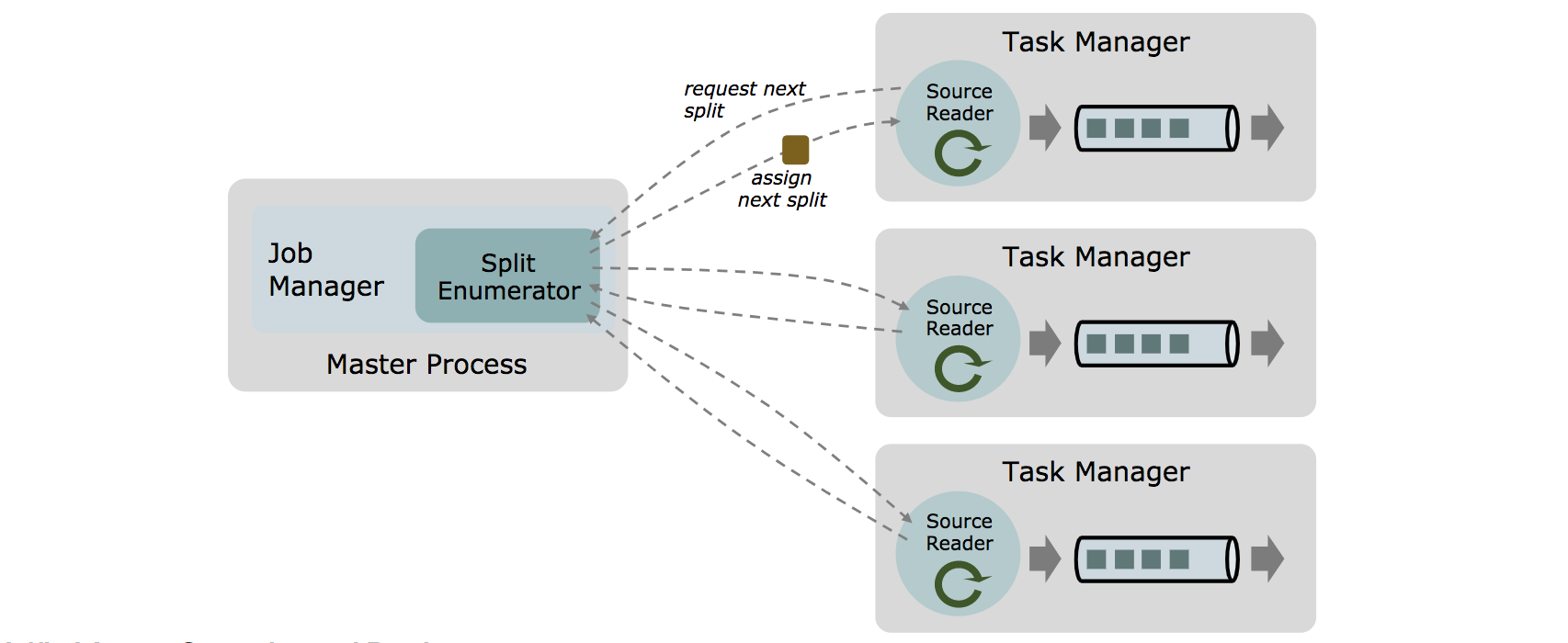
Separating the work of split discovery and the actual reading of the consumed data (i.e. the splits) in different components — resp. the SplitEnumerator and SourceReader — allows mixing and matching different enumeration strategies and split readers.
As an example, the existing Kafka connector has multiple strategies for partition discovery that are intermingled with the rest of the code. With the new interfaces in place, it would only need a single reader implementation and there could be several split enumerators for the different partition discovery strategies.
Batch and Streaming Unification
Source connectors implemented using the Data Source API will be able to work both as a bounded (batch) and unbounded (streaming) source. The difference between both cases is minimal: for bounded input, the SplitEnumerator will generate a fixed set of splits and each split is finite; for unbounded input, either the splits are not finite or the SplitEnumerator keeps generating new splits.
Implicit Watermark and Event Time Handling
The TimestampAssigner and WatermarkGenerator run transparently as part of the SourceReader component, so users also don’t have to implement any timestamp extraction or watermark generation code.
