Apache Flink 1.13.0 Release Announcement
May 3, 2021 - Stephan Ewen (@StephanEwen) Dawid Wysakowicz (@dwysakowicz)The Apache Flink community is excited to announce the release of Flink 1.13.0! More than 200 contributors worked on over 1,000 issues for this new version.
The release brings us a big step forward in one of our major efforts: Making Stream Processing Applications as natural and as simple to manage as any other application. The new reactive scaling mode means that scaling streaming applications in and out now works like in any other application by just changing the number of parallel processes.
The release also prominently features a series of improvements that help users better understand the performance of applications. When the streams don’t flow as fast as you’d hope, these can help you to understand why: Load and backpressure visualization to identify bottlenecks, CPU flame graphs to identify hot code paths in your application, and State Access Latencies to see how the State Backends are keeping up.
Beyond those features, the Flink community has added a ton of improvements all over the system, some of which we discuss in this article. We hope you enjoy the new release and features. Towards the end of the article, we describe changes to be aware of when upgrading from earlier versions of Apache Flink.
We encourage you to download the release and share your feedback with the community through the Flink mailing lists or JIRA.
Notable features #
Reactive scaling #
Reactive scaling is the latest piece in Flink’s initiative to make Stream Processing Applications as natural and as simple to manage as any other application.
Flink has a dual nature when it comes to resource management and deployments: You can deploy Flink applications onto resource orchestrators like Kubernetes or Yarn in such a way that Flink actively manages the resources and allocates and releases workers as needed. That is especially useful for jobs and applications that rapidly change their required resources, like batch applications and ad-hoc SQL queries. The application parallelism rules, the number of workers follows. In the context of Flink applications, we call this active scaling.
For long-running streaming applications, it is often a nicer model to just deploy them like any other long-running application: The application doesn’t really need to know that it runs on K8s, EKS, Yarn, etc. and doesn’t try to acquire a specific amount of workers; instead, it just uses the number of workers that are given to it. The number of workers rules, the application parallelism adjusts to that. In the context of Flink, we call that reactive scaling.
The Application Deployment Mode started this effort, making deployments more application-like (by avoiding two separate deployment steps to (1) start a cluster and (2) submit an application). The reactive scaling mode completes this, and you now don’t have to use extra tools (scripts, or a K8s operator) anymore to keep the number of workers, and the application parallelism settings in sync.
You can now put an auto-scaler around Flink applications like around other typical applications — as long as you are mindful about the cost of rescaling when configuring the autoscaler: Stateful streaming applications must move state around when scaling.
To try the reactive-scaling mode, add the scheduler-mode: reactive config entry and deploy
an application cluster (standalone or Kubernetes). Check out the reactive scaling docs for more details.
Analyzing application performance #
Like for any application, analyzing and understanding the performance of a Flink application is critical. Often even more critical, because Flink applications are typically data-intensive (processing high volumes of data) and are at the same time expected to provide results within (near-) real-time latencies.
When an application doesn’t keep up with the data rate anymore, or an application takes more resources than you’d expect it would, these new tools can help you track down the causes:
Bottleneck detection, Back Pressure monitoring
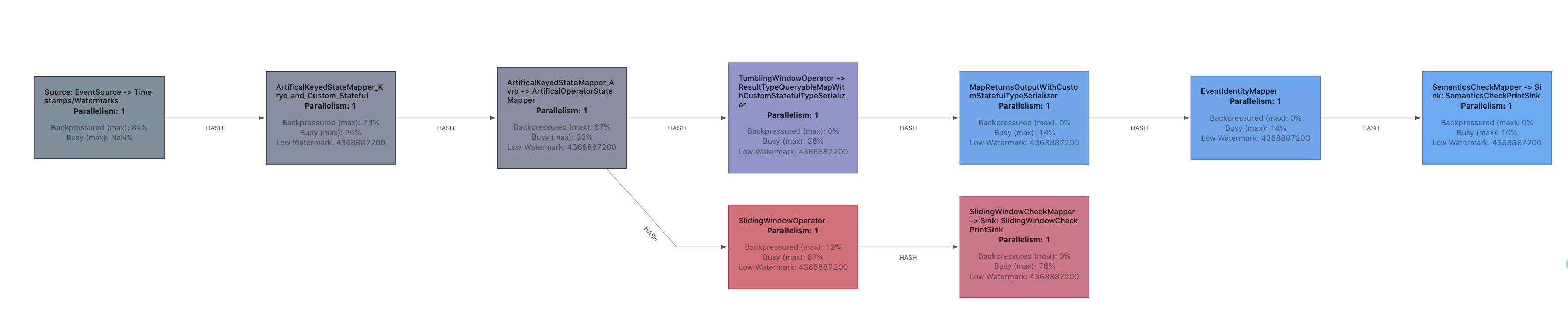
The first question during performance analysis is often: Which operation is the bottleneck?
