Apache Flink Table Store 0.1.0 Release Announcement
May 11, 2022 - Jingsong Lee Jiangjie (Becket) QinThe Apache Flink community is pleased to announce the preview release of the Apache Flink Table Store (0.1.0).
Please check out the full documentation for detailed information and user guides.
Note: Flink Table Store is still in beta status and undergoing rapid development. We do not recommend that you use it directly in a production environment.
What is Flink Table Store #
In the past years, thanks to our numerous contributors and users, Apache Flink has established itself as one of the best distributed computing engines, especially for stateful stream processing at large scale. However, there are still a few challenges people are facing when they try to obtain insights from their data in real-time. Among these challenges, one prominent problem is lack of storage that caters to all the computing patterns.
As of now it is quite common that people deploy a few storage systems to work with Flink for different purposes. A typical setup is a message queue for stream processing, a scannable file system / object store for batch processing and ad-hoc queries, and a K-V store for lookups. Such an architecture posts challenge in data quality and system maintenance, due to its complexity and heterogeneity. This is becoming a major issue that hurts the end-to-end user experience of streaming and batch unification brought by Apache Flink.
The goal of Flink table store is to address the above issues. This is an important step of the project. It extends Flink’s capability from computing to the storage domain. So we can provide a better end-to-end experience to the users.
Flink Table Store aims to provide a unified storage abstraction, so users don’t have to build the hybrid storage by themselves. More specifically, Table Store offers the following core capabilities:
- Support storage of large datasets and allows read / write in both batch and streaming manner.
- Support streaming queries with minimum latency down to milliseconds.
- Support Batch/OLAP queries with minimum latency down to the second level.
- Support incremental snapshots for stream consumption by default. So users don’t need to solve the problem of combining different stores by themselves.
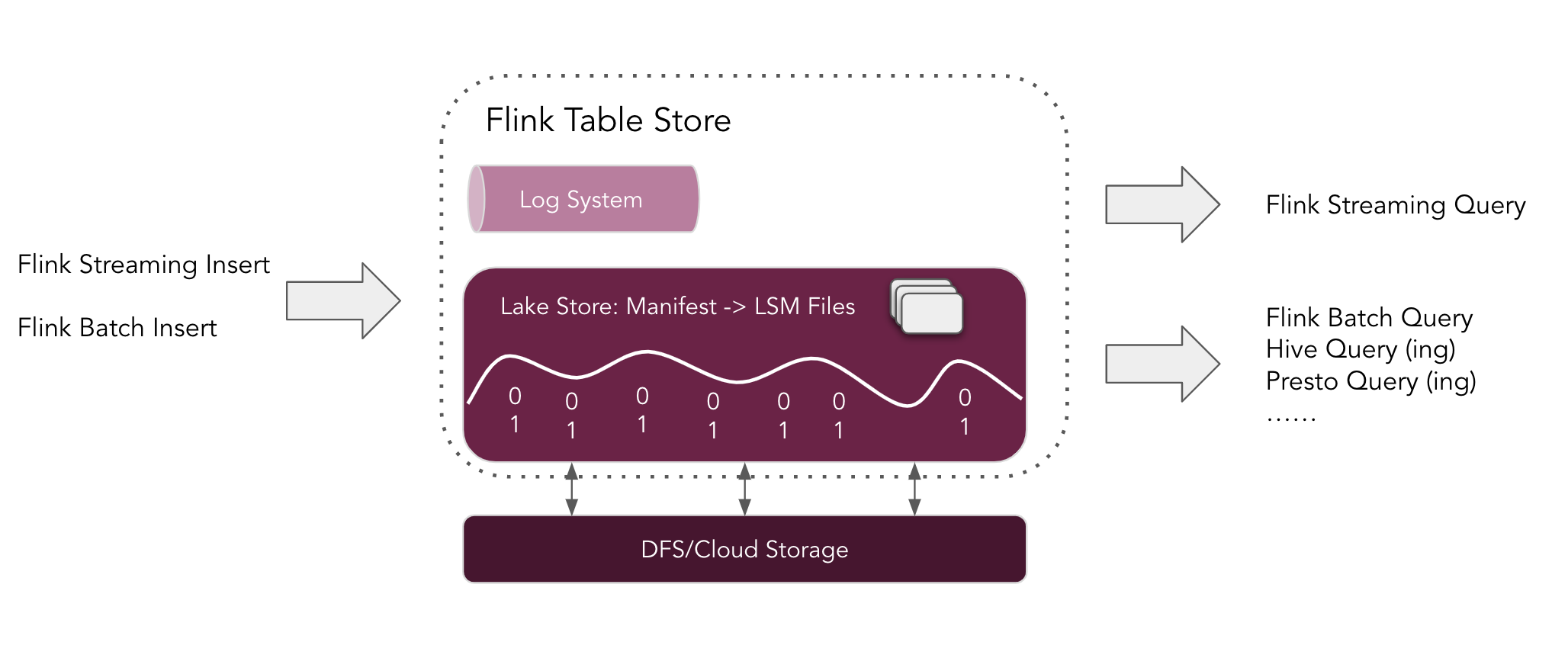
In this preview version, as shown in the architecture above:
- Users can use Flink to insert data into the Table Store, either by streaming the change log captured from databases, or by loading the data in batches from the other stores like data warehouses.
- Users can use Flink to query the table store in different ways, including streaming queries and Batch/OLAP queries. It is also worth noting that users can use other engines such as Apache Hive to query from the table store as well.
- Under the hood, table Store uses a hybrid storage architecture, using a Lake Store to store historical data and a Queue system (Apache Kafka integration is currently supported) to store incremental data. It provides incremental snapshots for hybrid streaming reads.
- Table Store’s Lake Store stores data as columnar files on file system / object store, and uses the LSM Structure to support a large amount of data updates and high-performance queries.
Many thanks for the inspiration of the following systems: Apache Iceberg and RocksDB.
Getting started #
Please refer to the getting started guide for more details.
What’s Next? #
The community is currently working on hardening the core logic, stabilizing the storage format and adding the remaining bits for making the Flink Table Store production-ready.
In the upcoming 0.2.0 release you can expect (at-least) the following additional features:
- Ecosystem: Support Flink Table Store Reader for Apache Hive Engine
- Core: Support the adjustment of the number of Bucket
- Core: Support for Append Only Data, Table Store is not just limited to update scenarios
- Core: Full Schema Evolution
- Improvements based on feedback from the preview release
In the medium term, you can also expect:
- Ecosystem: Support Flink Table Store Reader for Trino, PrestoDB and Apache Spark
- Flink Table Store Service to accelerate updates and improve query performance
Please give the preview release a try, share your feedback on the Flink mailing list and contribute to the project!
Release Resources #
The source artifacts and binaries are now available on the updated Downloads page of the Flink website.
We encourage you to download the release and share your feedback with the community through the Flink mailing lists or JIRA.
List of Contributors #
The Apache Flink community would like to thank every one of the contributors that have made this release possible:
Jane Chan, Jiangjie (Becket) Qin, Jingsong Lee, Leonard Xu, Nicholas Jiang, Shen Zhu, tsreaper, Yubin Li