Note The existing source connectors have not yet been reimplemented using the Data Source API — this is planned for upcoming releases. If you’re looking to implement a new source, please refer to the Data Source documentation and the tips on source development.
Application Mode Deployments #
Prior to Flink 1.11, jobs in a Flink application could either be submitted to a long-running Flink Session Cluster (session mode) or a dedicated Flink Job Cluster (job mode). For both these modes, the main() method of user programs runs on the client side. This presents some challenges: on one hand, if the client is part of a large installation, it can easily become a bottleneck for JobGraph generation; and on the other, it’s not a good fit for containerized environments like Docker or Kubernetes.
From this release on, Flink gets an additional deployment mode: Application Mode (FLIP-85); where the main() method runs on the cluster, rather than the client. The job submission becomes a one-step process: you package your application logic and dependencies into an executable job JAR and the cluster entrypoint (ApplicationClusterEntryPoint) is responsible for calling the main() method to extract the JobGraph.
In Flink 1.11, the community worked to already support application mode in Kubernetes (FLINK-10934).
Other Improvements #
Unified Memory Configuration for JobManagers (FLIP-116)
Following the work started in Flink 1.10 to improve memory management and configuration, this release introduces a new memory model that aligns the JobManagers’ configuration options and terminology with that introduced in FLIP-49 for TaskManagers. This affects all deployment types: standalone, YARN, Mesos and the new active Kubernetes integration.
Attention Reusing a previous Flink configuration without any adjustments can result in differently computed memory parameters for the JVM and, as a result, performance changes or even failures. Make sure to check the migration guide if you’re planning to update to the latest version.
Improvements to the Flink WebUI (FLIP-75)
In Flink 1.11, the community kicked off a series of improvements to the Flink WebUI. The first to roll out are better TaskManager and JobManager log display (FLIP-103), as well as a new thread dump utility (FLINK-14816). Some additional work planned for upcoming releases includes better backpressure detection, more flexible and configurable exception display and support for displaying the history of subtask failure attempts.
Docker Image Unification (FLIP-111)
With this release, all Docker-related resources have been consolidated into apache/flink-docker and the entry point script has been extended to allow users to run the default Docker image in different modes without the need to create a custom image. The updated documentation describes in detail how to use and customize the official Flink Docker image for different environments and deployment modes.
Table API/SQL: Support for Change Data Capture (CDC) #
Change Data Capture (CDC) has become a popular pattern to capture committed changes from a database and propagate those changes to downstream consumers, for example to keep multiple datastores in sync and avoid common pitfalls such as dual writes. Being able to easily ingest and interpret these changelogs into the Table API/SQL has been a highly demanded feature in the Flink community — and it’s now possible with Flink 1.11.
To extend the scope of the Table API/SQL to use cases like CDC, Flink 1.11 introduces new table source and sink interfaces with changelog mode (see New TableSource and TableSink Interfaces) and support for the Debezium and Canal formats (FLIP-105). This means that dynamic tables sources are no longer limited to append-only operations and can ingest these external changelogs (INSERT events), interpret them into change operations (INSERT, UPDATE, DELETE events) and emit them downstream with the change type.