To help answer that, Flink exposes metrics about the degree to which tasks are busy (doing work) and back-pressured (have the capacity to do work but cannot because their successor operators cannot accept more results). Candidates for bottlenecks are the busy operators whose predecessors are back-pressured.
Flink 1.13 brings an improved back pressure metric system (using task mailbox timings rather than thread stack sampling), and a reworked graphical representation of the job’s dataflow with color-coding and ratios for busyness and backpressure.
CPU flame graphs in Web UI
The next question during performance analysis is typically: What part of work in the bottlenecked operator is expensive?
One visually effective means to investigate that is Flame Graphs. They help answer question like:
-
Which methods are currently consuming CPU resources?
-
How does one method’s CPU consumption compare to other methods?
-
Which series of calls on the stack led to executing a particular method?
Flame Graphs are constructed by repeatedly sampling the thread stack traces. Every method call is represented by a bar, where the length of the bar is proportional to the number of times it is present in the samples. When enabled, the graphs are shown in a new UI component for the selected operator.
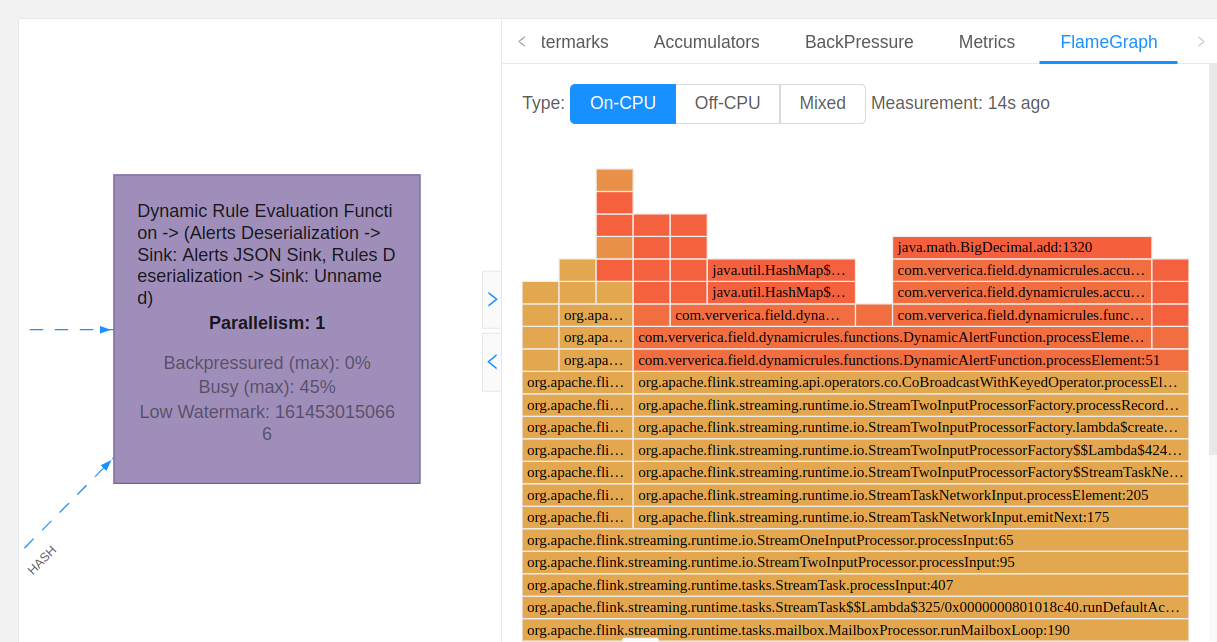
The Flame Graphs documentation contains more details and instructions for enabling this feature.
Access Latency Metrics for State
Another possible performance bottleneck can be the state backend, especially when your state is larger than the main memory available to Flink and you are using the RocksDB state backend.
That’s not saying RocksDB is slow (we love RocksDB!), but it has some requirements to achieve good performance. For example, it is easy to accidentally starve RocksDB’s demand for IOPs on cloud setups with the wrong type of disk resources.
On top of the CPU flame graphs, the new state backend latency metrics can help you understand whether
your state backend is responsive. For example, if you see that RocksDB state accesses start to take
milliseconds, you probably need to look into your memory and I/O configuration.
These metrics can be activated by setting the state.backend.rocksdb.latency-track-enabled option.
The metrics are sampled, and their collection should have a marginal impact on the RocksDB state
backend performance.
Switching State Backend with savepoints #
You can now change the state backend of a Flink application when resuming from a savepoint. That means the application’s state is no longer locked into the state backend that was used when the application was initially started.
This makes it possible, for example, to initially start with the HashMap State Backend (pure in-memory in JVM Heap) and later switch to the RocksDB State Backend, once the state grows too large.
Under the hood, Flink now has a canonical savepoint format, which all state backends use when creating a data snapshot for a savepoint.
User-specified pod templates for Kubernetes deployments #
The native Kubernetes deployment (where Flink actively talks to K8s to start and stop pods) now supports custom pod templates.
With those templates, users can set up and configure the JobManagers and TaskManagers pods in a Kubernetes-y way, with flexibility beyond the configuration options that are directly built into Flink’s Kubernetes integration.
Unaligned Checkpoints - production-ready #
Unaligned Checkpoints have matured to the point where we encourage all users to try them out, if they see issues with their application under backpressure.
In particular, these changes make Unaligned Checkpoints easier to use:
-
You can now rescale applications from unaligned checkpoints. This comes in handy if your application needs to be scaled from a retained checkpoint because you cannot (afford to) create a savepoint.
-
Enabling unaligned checkpoints is cheaper for applications that are not back-pressured. Unaligned checkpoints can now trigger adaptively with a timeout, meaning a checkpoint starts as an aligned checkpoint (not storing any in-flight events) and falls back to an unaligned checkpoint (storing some in-flight events), if the alignment phase takes longer than a certain time.
Find out more about how to enable unaligned checkpoints in the Checkpointing Documentation.
Machine Learning Library moving to a separate repository #
To accelerate the development of Flink’s Machine Learning efforts (streaming, batch, and unified machine learning), the effort has moved to the new repository flink-ml under the Flink project. We here follow a similar approach like the Stateful Functions effort, where a separate repository has helped to speed up the development by allowing for more light-weight contribution workflows and separate release cycles.
Stay tuned for more updates in the Machine Learning efforts, like the interplay with ALink (suite of many common Machine Learning Algorithms on Flink) or the Flink & TensorFlow integration.
Notable SQL & Table API improvements #
Like in previous releases, SQL and the Table API remain an area of big developments.
Windows via Table-valued functions #
Defining time windows is one of the most frequent operations in streaming SQL queries. Flink 1.13 introduces a new way to define windows: via Table-valued Functions. This approach is both more expressive (lets you define new types of windows) and fully in line with the SQL standard.
Flink 1.13 supports TUMBLE and HOP windows in the new syntax, SESSION windows will follow in a subsequent release. To demonstrate the increased expressiveness, consider the two examples below.
A new CUMULATE window function that assigns windows with an expanding step size until the maximum window size is reached:
SELECT window_time, window_start, window_end, SUM(price) AS total_price
FROM TABLE(CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end, window_time;
You can reference the window start and window end time of the table-valued window functions, making new types of constructs possible. Beyond regular windowed aggregations and windowed joins, you can, for example, now express windowed Top-K aggregations:
SELECT window_time, ...