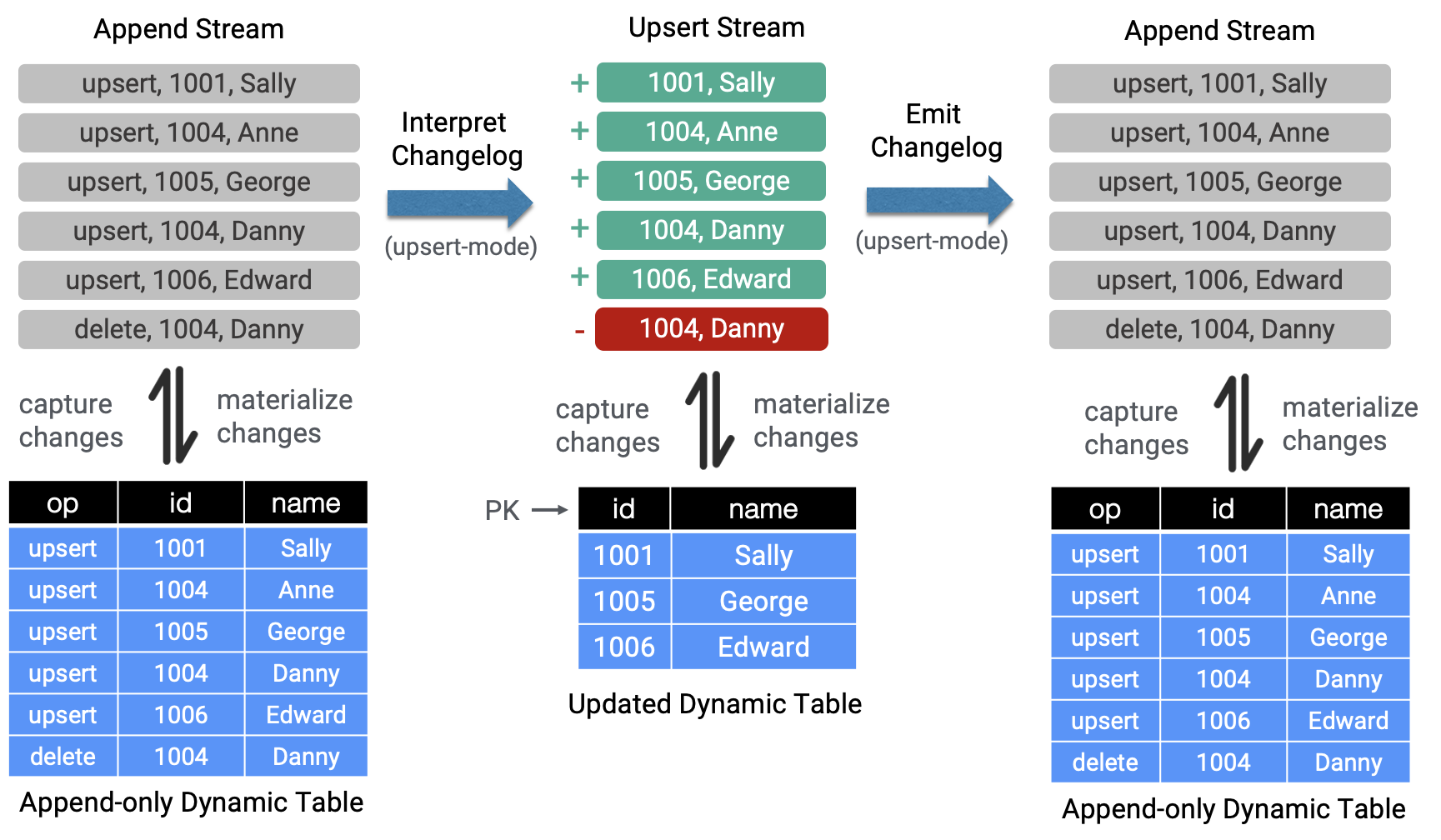
Users have to specify either “format=debezium-json” or “format=canal-json” in their CREATE TABLE statement to consume changelogs using SQL DDL.
CREATE TABLE my_table (
...
) WITH (
'connector'='...', -- e.g. 'kafka'
'format'='debezium-json',
'debezium-json.schema-include'='true' -- default: false (Debezium can be configured to include or exclude the message schema)
'debezium-json.ignore-parse-errors'='true' -- default: false
);
Flink 1.11 only supports Kafka as a changelog source out-of-the-box and JSON-encoded changelogs, with Avro (Debezium) and Protobuf (Canal) planned for future releases. There are also plans to support MySQL binlogs and Kafka compacted topics as sources, as well as to extend changelog support to batch execution.
Attention There is a known issue (FLINK-18461) that prevents changelog sources from being used to write to upsert sinks (e.g. MySQL, HBase, Elasticsearch). This will be fixed in the next patch release (1.11.1).
Table API/SQL: JDBC Catalog Interface and Postgres Catalog #
Flink 1.11 introduces a generic JDBC catalog interface (FLIP-93) that enables users of the Table API/SQL to derive table schemas automatically from connections to relational databases over JDBC. This eliminates the previous need for manual schema definition and type conversion, and also allows to check for schema errors at compile time instead of runtime.
The first implementation, rolling out with the new release, is the Postgres catalog.
Table API/SQL: FileSystem Connector with Support for Avro, ORC and Parquet #
To improve the user experience for end-to-end streaming ETL use cases, the Flink community worked on a new FileSystem Connector for the Table API/SQL (FLIP-115). The implementation is based on Flink’s FileSystem abstraction and reuses StreamingFileSink to ensure the same set of capabilities and consistent behaviour with the DataStream API.
This also means that Table API/SQL users can now make use of all formats already supported by StreamingFileSink, like (Avro) Parquet, as well as the new formats introduced with this release, like Avro (FLINK-11395) and Orc (FLINK-10114).
CREATE TABLE my_table (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem',
'path' = 'file:///path/to/file,
'format' = '...', -- supported formats: Avro, ORC, Parquet, CSV, JSON
...
);
The new all-rounder FileSystem Connector transparently handles batch and streaming execution, provides exactly-once guarantees and has full partition support, greatly expanding the scope of usage of the legacy connector. This allows users to easily implement common use cases like directly streaming data from Kafka to Hive.
You can track the upcoming improvements to the FileSystem Connector in FLINK-17778.
Table API/SQL: Support for Python UDFs #
Prior to this release, users of the Table API/SQL were limited to defining UDFs in either Java or Scala. In Flink 1.11, the community worked on expanding the usage scope of the Python language beyond PyFlink and providing support for Python UDFs in the SQL DDL syntax (FLIP-106), as well as the SQL Client (FLIP-114). Users can also register Python UDFs in the system catalog via SQL DDL or the Java Catalog API, so that functions can be shared between jobs.
Other Improvements to the Table API/SQL #
DDL and DML Compatibility for the Hive Connector (FLIP-123)
Starting from Flink 1.11, users can write SQL statements directly using Hive syntax (HiveQL) in the Table API/SQL and the SQL Client. For this purpose, an additional dialect was introduced and users can now dynamically switch between Flink (default) and Hive (hive) on a per-statement basis. For a complete list of supported DDL and DML statements, check the Hive dialect documentation.
Extensions and Improvements to the Flink SQL Syntax
-
Flink 1.11 introduces the concept of primary key constraints to leverage runtime optimizations in Flink SQL DDL (FLIP-87);
-
View objects are now fully supported in SQL DDL using the
CREATE/ALTER/DROP VIEWstatements (FLIP-71); -
Users can now specify or override table options in their DQL/DML statements using dynamic table options (FLIP-113).
-
To make connector properties less verbose and improve exception handling, some key properties have been refactored (FLIP-122). This change does not break compatibility, so users can still use the old property keys.
New TableSource and TableSink Interfaces (FLIP-95)
Flink 1.11 introduces new table source and sink interfaces (resp. DynamicTableSource and DynamicTableSink) that unify batch and streaming execution, provide more efficient data processing with the Blink planner and offer support for handling changelogs (see Support for Change Data Capture (CDC)). The new interfaces also make it easier for users to implement custom connectors or modify existing ones. For an end-to-end example on how to implement a custom scan table source with a decoding format that supports changelog semantics, check out the documentation.
Note Although compatibility is not immediately affected, we recommend that Table API/SQL users update any sources and sinks to the new interface stack.
Refactored TableEnvironment Interface (FLIP-84)
The semantics to describe similar behaviours in the TableEnvironment and Table interfaces have diverged over time, leading to an inconsistent and sometimes unclear user experience. To improve this and make programming more fluent in the Table API/SQL, Flink 1.11 introduces new methods that unify behaviours like execution triggering (e.g. executeSql()) and result representation (e.g. print(), collect()), and also lay the groundwork for important features like multi-statement execution support in future releases.
Note The methods deprecated with FLIP-84 will not be immediately removed, but we recommend that users adopt the newly introduced methods. For a complete list of new and deprecated methods, check the “Summary” section of FLIP-84.
New Type Inference for Table API UDFs (FLIP-65)
In Flink 1.9, the community started working on a new data type system for the Table API to improve its compliance with the SQL standard (FLIP-37). This work is now close to being completed in Flink 1.11, with the exposure of Table API UDFs to the new type system (scalar and table functions, with aggregate functions planned for the next release).