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY total_price DESC)
as rank
FROM t
) WHERE rank <= 100;
Improved interoperability between DataStream API and Table API/SQL #
This release radically simplifies mixing DataStream API and Table API programs.
The Table API is a great way to develop applications, with its declarative nature and its many built-in functions. But sometimes, you need to escape to the DataStream API for its expressiveness, flexibility, and explicit control over the state.
The new methods StreamTableEnvironment.toDataStream()/.fromDataStream() can model
a DataStream from the DataStream API as a table source or sink.
Notable improvements include:
-
Automatic type conversion between the DataStream and Table API type systems.
-
Seamless integration of event time configurations; watermarks flow through boundaries for high consistency.
-
Enhancements to the
Rowclass (representing row events from the Table API) has received a major overhaul (improving the behavior oftoString()/hashCode()/equals()methods) and now supports accessing fields by name, with support for sparse representations.
Table table = tableEnv.fromDataStream(
dataStream,
Schema.newBuilder()
.columnByMetadata("rowtime", "TIMESTAMP(3)")
.watermark("rowtime", "SOURCE_WATERMARK()")
.build());
DataStream<Row> dataStream = tableEnv.toDataStream(table)
.keyBy(r -> r.getField("user"))
.window(...);
SQL Client: Init scripts and Statement Sets #
The SQL Client is a convenient way to run and deploy SQL streaming and batch jobs directly, without writing any code from the command line, or as part of a CI/CD workflow.
This release vastly improves the functionality of the SQL client. Almost all operations as that
are available to Java applications (when programmatically launching queries from the
TableEnvironment) are now supported in the SQL Client and as SQL scripts.
That means SQL users need much less glue code for their SQL deployments.
Easier Configuration and Code Sharing
The support of YAML files to configure the SQL Client will be discontinued. Instead, the client accepts one or more initialization scripts to configure a session before the main SQL script gets executed.
These init scripts would typically be shared across teams/deployments and could be used for loading common catalogs, applying common configuration settings, or defining standard views.
./sql-client.sh -i init1.sql init2.sql -f sqljob.sql
More config options
A greater set of recognized config options and improved SET/RESET commands make it easier to
define and control the execution from within the SQL client and SQL scripts.
Multi-query Support with Statement Sets
Multi-query execution lets you execute multiple SQL queries (or statements) as a single Flink job. This is particularly useful for streaming SQL queries that run indefinitely.
Statement Sets are the mechanism to group the queries together that should be executed together.
The following is an example of a SQL script that can be run via the SQL client. It sets up and configures the environment and executes multiple queries. The script captures end-to-end the queries and all environment setup and configuration work, making it a self-contained deployment artifact.
-- set up a catalog
CREATE CATALOG hive_catalog WITH ('type' = 'hive');
USE CATALOG hive_catalog;
-- or use temporary objects
CREATE TEMPORARY TABLE clicks (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP
) WITH (
'connector' = 'kafka',
'topic' = 'clicks',
'properties.bootstrap.servers' = '...',
'format' = 'avro'
);
-- set the execution mode for jobs
SET execution.runtime-mode=streaming;
-- set the sync/async mode for INSERT INTOs
SET table.dml-sync=false;
-- set the job's parallelism
SET parallism.default=10;
-- set the job name
SET pipeline.name = my_flink_job;
-- restore state from the specific savepoint path
SET execution.savepoint.path=/tmp/flink-savepoints/savepoint-bb0dab;
BEGIN STATEMENT SET;
INSERT INTO pageview_pv_sink
SELECT page_id, count(1) FROM clicks GROUP BY page_id;
INSERT INTO pageview_uv_sink
SELECT page_id, count(distinct user_id) FROM clicks GROUP BY page_id;
END;
Hive query syntax compatibility #
You can now write SQL queries against Flink using the Hive SQL syntax. In addition to Hive’s DDL dialect, Flink now also accepts the commonly-used Hive DML and DQL dialects.
To use the Hive SQL dialect, set table.sql-dialect to hive and load the HiveModule.
The latter is important because Hive’s built-in functions are required for proper syntax and
semantics compatibility. The following example illustrates that:
CREATE CATALOG myhive WITH ('type' = 'hive'); -- setup HiveCatalog
USE CATALOG myhive;
LOAD MODULE hive; -- setup HiveModule
USE MODULES hive,core;
SET table.sql-dialect = hive; -- enable Hive dialect
SELECT key, value FROM src CLUSTER BY key; -- run some Hive queries
Please note that the Hive dialect no longer supports Flink’s SQL syntax for DML and DQL statements.
Switch back to the default dialect for Flink’s syntax.
Improved behavior of SQL time functions #
Working with time is a crucial element of any data processing. But simultaneously, handling different time zones, dates, and times is an increadibly delicate task when working with data.
In Flink 1.13. we put much effort into simplifying the usage of time-related functions. We adjusted (made
more specific) the return types of functions such as: PROCTIME(), CURRENT_TIMESTAMP, NOW().
Moreover, you can now also define an event time attribute on a TIMESTAMP_LTZ column to gracefully do window processing with the support of Daylight Saving Time.
Please see the release notes for a complete list of changes.
Notable PyFlink improvements #
The general theme of this release in PyFlink is to bring the Python DataStream API and Table API closer to feature parity with the Java/Scala APIs.
Stateful operations in the Python DataStream API #
With Flink 1.13, Python programmers now also get to enjoy the full potential of Apache Flink’s stateful stream processing APIs. The rearchitected Python DataStream API, introduced in Flink 1.12, now has full stateful capabilities, allowing users to remember information from events in the state and act on it later.
That stateful processing capability is the basis of many of the more sophisticated processing operations, which need to remember information across individual events (for example, Windowing Operations).
This example shows a custom counting window implementation, using state:
class CountWindowAverage(FlatMapFunction):
def __init__(self, window_size):
self.window_size = window_size
def open(self, runtime_context: RuntimeContext):
descriptor = ValueStateDescriptor("average", Types.TUPLE([Types.LONG(), Types.LONG()]))
self.sum = runtime_context.get_state(descriptor)
def flat_map(self, value):
current_sum = self.sum.value()
if current_sum is None:
current_sum = (0, 0)
# update the count
current_sum = (current_sum[0] + 1, current_sum[1] + value[1])
# if the count reaches window_size, emit the average and clear the state
if current_sum[0] >= self.window_size:
self.sum.clear()
yield value[0], current_sum[1] // current_sum[0]
else:
self.sum.update(current_sum)
ds = ... # type: DataStream
ds.key_by(lambda row: row[0]) \
.flat_map(CountWindowAverage(5))
User-defined Windows in the PyFlink DataStream API #
Flink 1.13 adds support for user-defined windows to the PyFlink DataStream API. Programs can now use windows beyond the standard window definitions.
Because windows are at the heart of all programs that process unbounded streams (by splitting the stream into “buckets” of bounded size), this greatly increases the expressiveness of the API.
Row-based operation in the PyFlink Table API #
The Python Table API now supports row-based operations, i.e., custom transformation functions on rows. These functions are an easy way to apply data transformations on tables beyond the built-in functions.
This is an example of using a map() operation in Python Table API:
@udf(result_type=DataTypes.ROW(
[DataTypes.FIELD("c1", DataTypes.BIGINT()),
DataTypes.FIELD("c2", DataTypes.STRING())]))
def increment_column(r: Row) -> Row:
return Row(r[0] + 1, r[1])
table = ... # type: Table
mapped_result = table.map(increment_column)
In addition to map(), the API also supports flat_map(), aggregate(), flat_aggregate(),
and other row-based operations. This brings the Python Table API a big step closer to feature
parity with the Java Table API.
Batch execution mode for PyFlink DataStream programs #
The PyFlink DataStream API now also supports the batch execution mode for bounded streams, which was introduced for the Java DataStream API in Flink 1.12.
The batch execution mode simplifies operations and improves the performance of programs on bounded streams, by exploiting the bounded stream nature to bypass state backends and checkpoints.
Other improvements #
Flink Documentation via Hugo
The Flink Documentation has been migrated from Jekyll to Hugo. If you find something missing, please let us know. We are also curious to hear if you like the new look & feel.