PyFlink: Support for Pandas UDFs #
Up to this release, Python UDFs in PyFlink only supported scalar values of standard Python types. This presented some limitations:
-
High serialization/deserialization overhead in the process of transferring data between the JVM and the Python processes;
-
Hard to integrate with common Python libraries for high-performance numerical processing like pandas and NumPy.
To overcome these limitations, the community introduced support for (scalar) vectorized Python UDFs based on pandas in Flink 1.11 (FLIP-97). The performance of vectorized UDFs is usually much higher, as the serialization/deserialization overhead is minimized by falling back to Apache Arrow; and handling pandas.Series as input/output allows to take full advantage of the pandas and NumPy libraries. This makes Pandas UDFs a popular solution to parallelize Machine Learning and other large-scale, distributed data science workloads (e.g. feature engineering, distributed model application).
@udf(input_types=[DataTypes.BIGINT(), DataTypes.BIGINT()], result_type=DataTypes.BIGINT(), udf_type="pandas")
def add(i, j):
return i + j
To mark a UDF as a Pandas UDF, you only need to add an extra parameter udf_type=”pandas” in the udf decorator, as described in the documentation.
Other Improvements to PyFlink #
Conversion fromPandas/toPandas (FLIP-120)
Arrow is also supported as an optimization to convert between PyFlink tables and pandas.DataFrames, enabling users to switch processing engines seamlessly without the need for an intermediate connector. For examples on how to use the new fromPandas() and toPandas() methods in PyFlink, check out the documentation.
Support for User-defined Table Functions (UDTFs) (FLINK-14500)
From Flink 1.11, you can define and register custom UDTFs in PyFlink. Similar to a Python UDF, a UDTF takes zero, one or multiple scalar values as input, but can return an arbitrary number of rows as output instead of a single value.
Cython Performance Optimization for UDFs (FLIP-121)
Cython is a compiled superset of the Python language that is often used to improve the performance of large-scale numeric processing in Python, as it optimizes execution to machine code-level speed and pairs well with popular C-based libraries like NumPy. From Flink 1.11, you can build PyFlink with Cython support and “Cythonize” your Python UDFs to substantially improve code execution speed (up to 30x faster, compared to Python UDFs in Flink 1.10).
User-defined Metrics in Python UDFs (FLIP-112)
To make it easier for users to monitor and debug the execution of Python UDFs, PyFlink now allows gathering and exposing metrics to external systems, as well as defining user scopes and variables. You can access the metrics system from a UDF by calling function_context.get_metric_group() in the open method, as described in the documentation.
Important Changes #
-
[FLINK-17339] The Blink planner is the default in the Table API/SQL starting from Flink 1.11. This was already the case for the SQL Client since Flink 1.10. The old Flink planner is still supported, but not actively developed.
-
[FLINK-5763] Savepoints now contain all their state inside a single directory (both metadata and program state). This makes it straightforward to figure out which files make up the state of a savepoint and allows users to relocate savepoints by simply moving a directory.
-
[FLINK-16408] To reduce pressure on the JVM metaspace, the user code class loader is being reused by a
TaskExecutoras long as there is at least a single slot allocated for the respective job. This changes Flink’s recovery behaviour slightly, so that it will not reload static fields. -
[FLINK-11086] Flink now supports Hadoop versions above Hadoop 3.0.0. Note that the Flink project does not provide any updated “flink-shaded-hadoop-*” jars. Users need to provide Hadoop dependencies through the
HADOOP_CLASSPATHenvironment variable (recommended) or the lib/ folder. -
[FLINK-16963] All
MetricReportersthat come with Flink have been converted to plugins. These should no longer be placed into/lib(which may result in dependency conflicts), but/plugins/<some_directory>instead. -
[FLINK-12639] The Flink documentation is undergoing some rework, so you might notice that the navigation and organization of content look slightly different starting from Flink 1.11.
Release Notes #
Please review the release notes carefully for a detailed list of changes and new features if you plan to upgrade your setup to Flink 1.11. This version is API-compatible with previous 1.x releases for APIs annotated with the @Public annotation.