Exception histories in the Web UI
The Flink Web UI will present up to n last exceptions that caused a job to fail. That helps to debug scenarios where a root failure caused subsequent failures. The root failure cause can be found in the exception history.
Better exception / failure-cause reporting for unsuccessful checkpoints
Flink now provides statistics for checkpoints that failed or were aborted to make it easier to determine the failure cause without having to analyze the logs.
Prior versions of Flink were reporting metrics (e.g., size of persisted data, trigger time) only in case a checkpoint succeeded.
Exactly-once JDBC sink
From 1.13, JDBC sink can guarantee exactly-once delivery of results for XA-compliant databases by transactionally committing results on checkpoints. The target database must have (or be linked to) an XA Transaction Manager.
The connector exists currently only for the DataStream API, and can be created through the
JdbcSink.exactlyOnceSink(...) method (or by instantiating the JdbcXaSinkFunction directly).
PyFlink Table API supports User-Defined Aggregate Functions in Group Windows
Group Windows in PyFlink’s Table API now support both general Python User-defined Aggregate Functions (UDAFs) and Pandas UDAFs. Such functions are critical to many analysis- and ML training programs.
Flink 1.13 improves upon previous releases, where these functions were only supported in unbounded Group-by aggregations.
Improved Sort-Merge Shuffle for Batch Execution
Flink 1.13 improves the memory stability and performance of the sort-merge blocking shuffle for batch-executed programs, initially introduced in Flink 1.12 via FLIP-148.
Programs with higher parallelism (1000s) should no longer frequently trigger OutOfMemoryError: Direct Memory. The performance (especially on spinning disks) is improved through better I/O scheduling and broadcast optimizations.
HBase connector supports async lookup and lookup cache
The HBase Lookup Table Source now supports an async lookup mode and a lookup cache. This greatly benefits the performance of Table/SQL jobs with lookup joins against HBase, while reducing the I/O requests to HBase in the typical case.
In prior versions, the HBase Lookup Source only communicated synchronously, resulting in lower pipeline utilization and throughput.
Changes to consider when upgrading to Flink 1.13 #
- FLINK-21709 - The old planner of the Table &
SQL API has been deprecated in Flink 1.13 and will be dropped in Flink 1.14.
The Blink engine has been the default planner for some releases now and will be the only one going forward.
That means that both the
BatchTableEnvironmentand SQL/DataSet interoperability are reaching the end of life. Please use the unifiedTableEnvironmentfor batch and stream processing going forward. - FLINK-22352 The community decided to deprecate the Apache Mesos support for Apache Flink. It is subject to removal in the future. Users are encouraged to switch to a different resource manager.
- FLINK-21935 - The
state.backend.asyncoption is deprecated. Snapshots are always asynchronous now (as they were by default before) and there is no option to configure a synchronous snapshot anymore. - FLINK-17012 - The tasks’
RUNNINGstate was split into two states:INITIALIZINGandRUNNING. A task isINITIALIZINGwhile it loads the checkpointed state, and, in the case of unaligned checkpoints, until the checkpointed in-flight data has been recovered. This lets monitoring systems better determine when the tasks are really back to doing work by making the phase for state restoring explicit. - FLINK-21698 - The CAST operation between the
NUMERIC type and the TIMESTAMP type is problematic and therefore no longer supported: Statements like
CAST(numeric AS TIMESTAMP(3))will now fail. Please useTO_TIMESTAMP(FROM_UNIXTIME(numeric))instead. - FLINK-22133 The unified source API for connectors
has a minor breaking change: The
SplitEnumerator.snapshotState()method was adjusted to accept the Checkpoint ID of the checkpoint for which the snapshot is created. - FLINK-19463 - The old
StateBackendinterfaces were deprecated as they had overloaded semantics which many users found confusing. This is a pure API change and does not affect runtime characteristics of applications. For full details on how to update existing pipelines, please see the migration guide.
Resources #
The binary distribution and source artifacts are now available on the updated Downloads page of the Flink website, and the most recent distribution of PyFlink is available on PyPI.
Please review the release notes
carefully if you plan to upgrade your setup to Flink 1.13. This version is API-compatible with
previous 1.x releases for APIs annotated with the @Public annotation.
You can also check the complete release changelog and updated documentation for a detailed list of changes and new features.
List of Contributors #
The Apache Flink community would like to thank each one of the contributors that have made this release possible:
acqua.csq, AkisAya, Alexander Fedulov, Aljoscha Krettek, Ammar Al-Batool, Andrey Zagrebin, anlen321, Anton Kalashnikov, appleyuchi, Arvid Heise, Austin Cawley-Edwards, austin ce, azagrebin, blublinsky, Brian Zhou, bytesmithing, caozhen1937, chen qin, Chesnay Schepler, Congxian Qiu, Cristian, cxiiiiiii, Danny Chan, Danny Cranmer, David Anderson, Dawid Wysakowicz, dbgp2021, Dian Fu, DinoZhang, dixingxing, Dong Lin, Dylan Forciea, est08zw, Etienne Chauchot, fanrui03, Flora Tao, FLRNKS, fornaix, fuyli, George, Giacomo Gamba, GitHub, godfrey he, GuoWei Ma, Gyula Fora, hackergin, hameizi, Haoyuan Ge, Harshvardhan Chauhan, Haseeb Asif, hehuiyuan, huangxiao, HuangXiao, huangxingbo, HuangXingBo, humengyu2012, huzekang, Hwanju Kim, Ingo Bürk, I. Raleigh, Ivan, iyupeng, Jack, Jane, Jark Wu, Jerry Wang, Jiangjie (Becket) Qin, JiangXin, Jiayi Liao, JieFang.He, Jie Wang, jinfeng, Jingsong Lee, JingsongLi, Jing Zhang, Joao Boto, JohnTeslaa, Jun Qin, kanata163, kevin.cyj, KevinyhZou, Kezhu Wang, klion26, Kostas Kloudas, kougazhang, Kurt Young, laughing, legendtkl, leiqiang, Leonard Xu, liaojiayi, Lijie Wang, liming.1018, lincoln lee, lincoln-lil, liushouwei, liuyufei, LM Kang, lometheus, luyb, Lyn Zhang, Maciej Obuchowski, Maciek Próchniak, mans2singh, Marek Sabo, Matthias Pohl, meijie, Mika Naylor, Miklos Gergely, Mohit Paliwal, Moritz Manner, morsapaes, Mulan, Nico Kruber, openopen2, paul8263, Paul Lam, Peidian li, pengkangjing, Peter Huang, Piotr Nowojski, Qinghui Xu, Qingsheng Ren, Raghav Kumar Gautam, Rainie Li, Ricky Burnett, Rion Williams, Robert Metzger, Roc Marshal, Roman, Roman Khachatryan, Ruguo, Ruguo Yu, Rui Li, Sebastian Liu, Seth Wiesman, sharkdtu, sharkdtu(涂小刚), Shengkai, shizhengchao, shouweikun, Shuo Cheng, simenliuxing, SteNicholas, Stephan Ewen, Suo Lu, sv3ndk, Svend Vanderveken, taox, Terry Wang, Thelgis Kotsos, Thesharing, Thomas Weise, Till Rohrmann, Timo Walther, Ting Sun, totoro, totorooo, TsReaper, Tzu-Li (Gordon) Tai, V1ncentzzZ, vthinkxie, wangfeifan, wangpeibin, wangyang0918, wangyemao-github, Wei Zhong, Wenlong Lyu, wineandcheeze, wjc, xiaoHoly, Xintong Song, xixingya, xmarker, Xue Wang, Yadong Xie, yangsanity, Yangze Guo, Yao Zhang, Yuan Mei, yulei0824, Yu Li, Yun Gao, Yun Tang, yuruguo, yushujun, Yuval Itzchakov, yuzhao.cyz, zck, zhangjunfan, zhangzhengqi3, zhao_wei_nan, zhaown, zhaoxing, Zhenghua Gao, Zhenqiu Huang, zhisheng, zhongqishang, zhushang, zhuxiaoshang, Zhu Zhu, zjuwangg, zoucao, zoudan, 左元, 星, 肖佳文, 龙三