List of Contributors #
The Apache Flink community would like to thank all the 200+ contributors that have made this release possible:
Aitozi, Alexander Fedulov, Alexey Trenikhin, Aljoscha Krettek, Andrey Zagrebin, Arvid Heise, Ayush Saxena, Bairos, Bartosz Krasinski, Benchao Li, Benoit Hanotte, Benoît Paris, Bhagavan Das, Canbin Zheng, Cedric Chen, Chesnay Schepler, Colm O hEigeartaigh, Congxian Qiu, CrazyTomatoOo, Danish Amjad, Danny Chan, David Anderson, Dawid Wysakowicz, Dian Fu, Dominik Wosiński, Echo Lee, Ethan Marsh, Etienne Chauchot, Fabian Hueske, Fabian Paul, Flavio Pompermaier, Gao Yun, Gary Yao, Ghildiyal, Grebennikov Roman, GuoWei Ma, Guru Prasad, Gyula Fora, Hequn Cheng, Hu Guang, HuFeiHu, HuangXingBo, Igal Shilman, Ismael Juma, Jacob Sevart, Jark Wu, Jaskaran Bindra, Jason K, Jeff Yang, Jeff Zhang, Jerry Wang, Jiangjie (Becket) Qin, Jiayi, Jiayi Liao, Jiayi-Liao, Jincheng Sun, Jing Zhang, Jingsong Lee, JingsongLi, Jun Qin, JunZhang, Jörn Kottmann, Kevin Bohinski, Konstantin Knauf, Kostas Kloudas, Kurt Young, Leonard Xu, Lining Jing, Liupengcheng, LululuAlu, Marta Paes Moreira, Matt Welke, Max Kuklinski, Maximilian Michels, Nico Kruber, Niels Basjes, Oleksandr Nitavskyi, Paul Lam, Paul Lin, PengFei Li, PengchengLiu, Piotr Nowojski, Prem Santosh, Qingsheng Ren, Rafi Aroch, Raymond Farrelly, Richard Deurwaarder, Robert Metzger, RocMarshal, Roey Shem Tov, Roman, Roman Khachatryan, Rong Rong, RoyRuan, Rui Li, Seth Wiesman, Shaobin.Ou, Shengkai, Shuiqiang Chen, Shuo Cheng, Sivaprasanna, Sivaprasanna S, SteNicholas, Stefan Richter, Stephan Ewen, Steve OU, Steve Whelan, Tartarus, Terry Wang, Thomas Weise, Till Rohrmann, Timo Walther, TsReaper, Tzu-Li (Gordon) Tai, Victor Wong, Wei Zhong, Weike DONG, Xiaogang Zhou, Xintong Song, Xu Bai, Xuannan, Yadong Xie, Yang Wang, Yangze Guo, Yichao Yang, Ying, Yu Li, Yuan Mei, Yun Gao, Yun Tang, Yuval Itzchakov, Zakelly, Zhao, Zhenghua Gao, Zhijiang, Zhu Zhu, acqua.csq, austin ce, azagrebin, bdine, bowen.li, caoyingjie, caozhen, caozhen1937, chaojianok, chen, chendonglin, comsir, cpugputpu, czhang2, dianfu, edu05, eduardowt, fangliang, felixzheng, fmyblack, gauss, gk0916, godfrey he, godfreyhe, guliziduo, guowei.mgw, hehuiyuan, hequn8128, hpeter, huangxingbo, huzheng, ifndef-SleePy, jingwen-ywb, jrthe42, kevin.cyj, klion26, lamber-ken, leesf, libenchao, lijiewang.wlj, liuyongvs, lsy, lumen, machinedoll, mans2singh, molsionmo, oliveryunchang, openinx, paul8263, ptmagic, qqibrow, sev7e0, shuai-xu, shuai.xu, shuiqiangchen, snuyanzin, spafka, sunhaibotb, sunjincheng121, testfixer, tison, vinoyang, vthinkxie, wangtong, wangxianghu, wangxiyuan, wangxlong, wangyang0918, wenlong.lwl, whlwanghailong, william, windWheel, wooplevip, wuxuyang, xushiwei, xuyang1706, yanghua, yangyichao-mango, yuzhao.cyz, zentol, zhanglibing, zhangmang, zhangzhanchun, zhengcanbin, zhengshuli, zhenxianyimeng, zhijiang, zhongyong jin, zhule, zhuxiaoshang, zjuwangg, zoudan, zoudaokoulife, zzchun, “lzh576177775”, 骚sir, 厉颖, 张军, 曹建华, 漫步云端